1.准备工作
1.ZooKeeper集群安装:如不了解 ZooKeeper 的安装,请点击链接了解:ZooKeeper集群的安装
2.Kafka集群安装:如不了解Kafka的安装,请点击链接了解:Kafka集群的安装
学习 Flink 整合 Kafka 。1.首先需要先查看是否安装 Kafka集群。Kafka 又需要 ZooKeeper 的支持,通过 ZooKeeper 来完成 Kafka 集群的高可用.2.其次需要查看是否已经安装ZooKeeper集群
为了保证 Exactly-Once,此处建议使用 Kafka 1.0.0 以上版本。最低版本也需要是 0.11.x。版本如果再低的话,就无法保证 Exactly-Once 了
如果您还没有安装 ZooKeeper 集群 和 Kafka 集群的话,请先参考以上链接来安装。安装完成之后,我们再来学习 Flink 是如何整合 Kafka 来消费信息的。
附:本文 ZooKeeper集群、Kafka集群均安装在 192.168.204.210~192.168.204.212 三台机器上
2.官方文档
附件:Flink整合 Kafka ,我是官方文档(英文版)
3.Flink 整合 Kafka
3.1 加入Maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.1</version>
</dependency>
3.2 编写程序,消费Kafka信息
/**
* TODO 从 Kafka 中读取数据
* 是可以并行的Source,并且可以实现 Exactly-Once
* @author liuzebiao
* @Date 2020-2-5 18:29
*/
public class KafkaSource {
public static void main(String[] args) throws Exception {
//1.创建 Flink 实时环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Kafka props
Properties properties = new Properties();
//指定Kafka的Broker地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.204.210:9092,192.168.204.211:9092,192.168.204.212:9092");
//指定组ID
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "flinkDemoGroup");
//如果没有记录偏移量,第一次从最开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer("flink_demo", new SimpleStringSchema(), properties);
//2.通过addSource()方式,创建 Kafka DataStream
DataStreamSource<String> kafkaDataStream = env.addSource(kafkaSource);
//3.Sink (此处不作操作,直接输出到控制台)
kafkaDataStream.print();
//4.执行任务
env.execute("KafkaSource");
}
}
3.3 集群启动
启动集群需要注意先后顺序。首先需要启动 ZooKeeper 集群,然后再启动 Kafka 集群。
集群的启动方式,请参考以下链接:ZooKeeper集群的安装、Kafka集群的安装(链接中有ZooKeeper、Kafka集群的启动方式)
3.4 测试
3.4.1 Kafka创建一个Topic
创建 Topic 命令如下:
bin/kafka-topics.sh --create --zookeeper
192.168.204.210:2181,192.168.204.211:2181,192.168.204.212:2181 --replication-factor 1 --partitions 3 --topic flink_demo
解析:
bin/kafka-topics.sh --create ---->kafka自带命令 --create表示创建 topic
--zookeeper xxx.xxx.xxx.xxx:2181 ---->zookeeper 集群地址
--replication-factor 1 ---->备份数(1个备份)
--partitions 3 ---->kafka分区数(表示分了3个分区)
--topic flink_demo---->要创建的 topic 的名称
3.4.2 写入数据到 Kafka
在此处,我们使用命令的方式,向Kafka集群中的某一台中写入一些消息(本文向192.168.204.210节点Kafka写入数据)。命令如下:
bin/kafka-console-producer.sh --broker-list 192.168.204.210:9092 --topic flink_demo
3.4.3 启动 Flink 程序,消费 Kafka消息
通过 右键 或者 Ctrl+Shift+F10 快捷键的方式,启动测试程序。
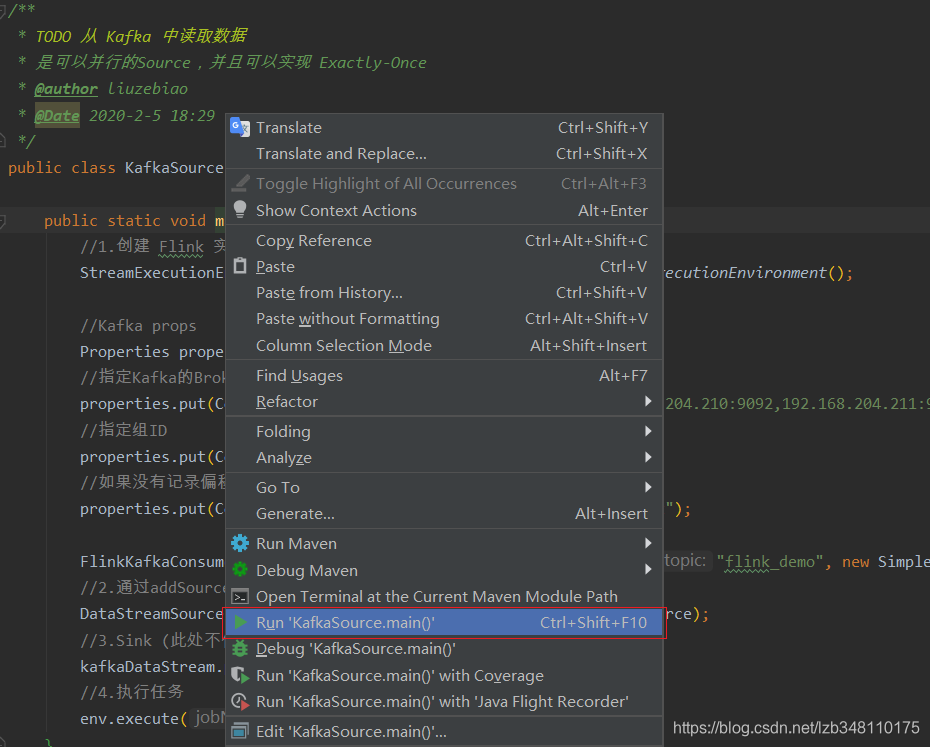
3.4.4 测试结果
如下动图所示:1.我们通过命令行的方式写入消息到 Kafka 2.Flink 测试程序便会将消息实时消费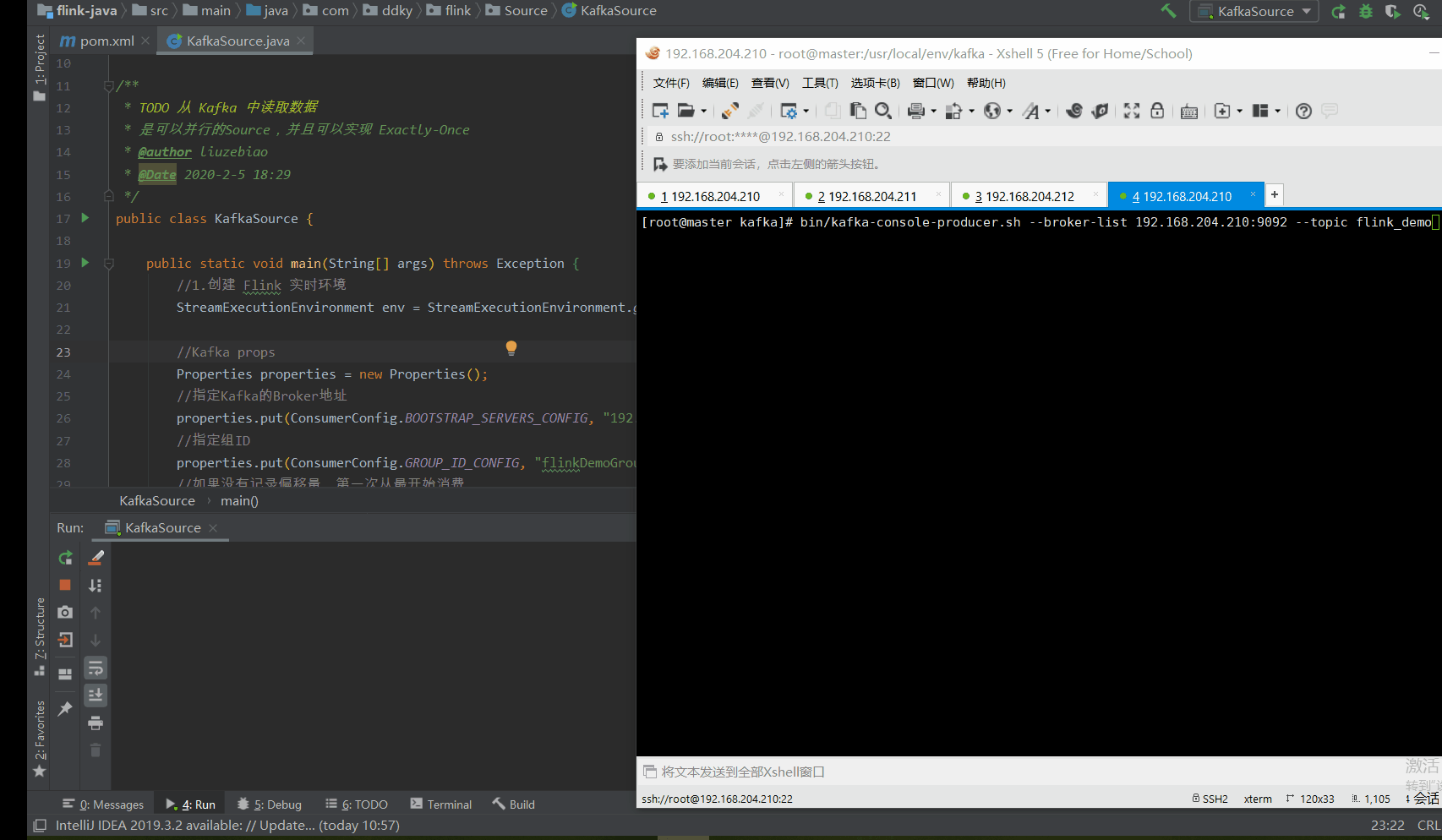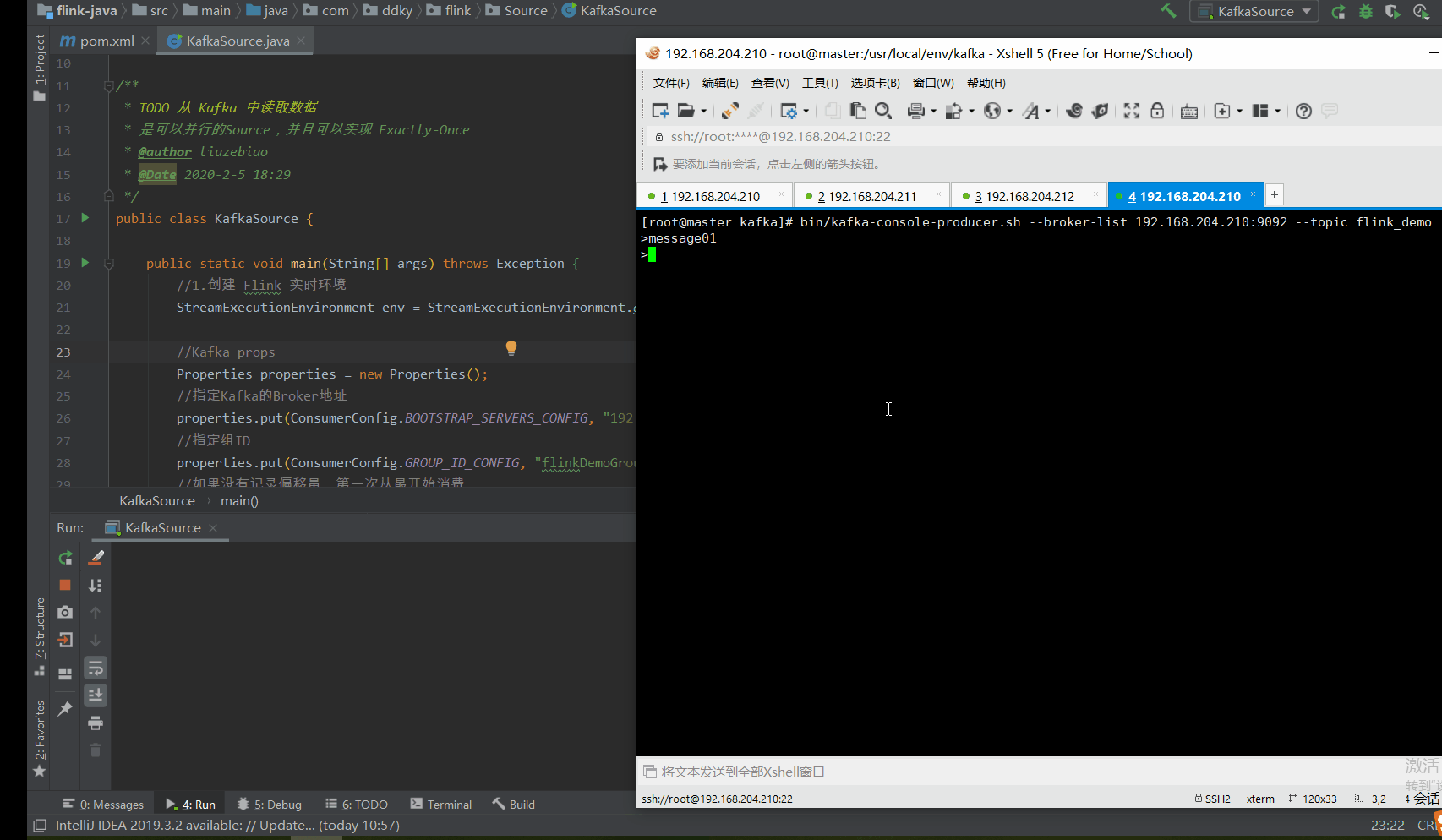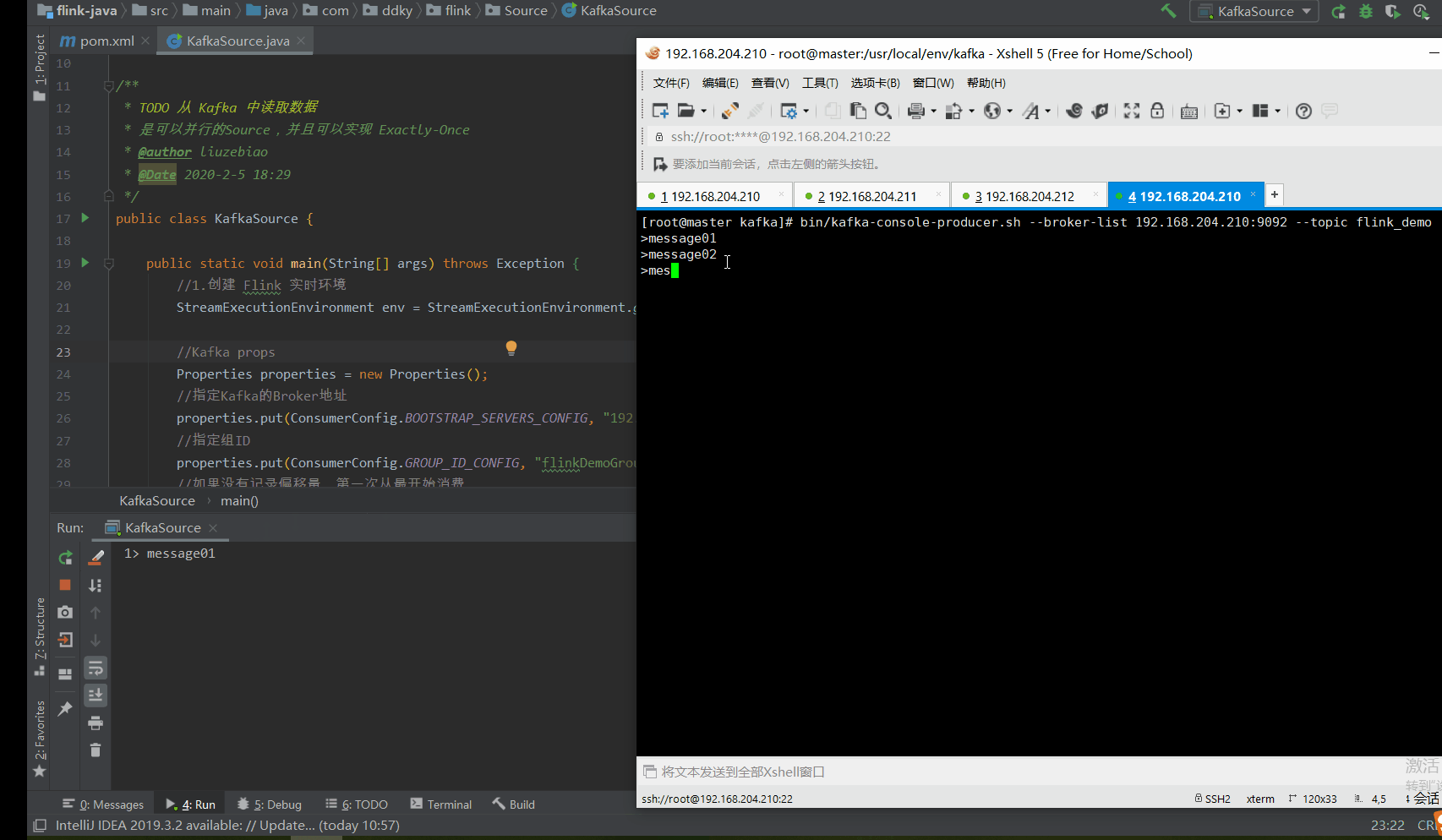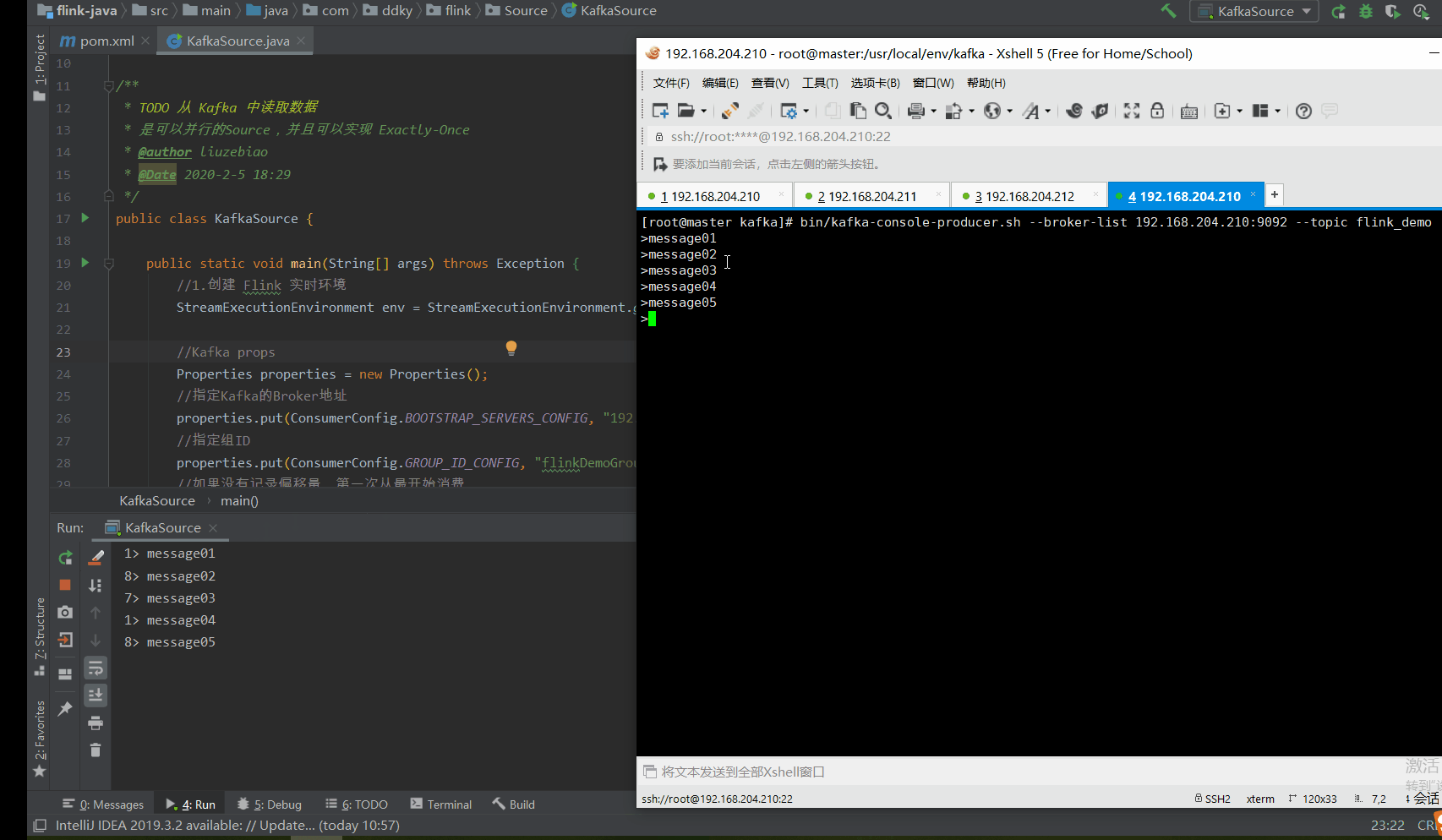
Flink 整合 Kafka,介绍到此为止
如果本文对你有所帮助,那就给我点个赞呗 O(∩_∩)O
End
