这篇文章总结一些递归常见的优化方法
以题目来说,leetcode 106,已知中序和后序遍历,构造二叉树
方法一:传入数组为参数
#中序遍历 左 根 右
#后序遍历 左 右 根
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
n=len(inorder)
if n==0:
return None
if n==1:
return TreeNode(inorder[0])
#后序遍历的最后一个是根
root=TreeNode(postorder[-1])
for i in range(n):
if inorder[i]==root.val:
break;
root.left=self.buildTree(inorder[:i],postorder[:i])
root.right=self.buildTree(inorder[i+1:],postorder[i:-1])
return root
方法一优化后
其实就加了两个优化
1.用哈希表存储索引 不需要每次都O(n)的搜索 只要O(1)
2.传参数不传数组了,每次只传入四个int型的变量
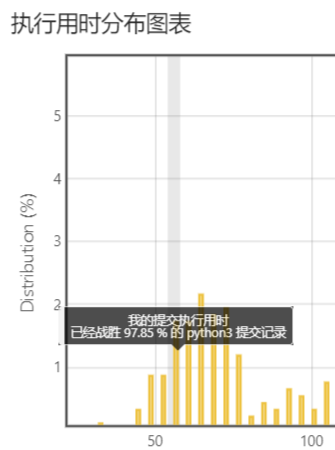
没想到结果快了10倍
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
def helper(in_left,in_right,post_left,post_right):
if in_left>in_right or post_left>post_right:
return None
if in_left==in_right:
return TreeNode(inorder[in_left])
root=TreeNode(postorder[post_right])
#通过hash表存储 不要反复查找
i=hashmap[root.val]
k=i-1+post_left-in_left
root.left=helper(in_left,i-1,post_left,k)
root.right=helper(i+1,in_right,k+1,post_right-1)
return root
#优化方法 把中序遍历的值放在hash表中
#一种很帅的字典生成方法
hashmap={element:i for i,element in enumerate(inorder)}
if len(inorder)==0:
return None
return helper(0,len(inorder)-1,0,len(postorder)-1)
最后留下了一个疑问:到底是hashmap优化加速快还是传参问题?暂时没想出来
今天递归犯了一个很蠢的错误 debug至少半个小时…
这个该死的return没写 导致这一小段递归没有返回值 而且一直没发现…吐血
if tmpSum==avg:
return dfs(k-1,0,0) #重新返回最初的起点 开始凑
这个凑子集不反转要超时 就这一句话
#不加revese要超时
nums.sort(reverse=True)
