无聊医生玩python
爬取分析2020肺炎官方数据
说明:本文数据都来自官方发布内容,由于春节期间电脑不在手边,本人是医生,开始几天很忙,动手有点晚了,前面一些天数据有些没有统计全。
数据下载
1 爬虫代码
本来一回来想好好写个爬虫的,后来发现很容易找到了数据接口。直接下载json就是了。每天备份一份,留作后期分析。我写的时候用了scrapy,其实没必要,主要是scrapy里面有现成的文档及数据库管道,省许多事。写这篇前我把他们都拷贝出来整理成.py文件了。
from datetime import date
import re
import requests
# from lxml import etree
def request_handle(url):
'''发送请求'''
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 Edg/79.0.309.71'}
r = requests.get(url, headers = headers, timeout= 5)
coding = r.apparent_encoding
r.encoding = coding
return r
def parse_area(text):
'''正则解析提取文件'''
pattern = re.compile(r'<script id="getAreaStat">try (.*?)</script>')
area = pattern.findall(text)[0].replace('{ window.getAreaStat = ','').replace(r'}catch(e){}','')
return area
def parse_country(text):
'''正则解析提取文件'''
pattern = re.compile(r'<script id="getListByCountryTypeService2">try (.*?)</script>')
country = pattern.findall(text)[0].replace('{ window.getListByCountryTypeService2 = ','').replace(r'}catch(e){}','')
return country
def creatfile(path,string):
with open(path,'w') as f:
f.write(string)
def main():
url = (
'https://ncov.dxy.cn/ncovh5/view/pneumonia_peopleapp',#丁香园数据
'https://server.toolbon.com/home/tools/getPneumonia',#疫情数据接口
)
r = request_handle(url[0])
area = parse_area(r.text)
path_area = f'./txt/yiqing/[{date.today()}]yiqing_area.json'
creatfile(path_area, area)
country = parse_country(r.text)
path_country = f'./txt/yiqing/[{date.today()}]yiqing_country.json'
creatfile(path_country, country)
r = request_handle(url[1])
path_full = f'./txt/yiqing/[{date.today()}]yiqing_full.json'
creatfile(path_full, r.text)
if __name__ == '__main__':
main()
看下json吧,数据很全

多爬了一个丁香园是担心各网站数据不同,留作比对,后来发现没啥区别。又写了下面的直接把数据放在mysql上了。
第二段代码
import json
import requests
import pymysql
import time
def request_handle(url):
'''发送请求'''
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36 Edg/79.0.309.71'}
r = requests.get(url, headers = headers, timeout= 5)
coding = r.apparent_encoding
r.encoding = 'utf8'
return r
def parse_china_item(response):
'''解析提取文件'''
rdict = json.loads(response.text)
return rdict['data']['statistics']
def insert_mysql(item):
db = pymysql.connect('localhost', usename, password, dbname)
cursor = db.cursor()
sql = '''INSERT INTO tablename(
date,
suspectedCount,
confirmedCount,
curedCount,
deadCount,
seriousCount,
suspectedIncr,
confirmedIncr,
curedIncr,
deadIncr,
seriousIncr
) VALUES('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')''' %(
item['modifyTime'],
item['suspectedCount'],
item['confirmedCount'],
item['curedCount'],
item['deadCount'],
item['seriousCount'],
item['suspectedIncr'],
item['confirmedIncr'],
item['curedIncr'],
item['deadIncr'],
item['seriousIncr']
)
try:
cursor.execute(sql)
db.commit()
print('---------------写入MySQL成功------------')
except:
rollback()
print('---------------写入MySQL不成功------------')
db.close()
def main():
'''下载解析相关数据,存入mysql'''
url = 'https://server.toolbon.com/home/tools/getPneumonia'
r = request_handle(url)
item = parse_china_item(r)
#对timeArray进行格式转换
timeArray = time.localtime(item.get('modifyTime')/1000)
item['modifyTime']= time.strftime("%Y-%m-%d", timeArray)
insert_mysql(item)
if __name__ == '__main__':
main()
看下效果
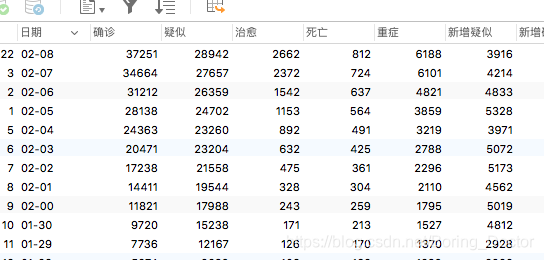
数据分析
分析主要在jupyter上做的,做了好多尝试,没得出什么乐观的结论。拿一段代码看看吧。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def xiantu1(df,x1,y1,x2,y2,title):
'''绘制双线图'''
#对plt进行设置,避免中文乱码,注意Mac可用的字体是Arial Unicode MS
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(14,8))
plt.plot(x1, y1,'o-',linewidth =3)
plt.plot(x2, y2,'o-',linewidth =3)
# plt.axis([0,34000])
plt.title(title,fontsize = 20)
#设置坐标轴名称
plt.xlabel('日期',fontsize=18)
plt.ylabel('人数',fontsize =18)
plt.tick_params(labelsize = 10)#轴数据字体大小
plt.xticks(rotation=-30)#旋转x轴上文字角度
# plt.grid()#网格线
# 设置数字标签
for a, b in zip(x1, y1):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
for a, b in zip(x2, y2):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.legend()#图例
plt.show()
def main():
df = pd.read_csv ('/users/mac/downloads/yiqing_view.csv')
x1,y1 = df.日期, df.确诊
x2,y2 = df.日期, df.疑似
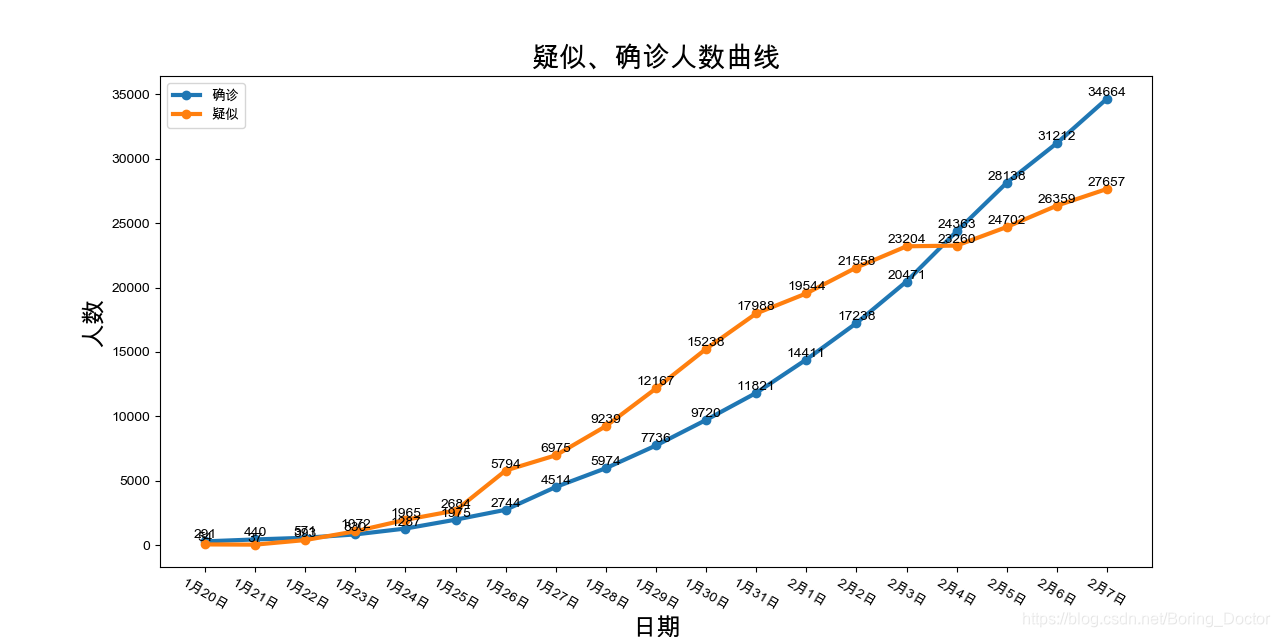
title = '疑似、确诊人数曲线'
xiantu1(df,x1,y1,x2,y2,title)
if __name__ == '__main__':
main()
看下效果
还有其他的:
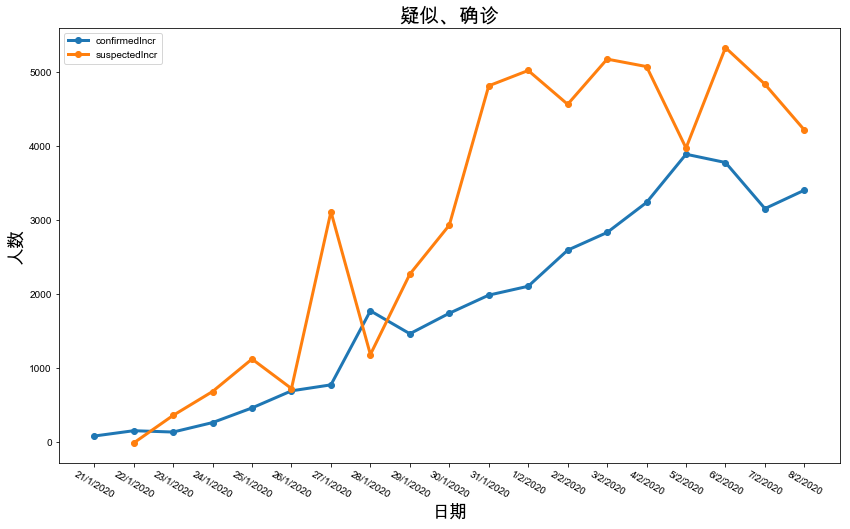
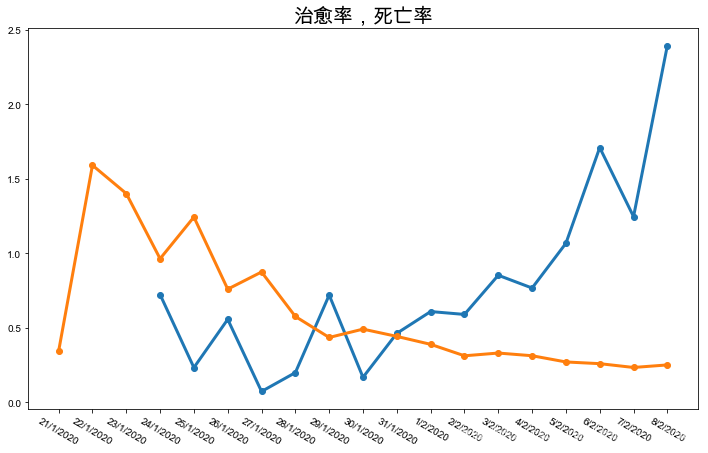
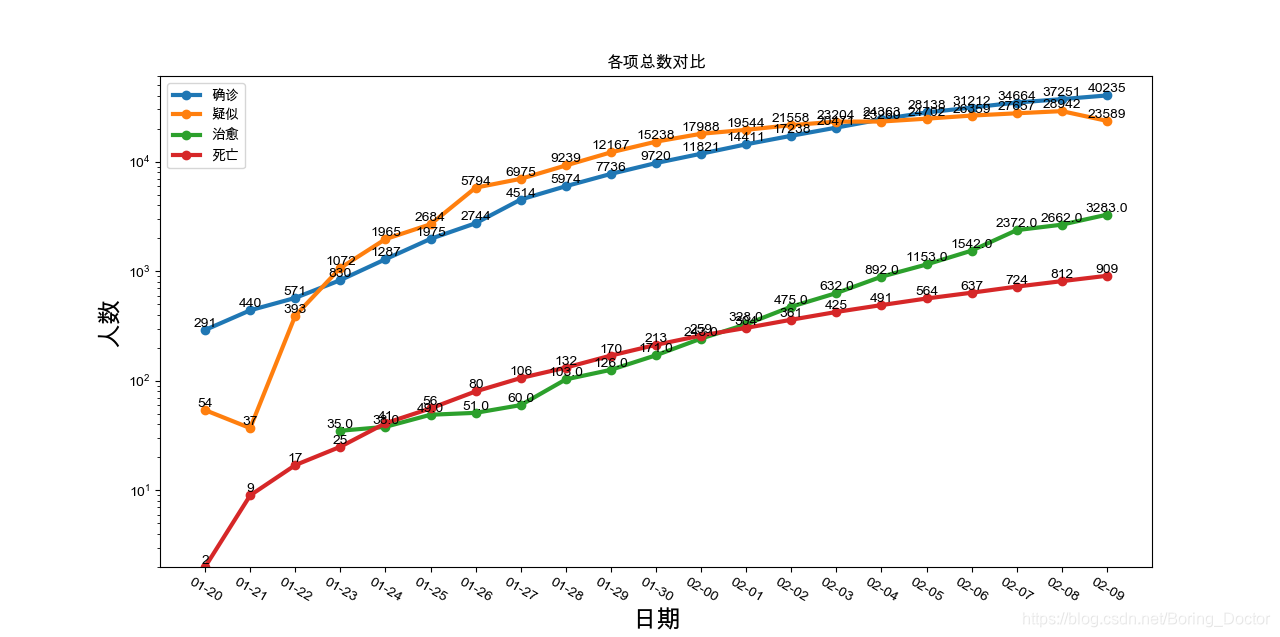
y轴用log更能表现传染性的变化
总结
还做了许多其他的分析,还有各省的,由于动手晚了,只拿到近几天的数据,很遗憾,如果谁有,可以发给我。
