0904-各区域Top3商品统计
需求六: 各区域Top3商品统计
6.1 需求概述
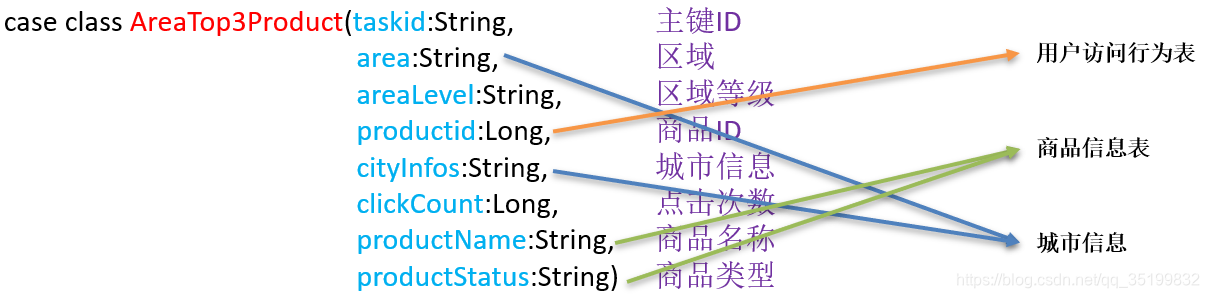
统计各个区域中Top3的热门商品,热门商品的评判指标是商品被点击的次数,对于user_visit_action表,click_product_id表示被点击的商品。
- 用到的表
- 用户访问行为表

- 商品信息表

- 城市信息

- 结果数据
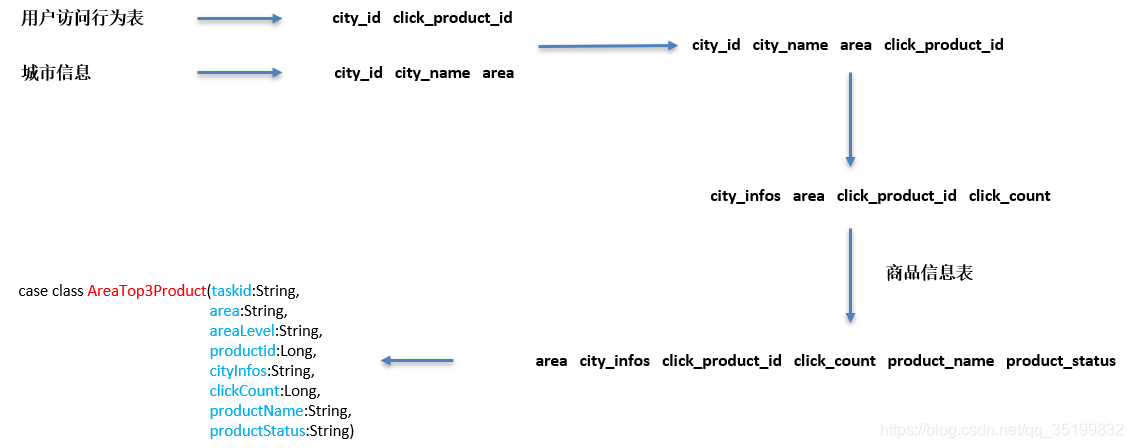
5.2 简要运行流程
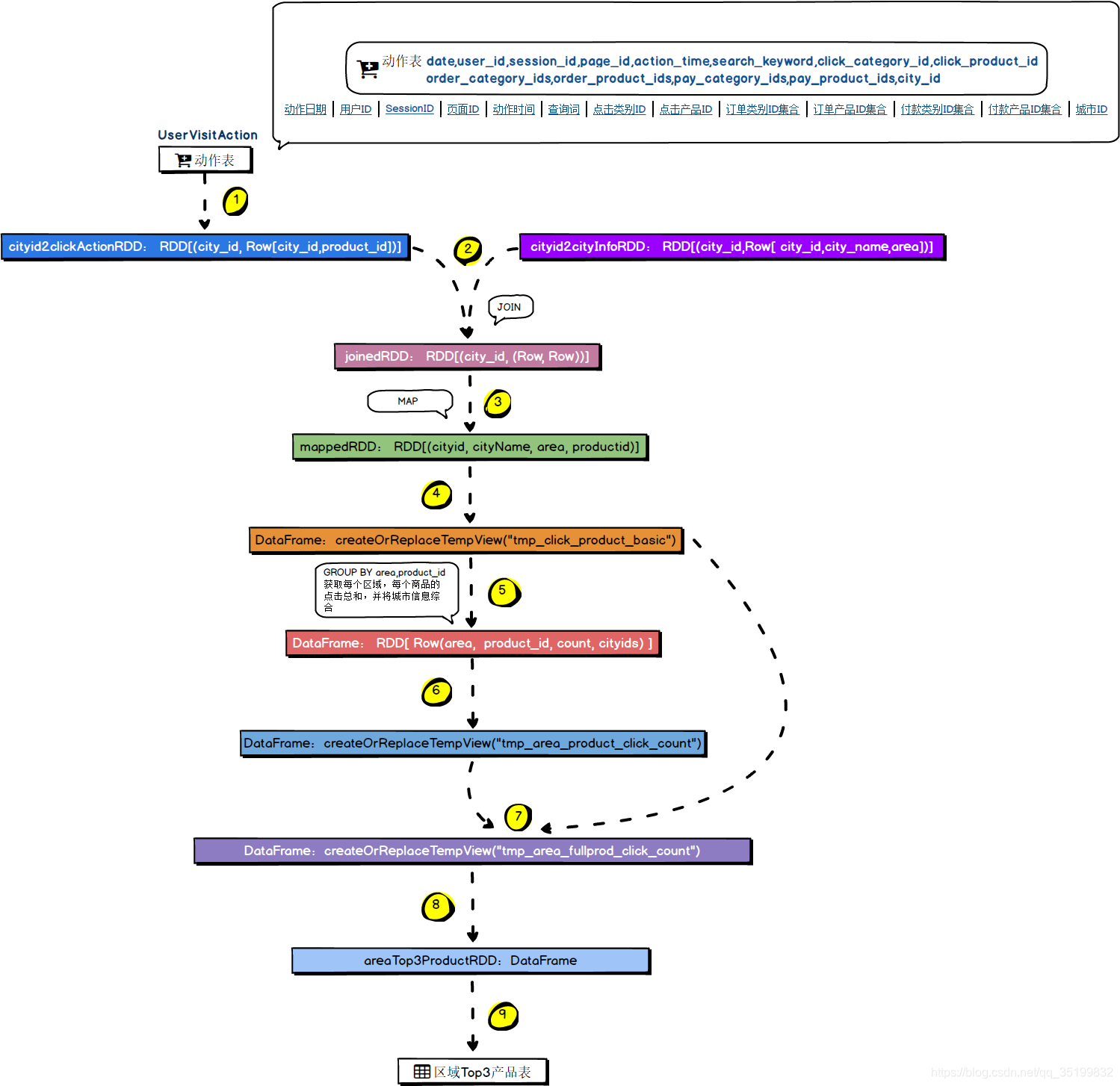
5.3 具体运行流程
- 从用户行为表里拿到城市id和点击商品id, 并以城市ID为key,用于和城市信息进行join操作
- join后转化结构,指定个字段的类型
- 创建基本数据表 (city_id, city_name, area, product_id)
- GROUP BY area,product_id 获取每个区域,每个商品的点击总和,并通过自定义函数的方式将城市信息综合
- 丰富表的内容 , 加入其它信息(商品状态,区域等级.商品名称)
- 窗口函数, 获取分组Top3
- 封装case class
- 入库
5.4 代码实现
5.4.1 获取数据
// 1. 获取数据
// RDD[(cityId, pid)]
val cityId2PidRDD: RDD[(Long, Long)] = getCityAndProductInfo(sparkSession, taskParams)
// RDD[(cityId, CityAreaInfo)]
val cityId2AreaInfoRDD = getCityAreaInfo(sparkSession)
def getCityAndProductInfo(sparkSession: SparkSession, taskParams: JSONObject) = {
val startDate = ParamUtils.getParam(taskParams, Constants.PARAM_START_DATE)
val endDate = ParamUtils.getParam(taskParams, Constants.PARAM_END_DATE)
// 只获取发生过点击的action的数据
// 获取到的一条action数据就代表一个点击行为
val sql = "select city_id, click_product_id from user_visit_action where date>='" + startDate +
"' and date<='" + endDate + "' and click_product_id != -1"
import sparkSession.implicits._
val cityId2PidRDD: RDD[(Long, Long)] = sparkSession.sql(sql)
.as[CityClickProduct]
.rdd
.map {
case (cityClickProduct) =>
(cityClickProduct.city_id, cityClickProduct.click_product_id)
}
cityId2PidRDD
}
def getCityAreaInfo(sparkSession: SparkSession) = {
val cityAreaInfoArray = Array(
(0L, "北京", "华北"),
(1L, "上海", "华东"),
(2L, "南京", "华东"),
(3L, "广州", "华南"),
(4L, "三亚", "华南"),
(5L, "武汉", "华中"),
(6L, "长沙", "华中"),
(7L, "西安", "西北"),
(8L, "成都", "西南"),
(9L, "哈尔滨", "东北")
)
val cityId2AreaInfoRDD: RDD[(Long, CityAreaInfo)] = sparkSession.sparkContext
.makeRDD(cityAreaInfoArray)
.map {
case (cityId, cityName, area) =>
(cityId, CityAreaInfo(cityId, cityName, area))
}
cityId2AreaInfoRDD
}
5.4.2 Join得到基本表信息
// 2. Join得到基本表信息
val areaPidBasicInfoRDD: RDD[(Long, String, String, Long)] = cityId2PidRDD
.join(cityId2AreaInfoRDD)
.map {
case (cityId, (pid, areaInfo)) =>
(cityId, areaInfo.city_name, areaInfo.area, pid)
}
import sparkSession.implicits._
areaPidBasicInfoRDD.toDF("city_id", "city_name", "area", "pid")
.createOrReplaceTempView("tmp_area_basic_info")
5.4.3 获取每个区域,每个商品的点击总和,并将城市信息综合
// 3. group by ;获取每个区域,每个商品的点击总和,并将城市信息综合
// DataFrame:createOrReplaceTempView("tmp_area_product_click_count")
// 3.1 自定义UDF函数 concat_long_string: 将city_id 和 city_name 进行拼接
sparkSession.udf.register("concat_long_string", (v1: Long, v2: String, split: String) => {
v1 + split + v2
})
// 3.2 自定义UDAF函数 group_concat_distinct, 将一个区域里的city信息进行聚合
sparkSession.udf.register("group_concat_distinct", new GroupConcatDistinct)
// 3.3 group by
val sql = "select area, pid, count(*) click_count, " +
"group_concat_distinct(concat_long_string(city_id, city_name, ':')) city_infos " +
"from tmp_area_basic_info group by area, pid"
sparkSession.sql(sql).createOrReplaceTempView("tmp_area_click_count")
- UDAF函数
package com.lz.area
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, StringType, StructType}
class GroupConcatDistinct extends UserDefinedAggregateFunction {
override def inputSchema: StructType = {
new StructType().add("cityInfo", StringType)
}
override def bufferSchema: StructType = {
new StructType().add("bufferCityInfo", StringType)
}
override def dataType: DataType = StringType
override def deterministic: Boolean = true
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = ""
}
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
var bufferCityInfo = buffer.getString(0)
val cityInfo = input.getString(0)
if (!bufferCityInfo.contains(cityInfo)) {
if ("".equals(bufferCityInfo)) {
bufferCityInfo += cityInfo
} else {
bufferCityInfo += "," + cityInfo
}
buffer.update(0, bufferCityInfo)
}
}
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// bufferCityInfo1: cityId1:cityName1, cityId2:cityName2
var bufferCityInfo1 = buffer1.getString(0)
// bufferCityInfo2: cityId1:cityName1, cityId2:cityName2
val bufferCityInfo2 = buffer2.getString(0)
for (cityInfo <- bufferCityInfo2.split(",")) {
if (!bufferCityInfo1.contains(cityInfo)) {
if ("".equals(bufferCityInfo1)) {
bufferCityInfo1 += cityInfo
} else {
bufferCityInfo1 += "," + cityInfo
}
}
}
buffer1.update(0, bufferCityInfo1)
}
override def evaluate(buffer: Row): Any = {
buffer.getString(0)
}
}
5.4.4 加入其它字段
// 4. 丰富tmp_area_click_count 的内容,加入其它字段
// tmp_area_click_count: area, city_infos, pid, click_count tacc
// product_info: product_id, product_name, extend_info pi
sparkSession.udf.register("get_json_field", (json: String, field: String) => {
val jsonObject = JSONObject.fromObject(json)
jsonObject.getString(field)
})
val sql2 = "select tacc.area, tacc.city_infos, tacc.pid, pi.product_name," +
"if(get_json_field(pi.extend_info, 'product_status')='0','Self','Third Party') product_status," +
"tacc.click_count " +
"from tmp_area_click_count tacc join product_info pi on tacc.pid = pi.product_id"
sparkSession.sql(sql2).createOrReplaceTempView("tmp_area_count_product_info")
sparkSession.sql(sql2).show()
5.4.5 获取top3
// 5. 获取top3
val sql3 = "select area, " +
"CASE " +
"WHEN area='华北' OR area='华东' THEN 'A_Level' " +
"WHEN area='华中' OR area='华南' THEN 'B_Level' " +
"WHEN area='西南' OR area='西北' THEN 'C_Level' " +
"ELSE 'D_Level' " +
"END area_level," +
"city_infos, pid, product_name, product_status, click_count from (" +
"select area, city_infos, pid, product_name, product_status, click_count, " +
"row_number() over(PARTITION BY area ORDER BY click_count DESC) rank " +
"from tmp_area_count_product_info) t where rank <=3"
val top3ProductDF: DataFrame = sparkSession.sql(sql3)
5.4.6 封装case class
// 6. 封装case class
val top3ProductRDD: RDD[AreaTop3Product] = top3ProductDF.rdd.map {
case (row) =>
AreaTop3Product(
taskId
, row.getAs[String]("area")
, row.getAs[String]("area_level")
, row.getAs[Long]("pid")
, row.getAs[String]("city_infos")
, row.getAs[Long]("click_count")
, row.getAs[String]("product_name")
, row.getAs[String]("product_status")
)
}
5.4.7 入库
// 7. 入库
top3ProductRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "area_top3_product")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
小结
- UDF
- UDAF
- IF
- CASE…WHEN
- 窗口函数
