原文首发于这里

这几天花了3天时间尝试了一个CCF比赛:大数据时代的Serverless工作负载预测。比赛链接:https://www.datafountain.cn/competitions/468/teams
这里简单记录一下如何利用三天时间进入Top3%,虽然有2000多队伍,很多人其实从来都没有认真做过,三天时间本身就超过80%的人了。所以Top3%,其实真没什么难度,有巨大难度的是Top5,所以标题党了一下。
数据概览
比赛类型为时间序列预测。背景:云计算时代,Serverless软件架构可根据业务工作负载进行弹性资源调整,这种方式可以有效减少资源在空闲期的浪费以及在繁忙期的业务过载,同时给用户带来极致的性价比服务。在弹性资源调度的背后,对工作负载的预测是一个重要环节。云计算,由于提交不同的任务需要调度的计算资源是不同的,为了提前应对,需要计算不同队列未来一段时间需要的资源。
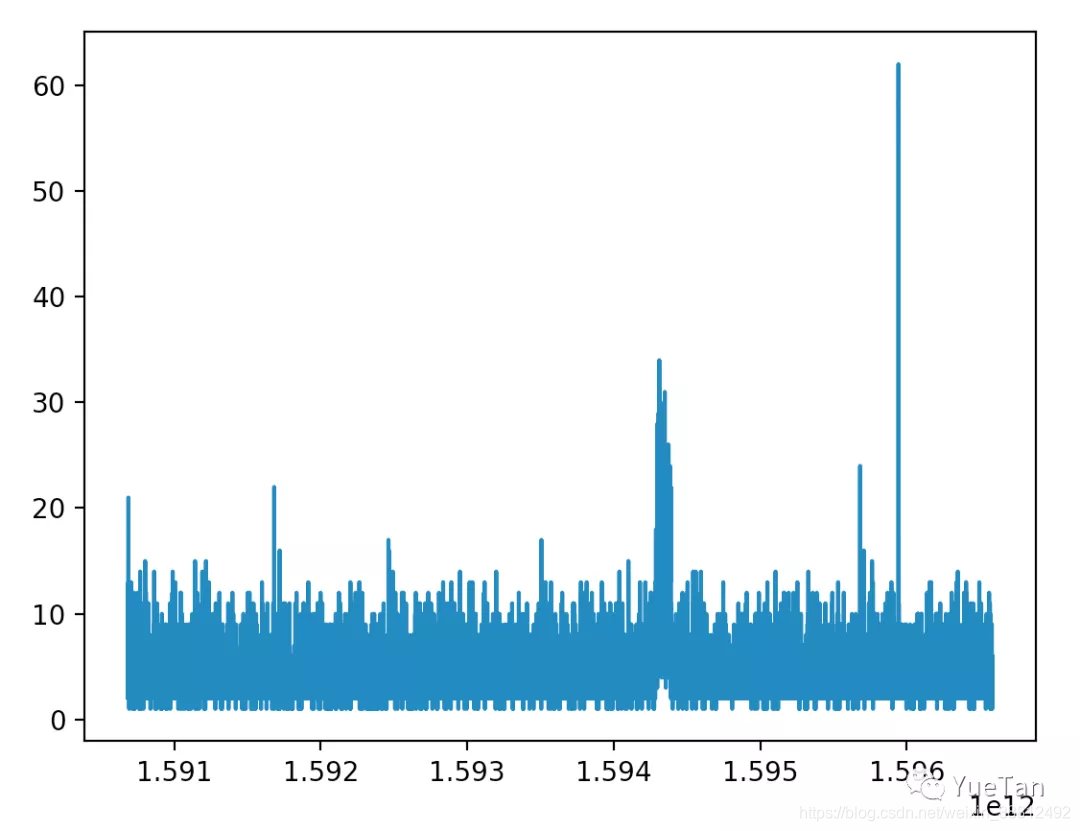
预测任务是不同队列未来5个时间点的CPU的利用率和队列中的Job数。一共有以下队列需要预测
不同队列的趋势确实几乎完全不同,有可能需要针对某些队列额外进行调整
快速baseline
第一步,当然是去GitHub搜索一下baseline。其实baseline的重要性比优化还大多,假如满分是100的话,很多baseline已经做到80了,剩下的20分提升才是慢慢调优。果然找到了一个很强的0.311baseline:https://github.com/siliconx/serverless/blob/main/baseline.ipynb
然后,先花了两天时间,结合baseline看了一下数据,也缓慢的调整到自己熟悉的代码结构里。我所习惯的保存方式是这样:
这里我就花了两天时间了,才算调整跑通一个baseline。所以最后一天才开始提交,而且只有3次提交机会,目标是能跑赢baseline就行了。读baseline时产生的一些优化想法:
- 对ID和时间的认识往往能够提分,比如本题预测的就有同一队列ID不同阶段的预测。可能是采集数据的时候发生了异常,比如说把另一个区域的相同id的队列数据混在了某个队列中,选手需要自己做一些判断哪个是原始的数据。
- 由于xgboost和lightgbm需要损失函数二阶可微,而评价函数是自定义的不可微函数,这里调整好也可以上分。
当然模型融合也是直观简单的,尤其是树模型和深度学习模型的融合。 - 预测目标上可做的文章也很多,比如log变换,差分变换
优化 - 在baseline的基础上进行优化,优化的方向主要有任务、数据、特征、模型(包括不同模型与同一模型的超参数、损失函数等)、验证、后处理等。在时间紧迫而且对数据不熟悉的基础上,自然是要抓住主要矛盾,主要尝试的就是新增特征了。本来应该一开始就熟悉数据的,最后慢悠悠的也没开始看数据。
第三天也就是比赛结束的最后一天下午四点钟,终于第一次提交了一下:

第一次提交的排名是82/ 2392,四舍五入之后可以说自己排名Top3%。前排其实有不少小号队伍,再加上肯定有人比我厉害,随便提交也在我前面。大概可以得出结论,前面真正认真对待比赛的不超过50个队伍。即使认真做,前十也不容易达到,但10-30这个区间只要早早参赛且不放弃的尝试还是可以的。如果再互相组组队,就更有机会了。但是要做好心理准备,时间序列可能大坑,就是最终排行榜会剧烈抖动。
如果是某些传统行业的公司,参加了数据比赛且排名前3%,已经足够写在简历上了。大概,就是能从github上clone下代码并跑通,并修改一下。但是真正几斤几两,自己心里还是要有数的,baseline是0.311,我的提交加了几个特征是0.320,第一的成绩已经到0.4了,差距巨大。
距离最后的提交时间不多了,已经是下午四点钟,还有两次提交机会。第二次准备加更多特征,第三次准备从数据ID上看看做文章,或者尝试新模型了。都这时候了,也不用管本地测试,不用管特征重要性了,就是梭,一把梭哈。万一shake到我的好运了呢,机会只给有准备的人。当然还是希望前面认真分析数据、认真搞特征的人能取得好成绩。
刚开始想特征的时候要大开大合一点,随便加,能想到的都加上试试效果再说。然后再精细一点,慢慢想,且开始思考word的为啥work,不work的为啥不work。这一次我又新增了特征,主要是时间序列特征:例如差值,比值,smooth。特征从89变成154
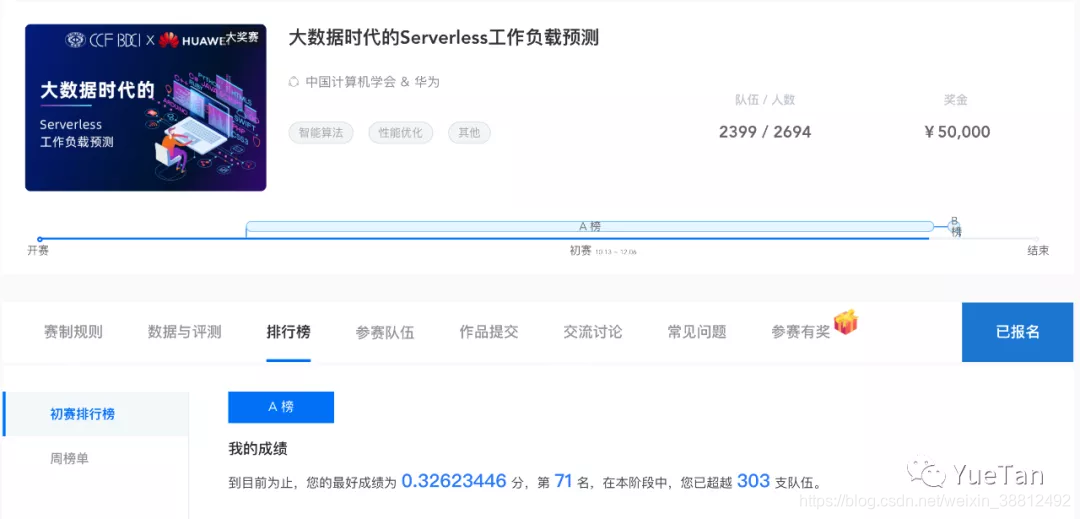
五点的时候再次提交。成绩来到了0.32623446000,排名71/2399,已经是2.959%,可以名正言顺的说自己Top3%了。当然,最后时刻肯定还是瞬息万变的,尤其是这个位次,而且由于赛制的原因,有很多小号去参加评测,而且还很靠前。
还剩最后一次提交了,最后一次提交,突然觉得根据上一次的成绩,搞一个系数,然后直接提交。系数是用来决定趋势的,首先判断是大于1还是小于1,应该根据数据来判断,我也懒得判断了。所以直接给第四天和第五天增加2%,再取整。 竟然也有0.0005的微小提高。不过总排名还是在不断下降的,探榜的小号太多了,总队伍已经2409了。

最终B榜成绩排名51
总结
-
由于是抱着娱乐的心态来参赛,所以完全没有体会到那种跌宕起伏、那种巨大付出之后努力都付之东流的遗憾、那种中学时等待成绩排行时的紧张感,这些心情上的东西都没有体会很深。在年纪越来越大,心情越来越像流水一样,本想借此回顾一下这种心情,没想到知道时间不多而毫无压力了。
-
代码上的收获是大致写了个可复用的时间序列框架,以后如果再遇到多步的时间序列预测,可以很快的调整得以应用到新数据上。不过只写了lightgbm相关,深度学习部分此次没有尝试。
-
特征导入部分分别尝试了从原始数据直接pipeline一把梭的方式,以及每块特征保存为pickle挨个加载这两种方法。
-
时间序列比赛很容易被坑,由于包含外推的预测很可能发生概念漂移,导致以前的规律不准确,排行榜特别容易shake,不建议新人一上来就打时间序列比赛。尤其这次的赛制,有点纵容小号,两者叠加就完全不建议了。
-
由于时间以及能力原因,对数据和特征没有很深的理解。极短时间参赛主要目的其实也是为了把框架性东西以及比赛流程熟悉一下,本次就暂告一段落了。
联系方式
公众号搜索:YueTan