0905-广告点击量实时统计
需求七:实时维护黑名单
7.1 需求概述
从Kafka获取实时数据,对每个用户的点击次数进行累加并写入MySQL,当一天之内一个用户对一个广告的点击次数超过100次时,将用户加入黑名单中。
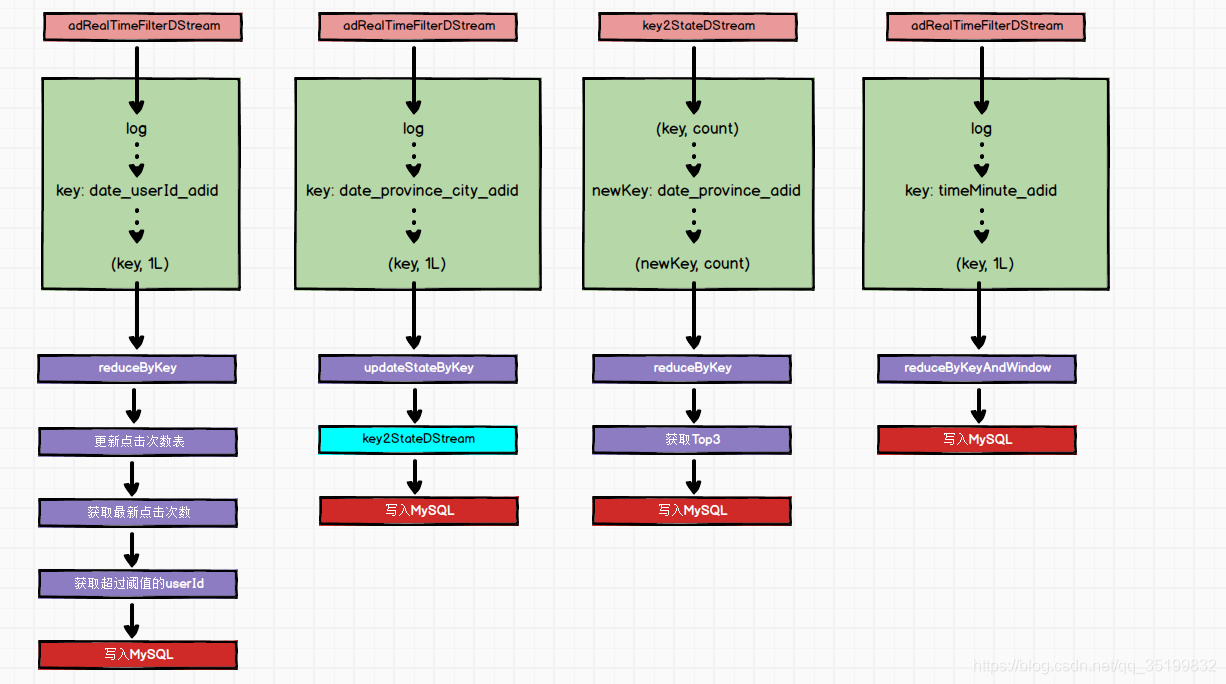
7.2 简要运行流程

- 根据实时获取的数据, 批量更新用户点击次数表
- 更新完之后, 再从表中查出操作异常的用户
- 将操作异常的用户ID加入到黑名单表中
7.3 具体运行流程

7.4 代码实现
7.4.1 加载并转换用户数据集
val sparkConf = new SparkConf().setAppName("adver").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
val streamingContext: StreamingContext = new StreamingContext(sparkSession.sparkContext, Seconds(5))
val kafka_brokers = ConfigurationManager.config.getString(Constants.KAFKA_BROKERS)
val kafka_topics = ConfigurationManager.config.getString(Constants.KAFKA_TOPICS)
// kafka参数配置
val kafkaParam = Map(
"bootstrap.servers" -> kafka_brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group1",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
// auto.offset.reset
// latest: 先去Zookeeper获取offset,如果有,直接使用,如果没有,从最新的数据开始消费;
// earlist: 先去Zookeeper获取offset,如果有,直接使用,如果没有,从最开始的数据开始消费
// none: 先去Zookeeper获取offset,如果有,直接使用,如果没有,直接报错
)
// 消费kafka中的数据
// adRealTimeDStream: DStream[RDD RDD RDD ...] RDD[message] message: key value
val adRealTimeDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
streamingContext,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Array(kafka_topics), kafkaParam)
)
// adRealTimeValueDStream: DStream[RDD RDD RDD...] RDD[String] String : timestamp province city userid adid
val adRealTimeValueDStream: DStream[String] = adRealTimeDStream.map(item => item.value())
7.4.2 过滤掉已经上黑名单的用户
// 从拿到的实时数据中过滤掉黑名单中的用户
// adRealTimeFilterDStream:DStream[RDD RDD RDD...]
// RDD[String]
// String : timestamp province city userid adid
val adRealTimeFilterDStream: DStream[String] = adRealTimeValueDStream.transform {
logRDD =>
val blackLIstArray: Array[AdBlacklist] = AdBlacklistDAO.findAll()
val userIdArray: Array[Long] = blackLIstArray.map(item => item.userid)
val filteredRDD: RDD[String] = logRDD.filter {
case log =>
val logSplit = log.split(" ")
val userId = logSplit(3).toLong
!userIdArray.contains(userId)
}
filteredRDD
}
7.4.3 对实时数据进行统计,更新点击次数表
// 对实时用户点击广告数据进行计数
// multiKey2OneDStream: DStream[RDD,RDD...]
// RDD : (key, value)
// key : datekey_userId_adId
// value : 1
val multiKey2OneDStream: DStream[(String, Long)] = adRealTimeFilterDStream.map {
case log =>
val logSplit = log.split(" ")
val timeStamp = logSplit(0).toLong
val dateKey = DateUtils.formatDateKey(new Date(timeStamp))
val userId = logSplit(3).toLong
val adId = logSplit(4).toLong
val key = dateKey + "_" + userId + "_" + adId
(key, 1L)
}
val multiKey2CountDStream: DStream[(String, Long)] = multiKey2OneDStream.reduceByKey(_ + _)
// 根据每个RDD中的数据, 更新用户点击次数表
multiKey2CountDStream.foreachRDD {
rdd =>
rdd.foreachPartition {
items =>
val clickCountArray = new ArrayBuffer[AdUserClickCount]()
for ((key, count) <- items) {
val keySplit = key.split("_")
val date = keySplit(0)
val userId = keySplit(1).toLong
val adId = keySplit(2).toLong
clickCountArray += AdUserClickCount(date, userId, adId, count)
}
// 更新
AdUserClickCountDAO.updateBatch(clickCountArray.toArray)
}
}
7.4.4 添加异常用户
// 获取用户点击次数表更新后的数据, 查询出一天内点击次数超过100次的用户, 即要加入黑名单的用户
val multiKey2BlackListDStream: DStream[(String, Long)] = multiKey2CountDStream.filter {
case (key, count) =>
val keySplit = key.split("_")
val date = keySplit(0)
val userId = keySplit(1).toLong
val adId = keySplit(2).toLong
val clickCount: Int = AdUserClickCountDAO.findClickCountByMultiKey(date, userId, adId)
if (clickCount > 100) {
true
} else {
false
}
}
// 加入黑名单
val blackListUserIdDStream: DStream[Long] = multiKey2BlackListDStream.map {
case (key, count) =>
key.split("_")(1).toLong
}.transform(rdd => rdd.distinct())
blackListUserIdDStream.foreachRDD{
rdd => rdd.foreachPartition{
items =>
val userIdArray = new ArrayBuffer[AdBlacklist]()
for(userId <- items) {
userIdArray += AdBlacklist(userId)
}
AdBlacklistDAO.insertBatch(userIdArray.toArray)
}
}
需求八:各省各城市广告点击量实时统计
8.1 需求概述
通过SparkStreaming的updateStateByKey算子累计计算各省的广告点击量。
8.2 简要运行流程
- 以date_province_city_adId为key
- 分组聚合
- 在使用updateStateByKey算子时要指定缓存目录
8.3 具体运行流程

8.4 代码实现
8.4.1 转换key值
streamingContext.checkpoint("./spark-streaming")
// 封装key : date_province_city_adId
val multiKey2OneDStream: DStream[(String, Long)] = adRealTimeFilterDStream.map {
case log =>
// timestamp province city userid adid
val logSplit = log.split(" ")
val timeStamp = logSplit(0).toLong
val dateKey = DateUtils.formatDateKey(new Date(timeStamp))
val province = logSplit(1)
val city = logSplit(2)
val adId = logSplit(4)
val newKey = dateKey + "_" + province + "_" + city + "_" + adId
(newKey, 1L)
}
8.4.2 进行聚合
// 使用updateStateByKey进行聚合
val multiKey2ReducedDStream: DStream[(String, Long)] = multiKey2OneDStream.updateStateByKey[Long] {
(values: Seq[Long], state: Option[Long]) =>
val currentCount = values.sum
val previousCount = state.getOrElse(0L)
Some(currentCount + previousCount)
}
8.4.3 封装case class 并入库
// 封装Case class : AsStat
// 入库
multiKey2ReducedDStream.foreachRDD{
rdd => rdd.foreachPartition{
items =>
val adStatArray = new ArrayBuffer[AdStat]()
for ((key, count) <- items){
val date = key.split("_")(0)
val province = key.split("_")(1)
val city = key.split("_")(2)
val adId = key.split("_")(3).toLong
val clickCount = count
adStatArray+= AdStat(date,province, city, adId, clickCount)
}
// 入库
AdStatDAO.updateBatch(adStatArray.toArray)
}
}
需求九:每天每个省份Top3热门广告
9.1 需求概述
根据需求八中统计的各省各城市累计广告点击量,创建SparkSQL临时表,通过SQL查询的形式获取各省的Top3热门广告。
9.2 简要运行流程
- 以date_province_adId为key , 1L为value
- 分组聚合
- 创建sparkSQL临时表
- 使用窗口函数进行查询
9.3 具体运行流程
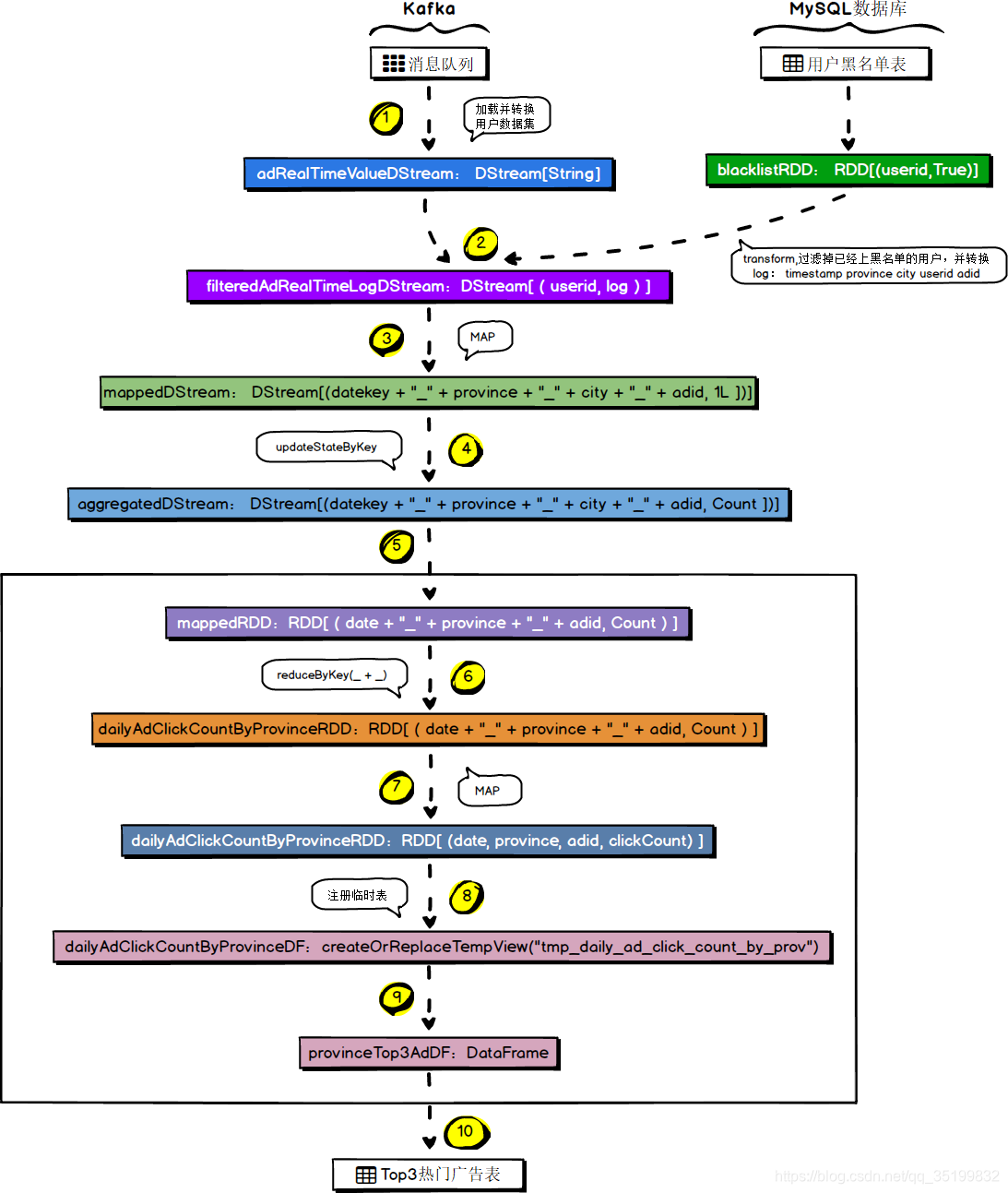
9.4 代码实现
9.4.1 封装key
streamingContext.checkpoint("./spark-streaming")
// 封装key : date_province_adId
val multiKey2OneDStream: DStream[(String, Long)] = adRealTimeFilterDStream.map {
log =>
// timestamp province city userid adid
val logSplit: Array[String] = log.split(" ")
val timeStamp = logSplit(0).toLong
val dateKey = DateUtils.formatDateKey(new Date(timeStamp))
val province = logSplit(1)
val adId = logSplit(4).toLong
val newKey = dateKey + "_" + province + "_" + adId
(newKey, 1L)
}
9.4.2 聚合
// 使用updateStateByKey进行聚合
val multiKey2CountDStream: DStream[(String, Long)] = multiKey2OneDStream.updateStateByKey {
case (values: Seq[Long], state: Option[Long]) =>
val currentCount = values.sum
val previousCount = state.getOrElse(0L)
Some(currentCount + previousCount)
}
9.4.3 转换格式
val tupleDStream: DStream[(String, String, Long, Long)] = multiKey2CountDStream.map {
case (key, count) =>
val date = key.split("_")(0)
val province = key.split("_")(1)
val adId = key.split("_")(2).toLong
(date, province, adId, count)
}
9.4.4 创建临时表并执行查询
val top3DStream: DStream[Row] = tupleDStream.transform {
rdd =>
import sparkSession.implicits._
rdd.toDF("date", "province", "adId", "count").createOrReplaceTempView("tmp_basic_info")
val sql = "select date, province, adId, count from (" +
"select date, province, adId, count," +
"row_number() over(partition by date, province order by count desc ) rank " +
"from tmp_basic_info" +
") t " +
"where rank <=3"
val resRDD: RDD[Row] = sparkSession.sql(sql).rdd
resRDD
}
9.4.5 封装case class并入库
// 入库
top3DStream.foreachRDD{
rdd =>
rdd.foreachPartition{
items =>
// 封装case class
val top3Array = new ArrayBuffer[AdProvinceTop3]()
for (item <- items) {
val date = item.getAs[String]("date")
val province = item.getAs[String]("province")
val adId = item.getAs[Long]("adId")
val count = item.getAs[Long]("count")
top3Array += AdProvinceTop3(date, province, adId, count)
}
// 入库
AdProvinceTop3DAO.updateBatch(top3Array.toArray)
}
}
需求十:最近一小时广告点击量实时统计
10.1 需求概述
通过Spark Streaming的窗口操作(reduceByKeyAndWindow)实现统计一个小时内每个广告每分钟的点击量。
10.2 简要运行流程
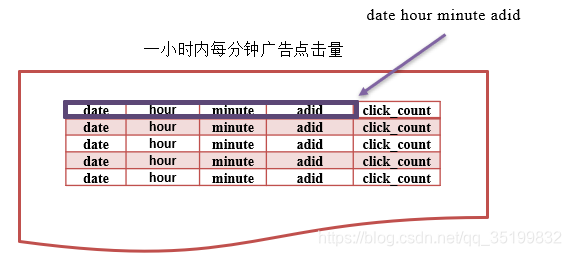
10.3 具体运行流程
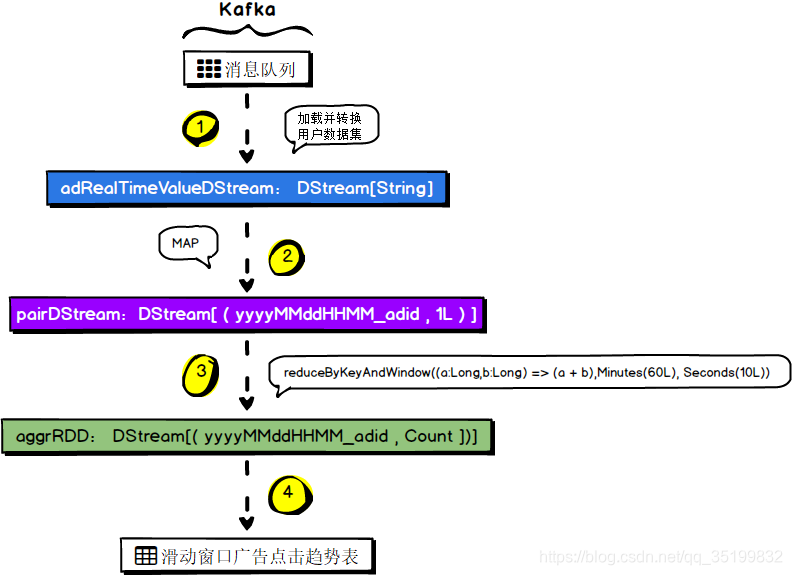
10.4 代码实现
10.4.1 封装key
// 封装key
val multiKey3OneDStream: DStream[(String, Long)] = adRealTimeFilterDStream.map {
case (log) =>
val logSplit: Array[String] = log.split(" ")
val timeStamp = logSplit(0).toLong
val date = DateUtils.formatTimeMinute(new Date(timeStamp))
val adId = logSplit(4).toLong
val newKey = date + "_" + adId
(newKey, 1L)
}
10.4.2 使用窗口操作计算
// 计算
val key2WindowsDStream: DStream[(String, Long)] = multiKey3OneDStream.reduceByKeyAndWindow(
(a: Long, b: Long) => a + b,
Minutes(60),
Minutes(1)
)
10.4.4 封装case class并入库
key2WindowsDStream.foreachRDD {
rdd =>
rdd.foreachPartition {
items =>
// 封装case class
val treadArray = new ArrayBuffer[AdClickTrend]()
for ((key, count) <- items) {
val keySplit = key.split("_")
// yyyyMMddHHmm
val timeMinutes = keySplit(0)
val date = timeMinutes.substring(0, 8)
val hour = timeMinutes.substring(8, 10)
val minute = timeMinutes.substring(10)
val adId = keySplit(1).toLong
treadArray += AdClickTrend(date, hour, minute, adId, count)
}
// 入库
AdClickTrendDAO.updateBatch(treadArray.toArray)
}
}
小结