一、广告点击流量实时统计模块介绍
网站 / app,是不是通常会给一些第三方的客户,打一些广告;也是一些互联网公司的核心收入来源;广告在网站 / app某个广告位打出去,在用户来使用网站 / app的时候,广告会显示出来;此时,有些用户可能就会去点击那个广告。
广告被点击以后,实际上,我们就是要针对这种用户行为(广告点击行为),实时数据,进行实时的大数据计算和统计。
每次点击一个广告以后,通常来说,网站 / app中都会有埋点(前端的应用中,比如JavaScript Ajax;app中的socket网络请求,往后台发送一条日志数据);日志数据而言,通常,如果要做实时统计的话,那么就会通过某些方式将数据写入到分布式消息队列中(Kafka);
日志写入到后台web服务器(nginx),nginx产生的实时的不断增加 / 更新的本地日志文件,就会被日志监控客户端(比如flume agent),写入到消息队列中(kafka),我们要负责编写实时计算程序,去从消息队列中(kafka)去实时地拉取数据,然后对数据进行实时的计算和统计。
这个模块的意义在于,让产品经理、高管可以实时地掌握到公司打的各种广告的投放效果。以便于后期持续地对公司的广告投放相关的战略和策略,进行调整和优化;以期望获得最好的广告收益。
二、需求分析:
1、实现实时的动态黑名单机制:将每天对某个广告点击超过100次的用户拉黑
2、基于黑名单的非法广告点击流量过滤机制:
3、每天各省各城市各广告的点击流量实时统计:
4、统计每天各省top3热门广告
5、统计各广告最近1小时内的点击量趋势:各广告最近1小时内各分钟的点击量
6、使用高性能方式将实时统计结果写入MySQL
7、实现实时计算程序的HA高可用性(Spark Streaming HA方案)
8、实现实时计算程序的性能调优(Spark Streaming Performence Tuning方案)
三、数据设计
3.1、数据格式介绍:
timestamp 1450702800
province Jiangsu
city Nanjing
userid 100001
adid 100001
相关表
每个用户对某个广告的点击量
CREATE TABLE `ad_user_click_count` (
`date` varchar(30) DEFAULT NULL,
`user_id` int(11) DEFAULT NULL,
`ad_id` int(11) DEFAULT NULL,
`click_count` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
黑名单
CREATE TABLE `ad_blacklist` (
`user_id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
每天每个省份某个广告的点击数
CREATE TABLE `ad_stat` (
`date` varchar(30) DEFAULT NULL,
`province` varchar(100) DEFAULT NULL,
`city` varchar(100) DEFAULT NULL,
`ad_id` int(11) DEFAULT NULL,
`click_count` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
top3
CREATE TABLE `ad_province_top3` (
`date` varchar(30) DEFAULT NULL,
`province` varchar(100) DEFAULT NULL,
`ad_id` int(11) DEFAULT NULL,
`click_count` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
广告的点击趋势,
CREATE TABLE `ad_click_trend` (
`date` varchar(30) DEFAULT NULL,
`hour` varchar(30) default null,
`minute` varchar(30) DEFAULT NULL,
`ad_id` int(11) DEFAULT NULL,
`click_count` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
四、技术方案设计及具体实现
4.1、实时计算各batch中的每天各用户对各广告的点击次数
4.1.1、创建topic
./kafka-topics.sh --zookeeper chb0-179005:2181,chb0-179004:2181,chb1-179006:2181 --describe --topic topic-ad4.1.2、构件Spark Streaming
// 构建Spark Streaming上下文
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("AdClickRealTimeStatSpark");
//构件Java Streaming Context
JavaStreamingContext jssc = new JavaStreamingContext(
conf, Durations.seconds(5)); //每个batch的时间间隔4.1.3、构件kafkaDirectStream
// 构建kafka参数map
// 主要要放置的就是,你要连接的kafka集群的地址(broker集群的地址列表)
Map<String, String> kafkaParams = new HashMap<String, String>();
kafkaParams.put(Constants.KAFKA_METADATA_BROKER_LIST,
Constants.propsUtils.get(Constants.KAFKA_METADATA_BROKER_LIST));
// 构建topic set
String kafkaTopics = Constants.propsUtils.get(Constants.KAFKA_TOPICS);
String[] kafkaTopicsSplited = kafkaTopics.split(",");
Set<String> topics = new HashSet<String>();
for(String kafkaTopic : kafkaTopicsSplited) {
topics.add(kafkaTopic);
}
//构建kafakDStream
JavaPairInputDStream<String, String> adRealTimeLogDStream = KafkaUtils.createDirectStream(
jssc,
String.class,
String.class,
StringDecoder.class,
StringDecoder.class,
kafkaParams,
topics);
4.1.4、通过kafkaDirectStream获取数据, 对数据进行mapToPair格式化成我们需要的key,
每天每个广告每个用户的点击量, 所以key为yyyyMMdd_userid_adid,value=1
然后reduceyByKey 进行合并。
输出的就是我们需要的结果, 每天每个用户对某个广告的点击数。
源源不断的,每个5s的batch中,当天每个用户对每支广告的点击次数
<yyyyMMdd_userid_adid, clickCount>4.2、使用高性能方式将每天各用户对各广告的点击次数写入MySQL中(更新)
对于咱们这种实时计算程序的mysql插入,有两种pattern(模式)
1、比较挫:每次插入前,先查询,看看有没有数据,如果有,则执行insert语句;如果没有,则执行update语句;好处在于,每个key就对应一条记录;坏处在于,本来对一个分区的数据就是一条insert batch,现在很麻烦,还得先执行select语句,再决定是insert还是update。
j2ee系统,查询某个key的时候,就直接查询指定的key就好。
2、稍微好一点:每次插入记录,你就插入就好,但是呢,需要在mysql库中,给每一个表,都加一个时间戳(timestamp),对于同一个key,5秒一个batch,每隔5秒中就有一个记录插入进去。相当于在mysql中维护了一个key的多个版本。
j2ee系统,查询某个key的时候,还得限定是要order by timestamp desc limit 1,查询最新时间版本的数据
通过mysql来用这种方式,不是很好,很不方便后面j2ee系统的使用
不用mysql;用hbase(timestamp的多个版本,而且它不却分insert和update,统一就是去对某个行键rowkey去做更新)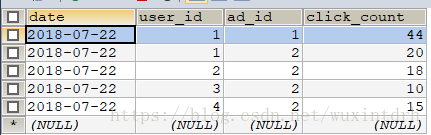
4.3、使用filter过滤出每天对某个广告点击超过100次的黑名单用户,并写入MySQL中
4.3.1、首先过滤每个批次中的记录, 在数据库中点击数查过100的记录
JavaPairDStream<String, Long> blacklistDStream =
dailyUserAdClickCountDStream.filter(new Function<Tuple2<String,Long>, Boolean>() {
@Override
public Boolean call(Tuple2<String, Long> v1) throws Exception {
String key = v1._1;
String[] keySplited = key.split("_");
// yyyyMMdd -> yyyy-MM-dd
String date = DateUtils.formatDate(DateUtils.parseDateKey(keySplited[0]));
long userid = Long.valueOf(keySplited[1]);
long adid = Long.valueOf(keySplited[2]);
// 从mysql中查询指定日期指定用户对指定广告的点击量
IAdUserClickCountDAO adUserClickCountDAO = DAOFactory.getAdUserClickCountDAO();
int clickCount = adUserClickCountDAO.findClickCountByMultiKey(
date, userid, adid);
// 判断,如果点击量大于等于10,ok,那么不好意思,你就是黑名单用户
// 那么就拉入黑名单,返回true
if(clickCount >= 10) {
return true;
}
// 反之,如果点击量小10的,那么就暂时不要管它了
return false;
}
});4.3.2、由于我们是获取黑名单, 所以只需要userid, 通过map,只返回userid的RDD
JavaDStream<Long> blaskListUseridDStream = blacklistDStream.map(new Function<Tuple2<String,Long>, Long>() {
@Override
public Long call(Tuple2<String, Long> v1) throws Exception {
String key = v1._1;
String[] keySplited = key.split("_");
Long userid = Long.valueOf(keySplited[1]);
return userid;
}
});4.3.3、但是在一个batch中,可以有多个条相同用户的记录, 所以我们需要进行去重
此处利用tranform, transform操作允许将任意RDD到RDD函数应用于DStream
//去重
JavaDStream<Long> distblaskListUseridDStream = blaskListUseridDStream.transform(new Function<JavaRDD<Long>, JavaRDD<Long>>() {
@Override
public JavaRDD<Long> call(JavaRDD<Long> v1) throws Exception {
return v1.distinct();
}
});
4.3.4、通过foreachRDD,将黑名单用户userid存入mysql中。
4.3.5、动态生成的黑名单, 用于日志信息进行过滤
对4.1.4进行升级, 动态获取数据库中的黑名单, 如果是黑名单中的用于, 记录就不用继续考虑了。
4.4、用transform操作,对每个batch RDD进行处理,都动态加载MySQL中的黑名单生成RDD,然后进行join后,过滤掉batch RDD中的黑名单用户的广告点击行为
通过transformToPair, 可以对DStream中每个RDD进行算子操作,
获取数据库中的黑名单, 通过parallelizePairs,转化成backRDD, <userId, true>
为了能够与backRDD进行join, 先将点击行为RDD进行map, 得到<userId, rdd>
join操作, 但是需要注意, 由于点击行为的用于不一定在blackRDD中, 所以需要使用leftOuterJoin
通过filter,过滤处非黑名单中的点击行为信息。
输出我们需要的数据,
/**
* 对源数据进行过滤
* @param adRealTimeLogDStream 源数据
* @return
*/
private static JavaPairDStream<String, String> filterByBlackList(
JavaPairInputDStream<String, String> adRealTimeLogDStream) {
JavaPairDStream<String, String> filterDStream = adRealTimeLogDStream.transformToPair(new Function<JavaPairRDD<String,String>, JavaPairRDD<String,String>>() {
private static final long serialVersionUID = -8650685273099590863L;
@Override
public JavaPairRDD<String, String> call(
JavaPairRDD<String, String> rdd) throws Exception {
//获取黑名单
IAdBlacklistDAO adBlacklistDAO = DAOFactory.getAdBlacklistDAO();
List<AdBlacklist> adBlacklists = adBlacklistDAO.findAll();
List<Tuple2<Long, Boolean>> blackTuples = new ArrayList<Tuple2<Long, Boolean>>();
for(AdBlacklist adBlacklist : adBlacklists) {
blackTuples.add(new Tuple2<Long, Boolean>(adBlacklist.getUserid(), true));
}
//转化成一个RDD
JavaSparkContext sc = new JavaSparkContext(rdd.context());
JavaPairRDD<Long, Boolean> blacListRDD = sc.parallelizePairs(blackTuples);
//为了与blackListRDD进行join, 需要将原始数据rdd,转化为<userid, 原始数据>
JavaPairRDD<Long, Tuple2<String, String>> mapRDD = rdd.mapToPair(new PairFunction<Tuple2<String,String>, Long, Tuple2<String, String>>() {
private static final long serialVersionUID = 7001016275687081936L;
@Override
public Tuple2<Long, Tuple2<String, String>> call(
Tuple2<String, String> t) throws Exception {
String logInfo = t._2;
long userId = Long.valueOf(logInfo.split(" ")[3]);
return new Tuple2<Long, Tuple2<String,String>>(userId, t);
}
});
// 将原始日志数据rdd,与黑名单rdd,进行左外连接
// 如果说原始日志的userid,没有在对应的黑名单中,join不到,左外连接
// 用inner join,内连接,会导致数据丢失
JavaPairRDD<Long, Tuple2<Tuple2<String, String>, Optional<Boolean>>> joinRDD = mapRDD.leftOuterJoin(blacListRDD);
//过滤
JavaPairRDD<Long, Tuple2<Tuple2<String, String>, Optional<Boolean>>> filterRDD = joinRDD.filter(new Function<Tuple2<Long,Tuple2<Tuple2<String,String>,Optional<Boolean>>>, Boolean>() {
private static final long serialVersionUID = 2749100847991384506L;
@Override
public Boolean call(
Tuple2<Long, Tuple2<Tuple2<String, String>, Optional<Boolean>>> v1)
throws Exception {
Optional<Boolean> optional = v1._2._2;
// 如果这个值存在,那么说明原始日志中的userid,join到了某个黑名单用户
if(optional.isPresent() && optional.get()) {
return false;
}
return true;
}
});
JavaPairRDD<String, String> resultRDD = filterRDD.mapToPair(new PairFunction<Tuple2<Long,Tuple2<Tuple2<String,String>,Optional<Boolean>>>, String, String>() {
private static final long serialVersionUID = 8270722683260778935L;
@Override
public Tuple2<String, String> call(
Tuple2<Long, Tuple2<Tuple2<String, String>, Optional<Boolean>>> t)
throws Exception {
return t._2._1;
}
});
return resultRDD;
}
});
return filterDStream;
}
4.5、使用updateStateByKey操作,实时计算每天各省各城市各广告的点击量,并时候更新到MySQL
4.5.1、通过mapToPair 将源数据格式化(yyyyMMdd_province_city_adid,clickCount)
4.5.2、updateStateByKey统计实时的点击量
JavaPairDStream<String, Long> aggrDStream = mapDStream.updateStateByKey(new Function2<List<Long>, Optional<Long>, Optional<Long>>() {
@Override
public Optional<Long> call(List<Long> values, Optional<Long> optional)
throws Exception {
long clickCount = 0L;
if(optional.isPresent()){
clickCount = optional.get();
}
//values 表示一个batch的所有值
for (Long value : values) {
clickCount += value;
}
return Optional.of(clickCount);
}
});4.6、使用transform结合Spark SQL,统计每天各省份top3热门广告:首先以每天各省各城市各广告的点击量数据作为基础,首先统计出每天各省份各广告的点击量;然后启动一个异步子线程,使用Spark SQL动态将数据RDD转换为DataFrame后,注册为临时表;最后使用Spark SQL开窗函数,统计出各省份top3热门的广告,并更新到MySQL中
4.7、使用window操作,对最近1小时滑动窗口内的数据,计算出各广告各分钟的点击量,并更新到MySQL中
4.7.1、对过滤后的原始数据,使用mapToPair 映射成<yyyyMMddHHMM_adid,1L>格式
4.7.2、使用windwo operation统计最近一小时的 广告点击量
8、实现实时计算程序的HA高可用性
9、对实时计算程序进行性能调优