不知道其他人会不会这样,反正作为一个入坑一年多的Acmer,有时候特别想知道自己到底刷了多少题,当然可以到OJ上一题一题的数,但是这很不程序员啊,这么这么机械性的工作怎么可以亲自动手呢。虽然现在已经有一个开源项目,可以统计在各大OJ的刷题情况,但还是想自己亲手实现一番。刚好最近学了Python爬虫,正好可以完成自己之前立下的flag了。将实现Codeforces、HDU、POJ,洛谷等主流OJ刷题记录的爬取,和统计AC数量,最后用QT实现界面。话不多说,直接进入正题,先从codeforces下手。
一、需求分析
- 首先我们应该找到提交界面的url。
- 分析请求方式。
- 通过浏览器的检查工具分析网页源码。
- 获取我们所需要的内容,然后保存到文本或者数据库。
- 解析完当前界面后,进行翻页,然后重复上面的步骤。
二、具体实现
下面以tourist大佬的提交信息界面为例。
- 分析url链接
当刚开始进入提交界面时,url是这样的

之后我们进行翻页看看。可以发现每页提交界面的url的规律,如下,最后是当前的页码。使用的是同步请求的方式。既然是同步求,那么就非常好办了,直接获取html文本,然后进行解析就行了。
https://codeforces.com/submissions/username/page/2

- 发送请求
通过requests库发送请求,可以选择不设置headers,因为codeforces不反爬虫的。
import requests
url = 'https://codeforces.com/submissions/tourist/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
- 分析网页,然后进行解析
使用chrome浏览器,在提交记录上右击,选择检查。其他浏览器也类似。
经过观察可以发现,提交记录信息是放在一个table中的,每个提交记录在一个tr标签中。那么我们首先就是要把这几个tr标签给提取出来,然后在根据我们要的信息(题目标题,提交状态等)进行解析。

经过检查可以确定 data-submission-id这个属性是tr标签特有的,那么我们就可以通过这个属性来定位tr标签。使用pyquery进行解析(跟JQuery语法很类似,支持css selector)。
from pyquery import PyQuery as pq
doc=pq(response.text)
items = doc.find('[data-submission-id]').items() #将查到的元素生成一个迭代器方便便利。
把每个tr标签提取出来后,接下来开始对里面的td每个td标签下手了。我就提取了题目名字和提交状态。其他的方法一样。

现在对每个td单独进行解析。所以可以通过**.status-small>a定位到a标签。然后提取它的文本内容,也就是题目标题。但如果是从整个网页中中则不行,可以选择通过data-problemid这个特定标签来定位。使用:nth-child(6)**获取提交状态的内容。将获取的内容打包成一个字典。(当然其他形式也可以,然后看你要保存到数据库或者文本中了)
items = doc.find('[data-submission-id]').items()
for item in items:
it = solve_tr(item)
problemName = tr.find('.status-small>a').text()
state = tr.find(':nth-child(6)').text()
it = {'problemName': problemName, 'state': state}
problemName=tr.find('[data-problemid]>a').text()
- 获取页码数量
至此已经我们已经可以解析一页的提交内容了,但是如果实现翻页功能呢。要实现翻页功能其实很简单,只要将url最后的数字替换掉,就可以了。
https://codeforces.com/submissions/username/page/2
https://codeforces.com/submissions/username/page/3
重点在于我们应该翻页几次。对于翻页问题有两个解决方案,一个是死循环,一直进行下去,出现异常在停止,但是这个在codeforces这里是行不通的,因为如果超出页码后,会默认显示最后一页。所以我们就只能老老实实的统计页码数量了。
页码标签是在一个无序表中,倒数第二个li标签的内容存的就是总页码数,那么我们只要获取里面的内容就可以了。
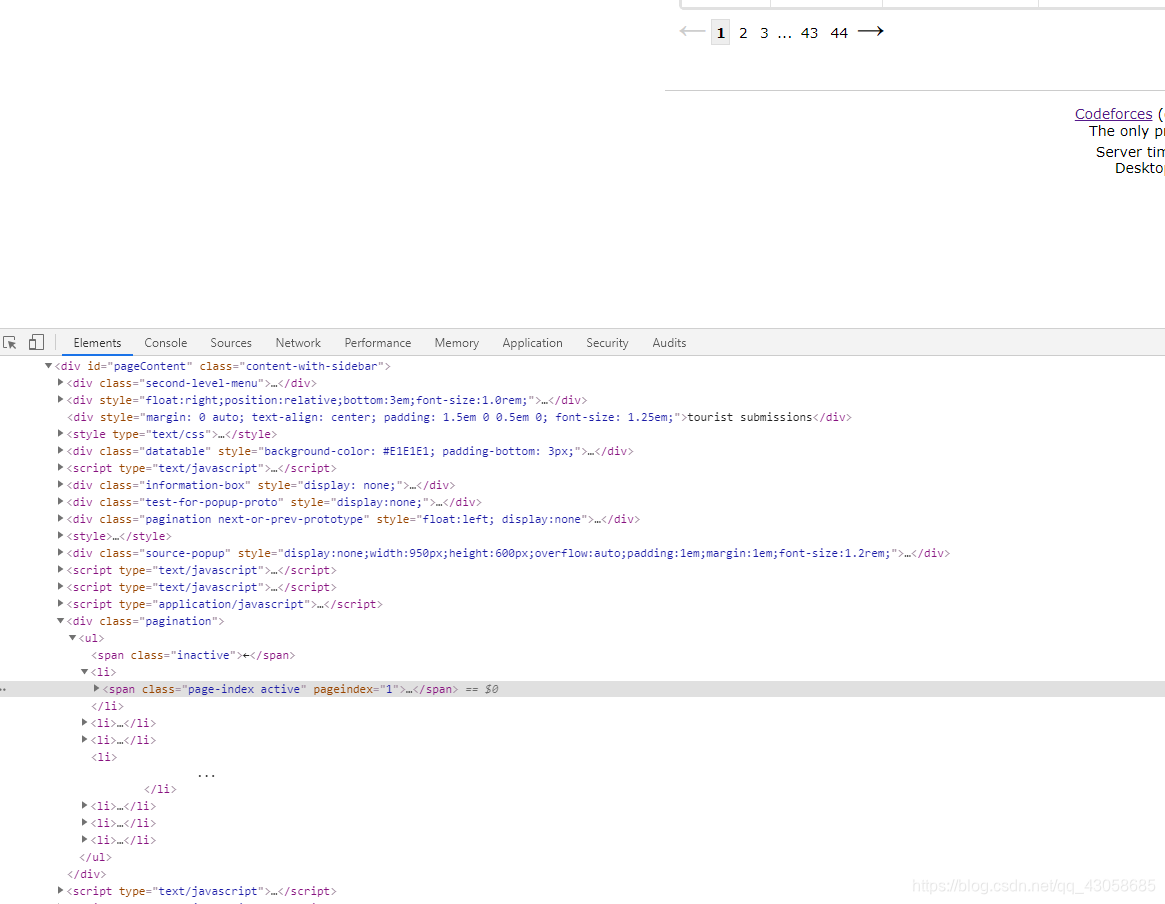
通过nth-child选择器获取。
def get_pages_num(doc):
"""
获取需要爬取的页码数量
:param doc: pyquery返回的解析器
:return: int,页码数量
"""
try:
length = doc.find('#pageContent>.pagination>ul>*').length
last_li = doc.find('#pageContent>.pagination>ul>li:nth-child(' + str(length-1) + ')')
print('length', length)
print(last_li.text())
# for item in items:
# print(item)
return max(1, int(last_li.text()))
except Exception :
return None
现在爬取codeforces刷题记录的需求基本完成了,将上面的代码整理一下,就完工了。
三、完整代码
有个可以直接运行的代码是件非常愉快的事,所以我就把完整代码贴上来了
from pyquery import PyQuery as pq
import requests
import time
def solve_tr(tr):
"""
解析我们所需要的内容
:param tr: tr元素
:return: dict
"""
problemName = tr.find('.status-small>a').text()
state = tr.find(':nth-child(6)').text()
it = {'problemName': problemName, 'state': state}
return it
def get_pages_num(doc):
"""
获取需要爬取的页码数量
:param doc: pyquery返回的解析器
:return: int,页码数量
"""
try:
length = doc.find('#pageContent>.pagination>ul>*').length
last_li = doc.find('#pageContent>.pagination>ul>li:nth-child(' + str(length-1) + ')')
print('length', length)
print(last_li.text())
# for item in items:
# print(item)
return max(1, int(last_li.text()))
except Exception :
return None
def crawl_one_page(doc):
"""
爬取每一页中的内容
:param doc: pyquery返回的解析器
"""
items = doc.find('[data-submission-id]').items()
for item in items:
it = solve_tr(item)
with open('data.txt', 'a+', encoding='utf-8') as f:
f.write(str(it) + '\n')
print(it)
def get_username():
"""
获取用户名
:return:
"""
username = input('请输入用户名:')
return username
def main():
base = 'https://codeforces.com/submissions/'
username = get_username()
url = base+username+'/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
doc = pq(response.text)
# 注释部分为测试代码
# crawl_one_page(doc)
# with open('index.html', 'w', encoding='utf-8') as f:
# f.write(doc.text())
num = get_pages_num(doc)
if num is not None:
for i in range(1, num + 1):
url = base+username+'/page/'+str(i)
print(url)
response = requests.get(url=url)
doc = pq(response.text)
crawl_one_page(doc)
time.sleep(2)
else:
print('username is no exist or you are no submission')
if __name__ == '__main__':
main()
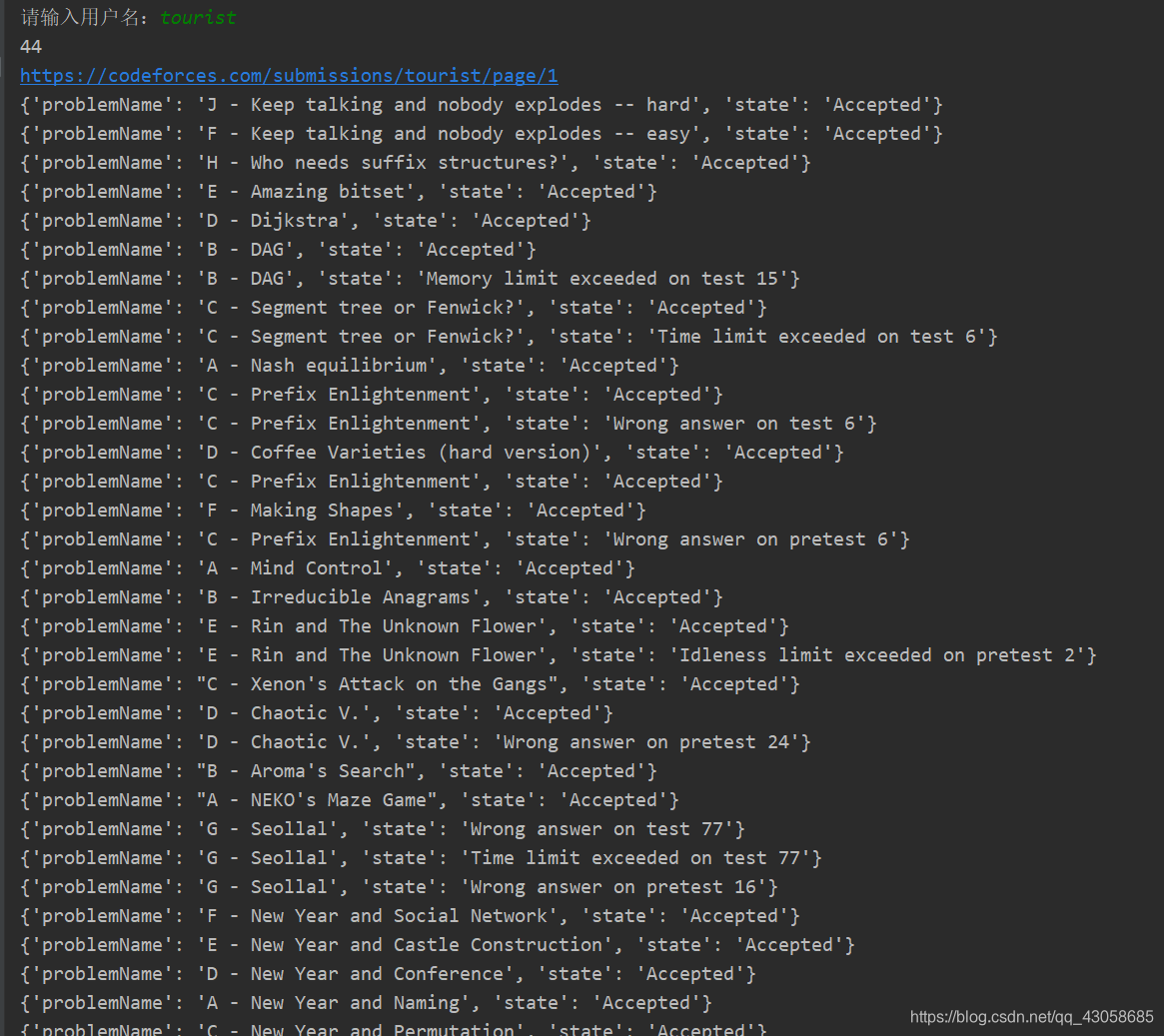
运行效果如下