一、认识ElasticSearch(简称ES)
1.为什么要使用ElasticSearch?
Lucene的配置及使用非常复杂,我们希望有一个零配置、完全免费、扩容性好并且始终可用的云的实时搜索方案
2.ElasticSearch的特点
2.1.解决了原生的Lucene的不足,实现了高可用的分布式集群搜索方案
2…2.分布式的实时文件存储,每个字段都被索引并可被搜索
2.3.分布式的实时分析搜索引擎
2.4.可以扩展到上百台服务器,处理PB级结构化或非结构化数据
2.5.高度集成化的服务
2.6.上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它拥有开瓶即饮的效果(安装即可使用),只需很少的学习既可在生产环境中使用。
3.与ES类似的框架
solr、Katta、HadoopContrib ,与它们相比, ES自身带有分布式协调管理功能,但仅支持json文件格式,本身更注重于核心功能,高级功能多有第三方插件提供,在处理实时搜索应用时效率明显要比它们好。
二、ES的安装及使用说明
1.ES的安装
下载地址:https://www.elastic.co/downloads/elasticsearch
运行ES:bin/elasticsearch.bat
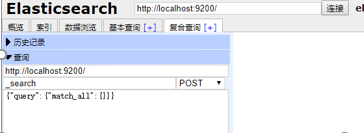
验证:访问:http://localhost:9200/
2.ES交互式客户端
2.1.基于RESTful API,curl命令方式,借助POSTER插件实现
2.2.Java API
Java客户端所在的ES版本必须与集群中其他节点一致,否则,它们可能互相无法识别
3.辅助管理工具Kibana5
Kibana5.2.2下载地址:https://www.elastic.co/downloads/kibana
解压并编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
启动Kibana5 : bin\kibana.bat
默认访问地址:http://localhost:5601
Discover:可视化查询分析器
Visualize:统计分析图表
Dashboard:自定义主面板(添加图表)
Timelion:Timelion是一个kibana时间序列展示组件(暂时不用)
Dev Tools :Console(同CURL/POSTER,操作ES代码工具,代码提示,很方便)
Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性。
4.ES服务端安装
4.1.相关概念
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
(2)Index:索引库,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(3)Type:类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
(4)Document&field:文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
(5)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(6)Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(7)shard(ʃɑːrd,分片):单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica(ˈreplɪkə,复制品):任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
4.2.安装
下载地址:
https://www.elastic.co/downloads/elasticsearch

解压即可
启动: bin/elasticsearch.bat
测试:http://localhost:9200
4.3.集群健康状态
分三个等级:green,绿色——————代表所有的主分片和副本分片都已分配。你的集群是 100% 可用的
yellow,黄色————所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。
red,红色——————至少一个主分片以及它的全部副本都在缺失中
5.安装kibana客户端
配置服务器地址,编辑config/kibana.yml,设置elasticsearch.url的值为已启动的ES
启动:
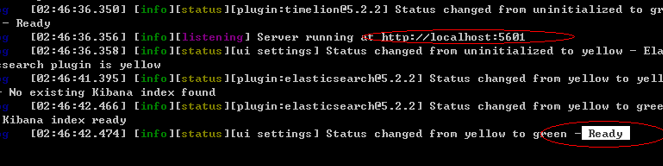
测试:http://localhost:5601
6.head入门
安装:npm install
启动: npm run start
配置跨域访问: 修改 elasticsearch/config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: “*”
使用: