抛砖
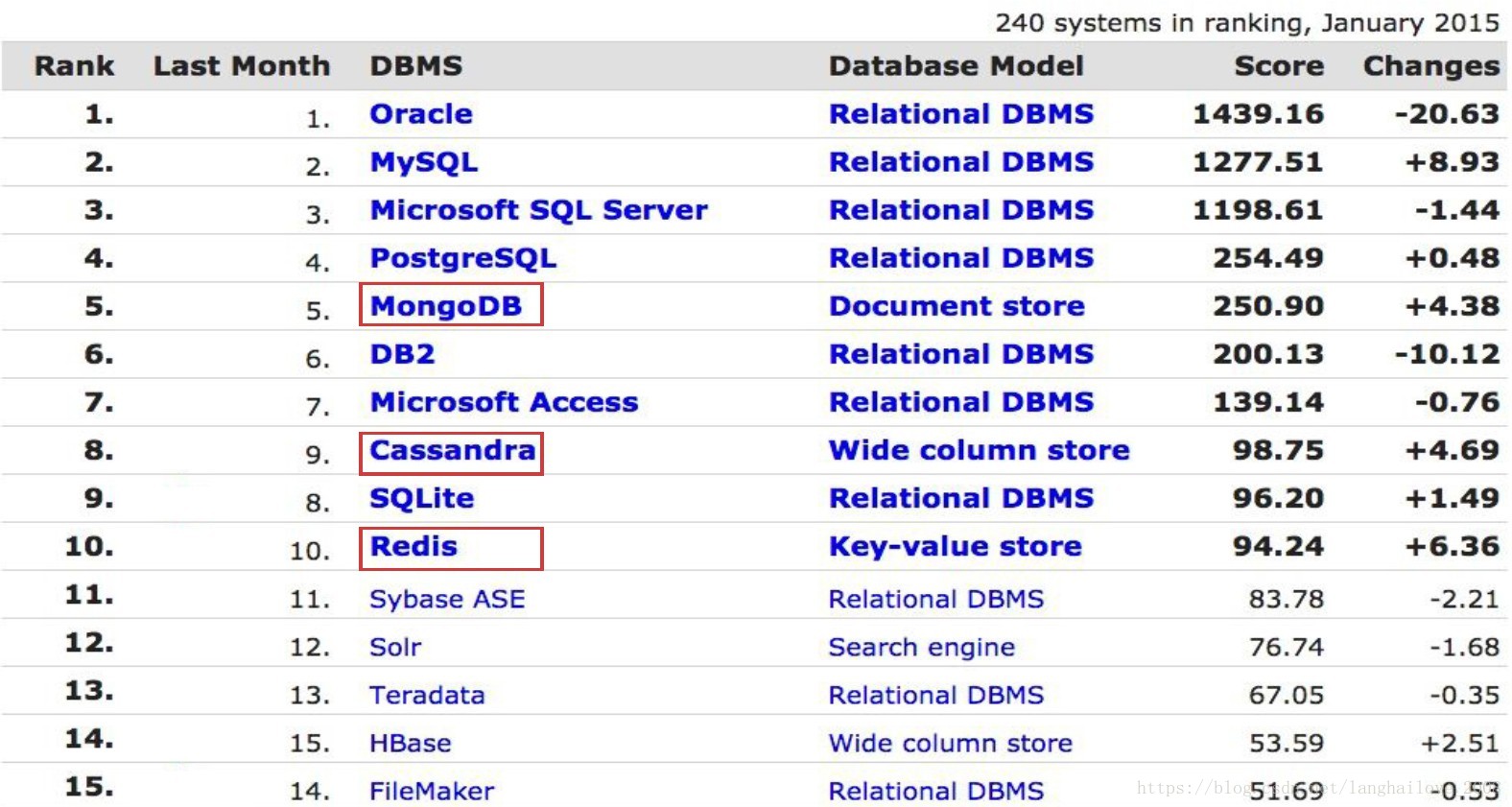
1、数据库排名(国外权威机构DB-Engines发布)
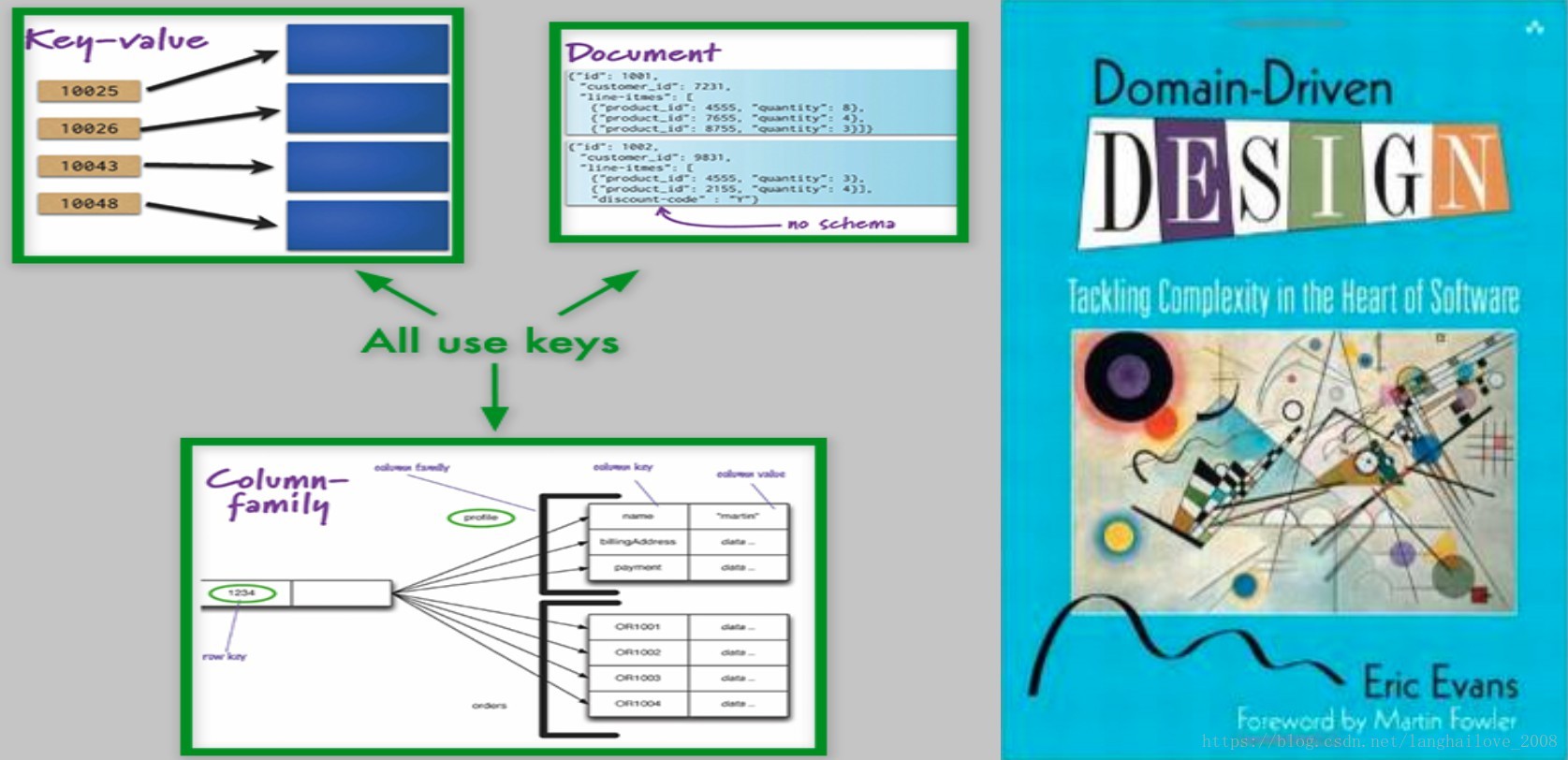
2、常见NoSQL技术对比

3、为什么使用NoSQL技术
- 优点:
- 对数据库高并发读写。
- 对海量数据的高效率存储和访问。
- 对数据库的高可扩展性和高可用性。
- 弱点:
- 数据库事务一致性需求
- 数据库的写实时性和读实时性需求
- 对复杂的SQL查询,特别是多表关联查询的需求
从SQL到NoSQL的思维转变
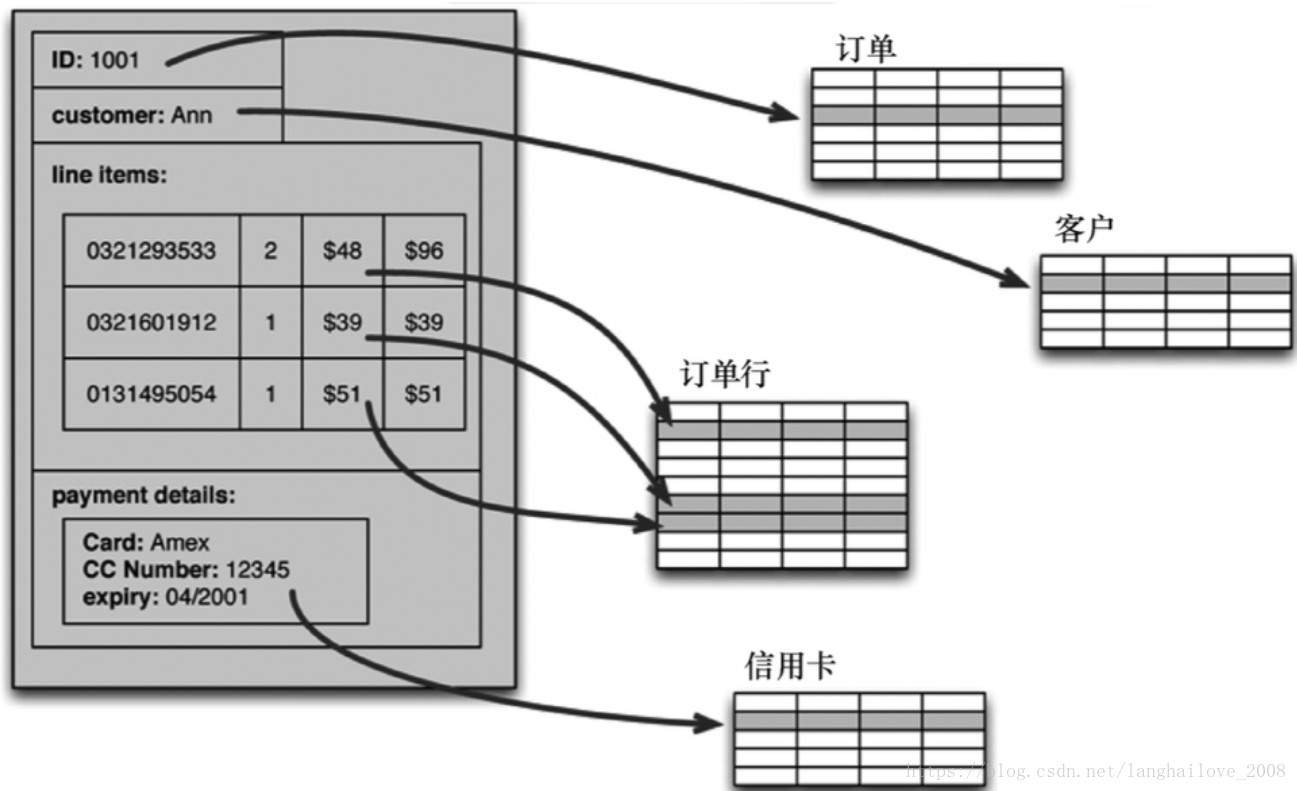
关系型数据库建模
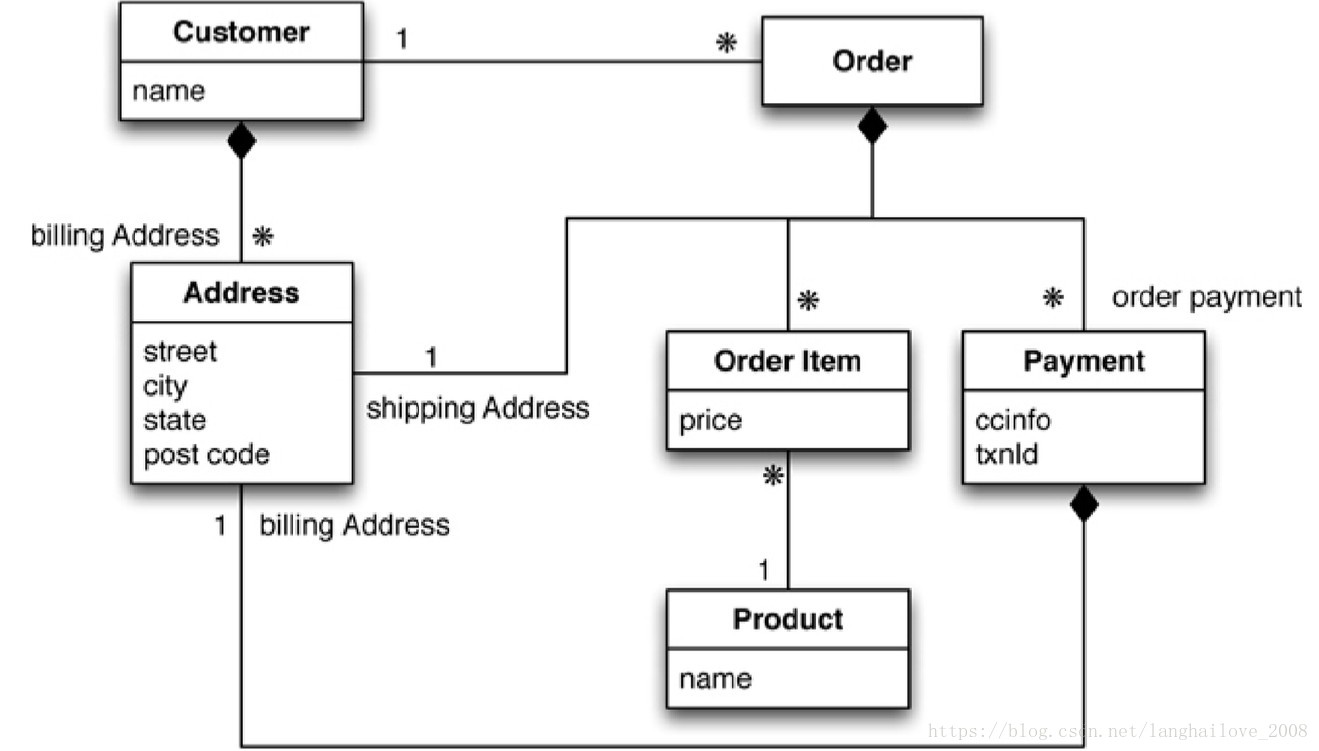
聚合型数据库建模-UML
聚合型数据库建模-JSON
// in customers
{
"id":1,
"name":”Ann",
"billingAddress": [{"city":”BeiJing"}]
}
// in orders
{
"id”:1001,
"customerId":1,
"orderItems”:[{
"productId":27,
"price": 32.45,
"productName": "MongoDB"
}
],
"shippingAddress":[{"city":"BeiJing"}] ,
"orderPayment":[{
"ccinfo":"1000-1000-1000-1000",
"txnId":"abelif879rft",
"billingAddress": {"city": "BeiJing"}
}
]
}面向聚合的NoSQL型数据库
为什么要⽤用MongoDB呢
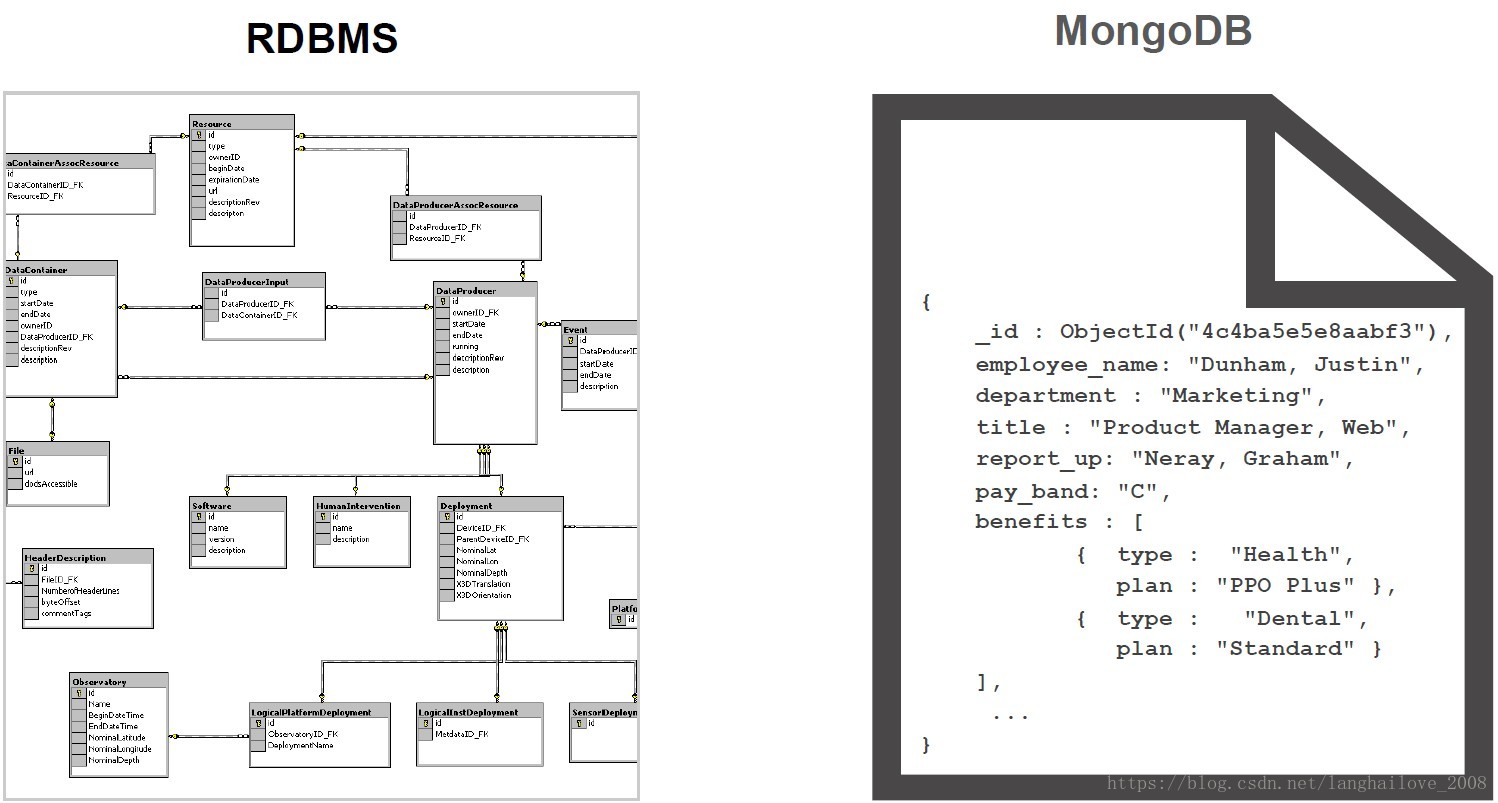
MongDB基本概念
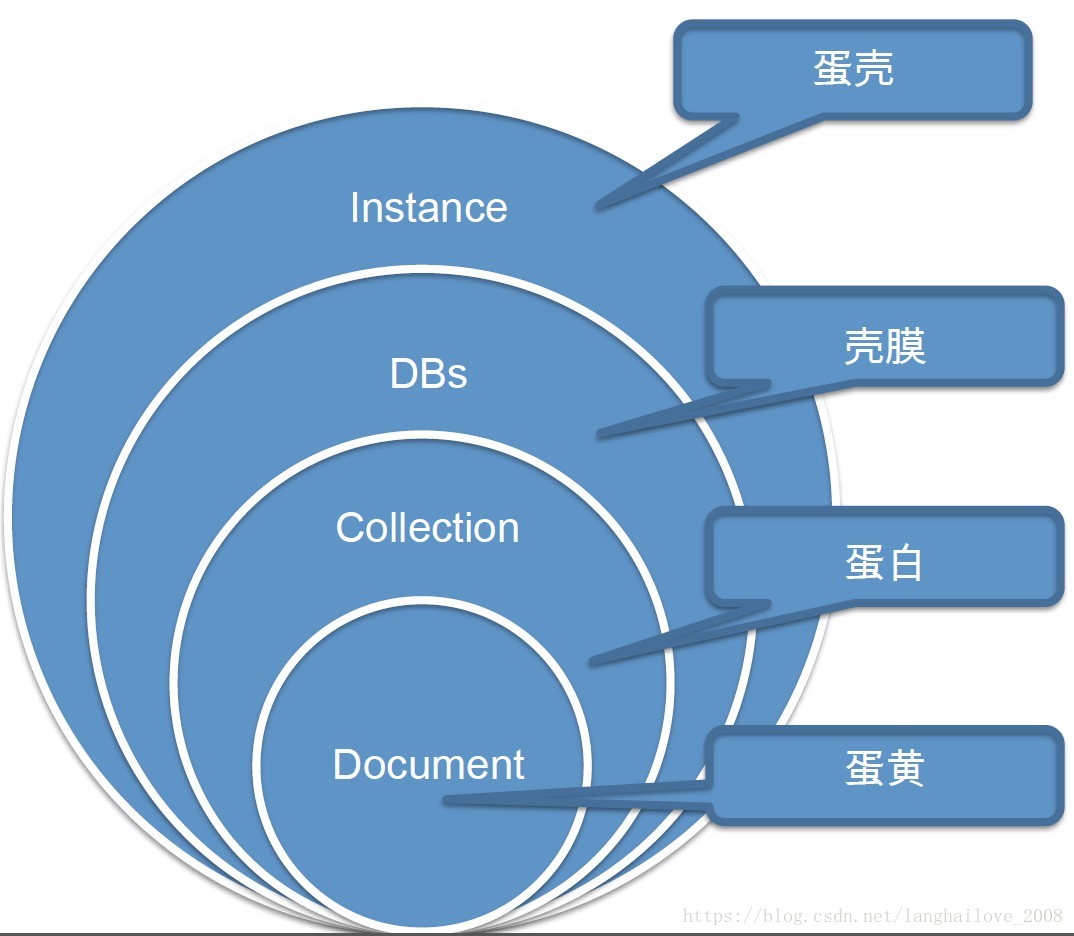
怎么用MongoDB对数据建模呢?
引⽤式
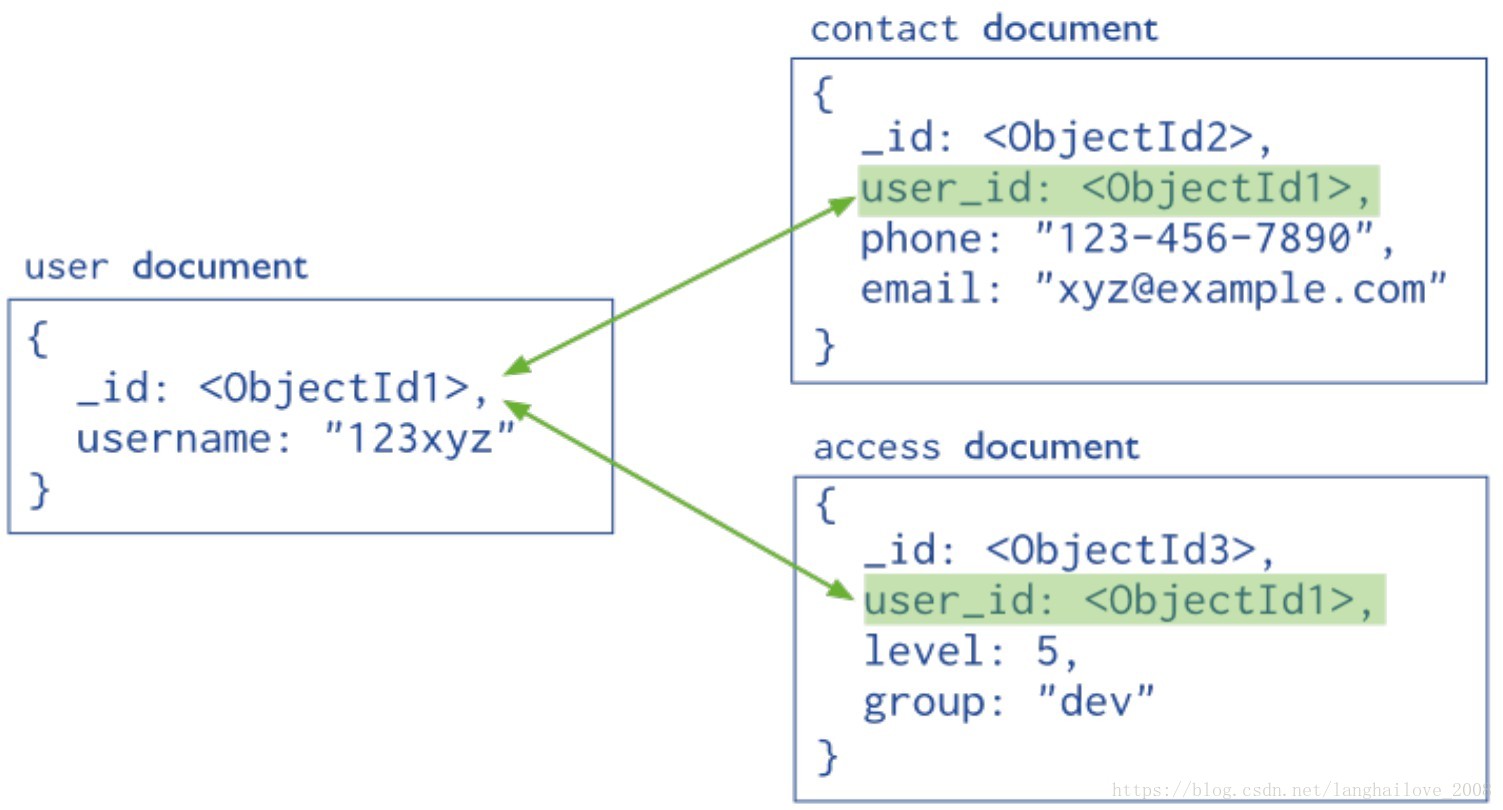
内嵌式

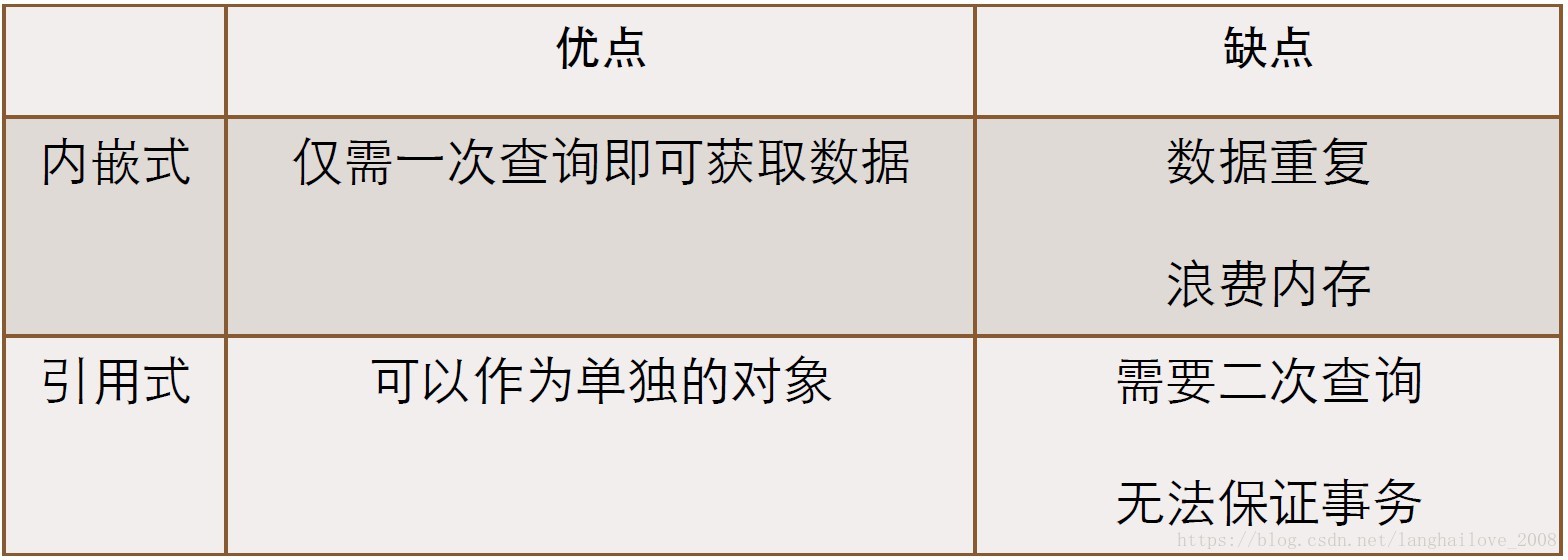
内嵌式VS引⽤用式
示例:商品多语⾔言信息列表
{
pid: 1261
en_US : { name : “Nike AIR MAX 90”, desc : ..., <etc...> },
zh_CN : { name : “Nike耐克 男⼦子AIR MAX 90跑步鞋”,desc : ..., <etc...> },
de_CH : ...,
<... 20 多种语⾔言... >
},
{
pid: 1262,
...
}设计思想:所有产品相关信息都在⼀一个⽂文档内
常⽤用查询
db.product.find( { pid : 1261 } , { en_US : true } );
db.product.find( { pid : 1262 } , { zh_CN : true } );
磁盘-‐>内存-‐>客户端
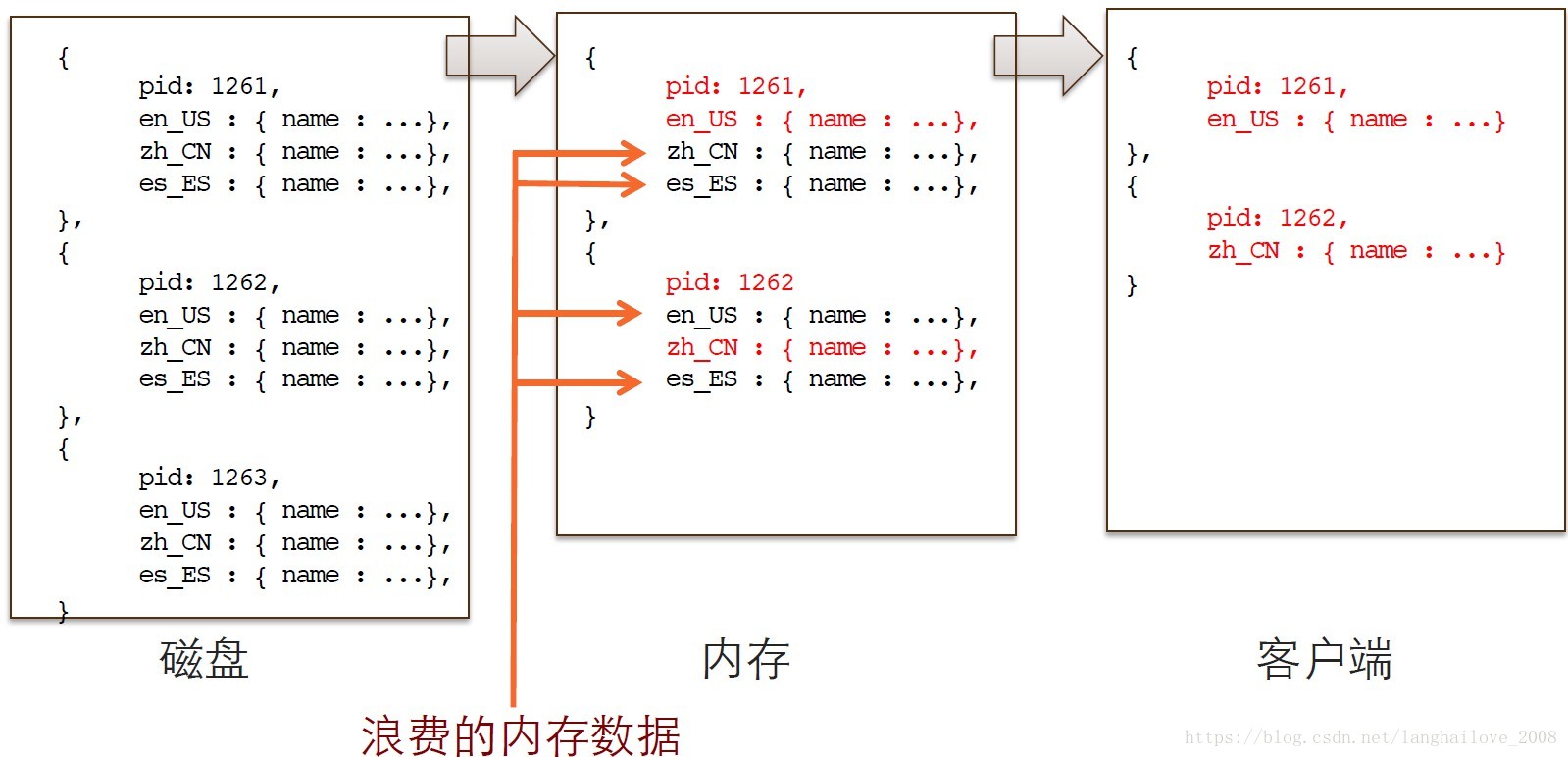
解决⽅方案
{ pid: "1261-en_US", name : ..., <etc...> }
{ pid: "1261-zh_CN", name : ..., <etc...> }
{ pid: "1262-fr_FR", name : ..., <etc...> }
... ...产品检索时间显著的缩短
小结
• 根据数据的访问⽅方式建模
• 内嵌优先
• 结构易变的数据适合⽤用引⼊入式
• 尽量仅为⼀一级对象创建单独的集合
MongoDB如何实现高可用?
ReplicaSet(复制集)-‐⾃自动容错、恢复的⾼高可⽤用⽅方案
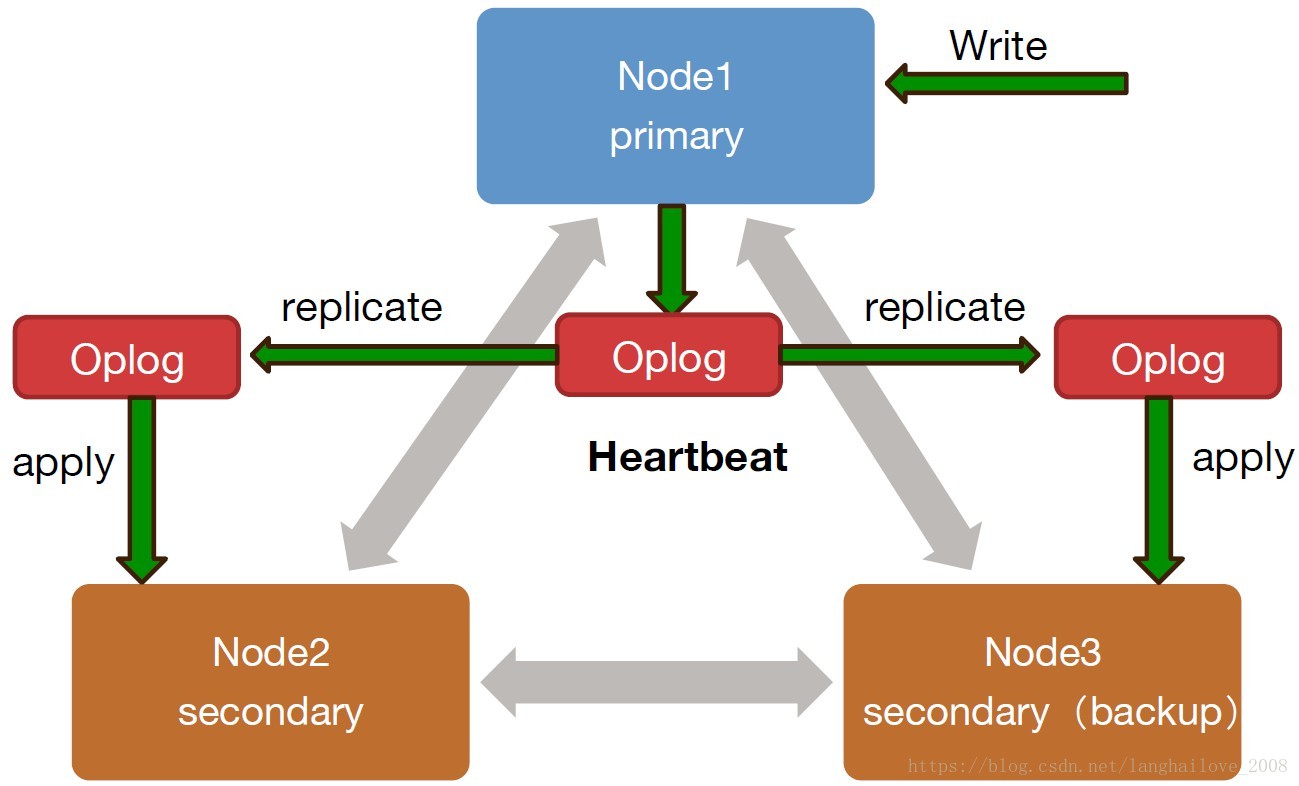
Read Preference Modes(复制集选项)
• primary: 默认参数,读操作只在主节点上
• primaryPreferred: 优先从主节点上读,主节点不可⽤用时从从节点
读取数据
• secondary:读操作只在从节点上
• secondaryPreferred:优先从从节点上,从节点不可⽤用时从主节点读
取数据
• nearest:不管主、从节点,从⺴⽹网络延迟最低的节点上读取数据
Write Concern(安全写级别)
• 保障写操作(Insert/Update/Delete)的可靠性
• 每次写操作driver都会调⽤用db.getLastError()⽅方法,业务代码不需要
显式调⽤用
• driver⼀一定会调⽤用db.getLastError(),但并不⼀一定能捕获到错误, 主
要取决于write concern的设置级别
• 处理逻辑由client决定,如:写⼊入⽇日志或再次尝试写⼊入
Unacknowledged(write cocern:0)
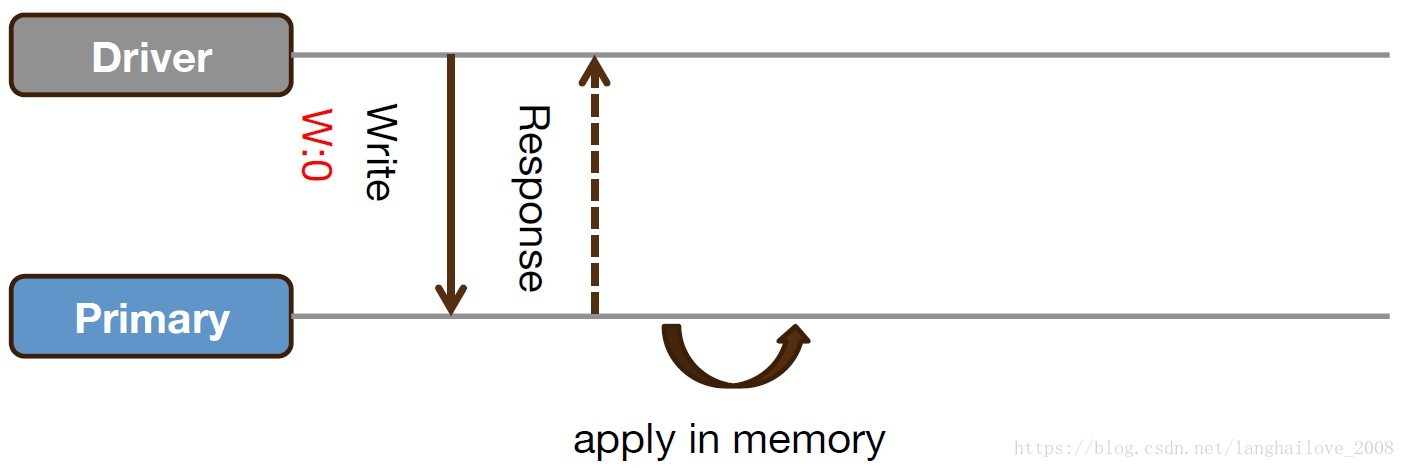
Unacknowledged(write cocern:1),默认设置
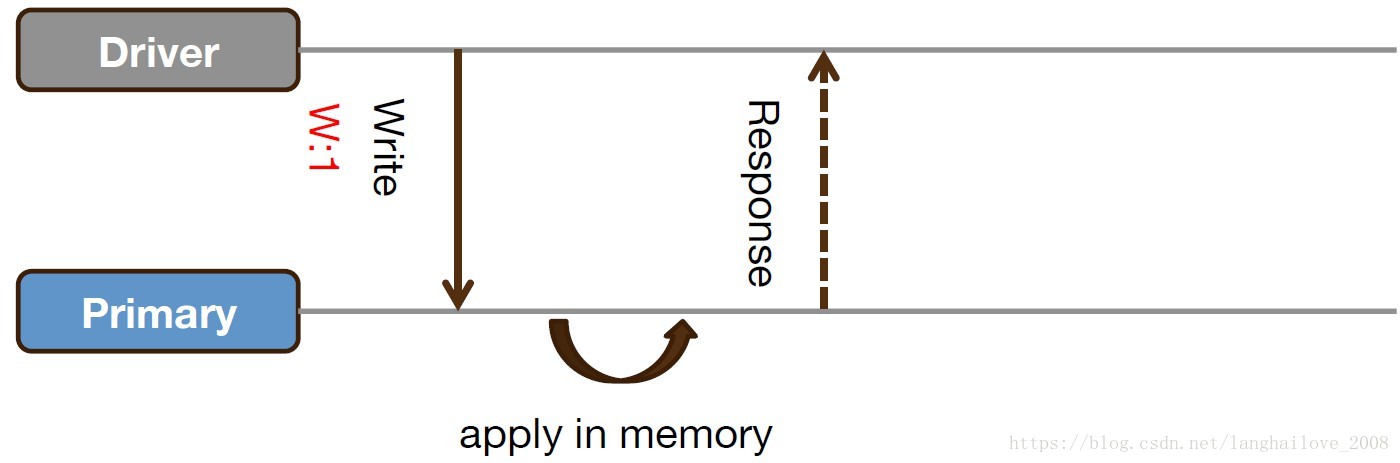
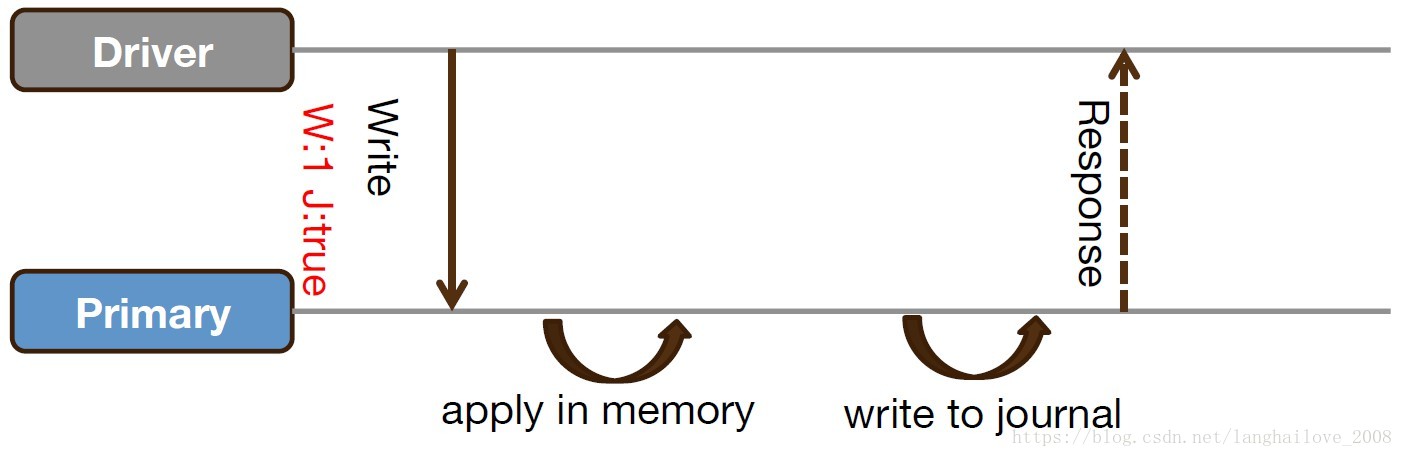
Wait for journal sync(write concern:1 && journal:true)
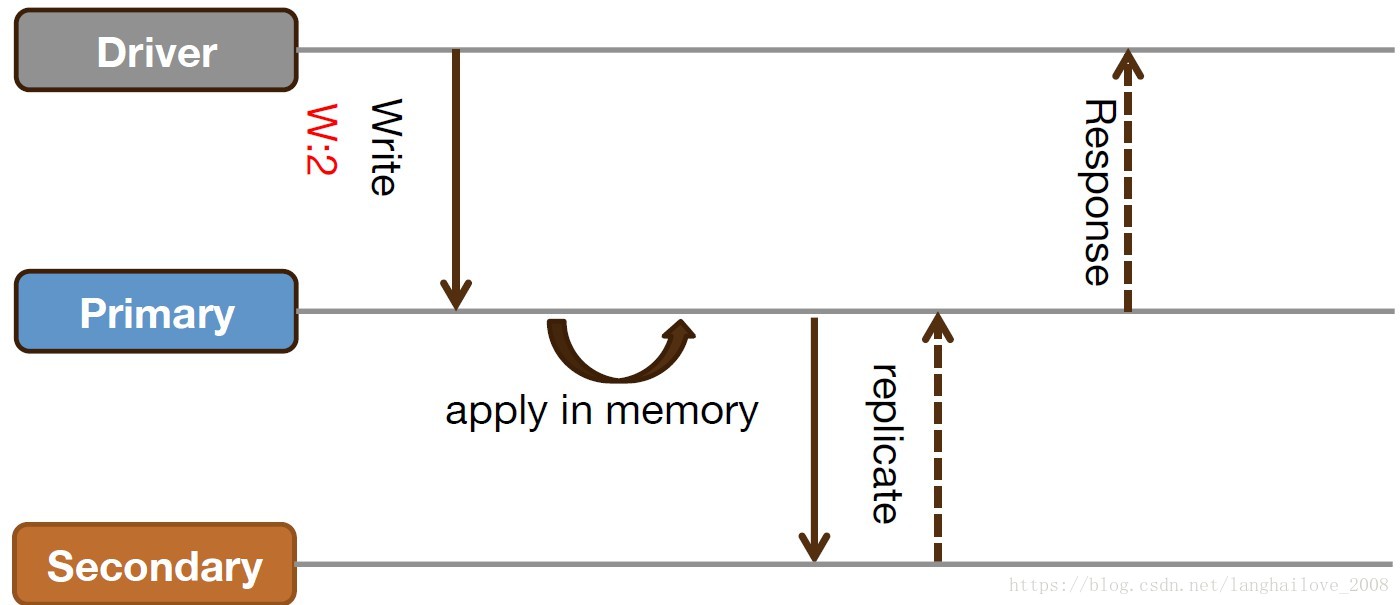
Wait for replicaHon majority(write concern:majority)
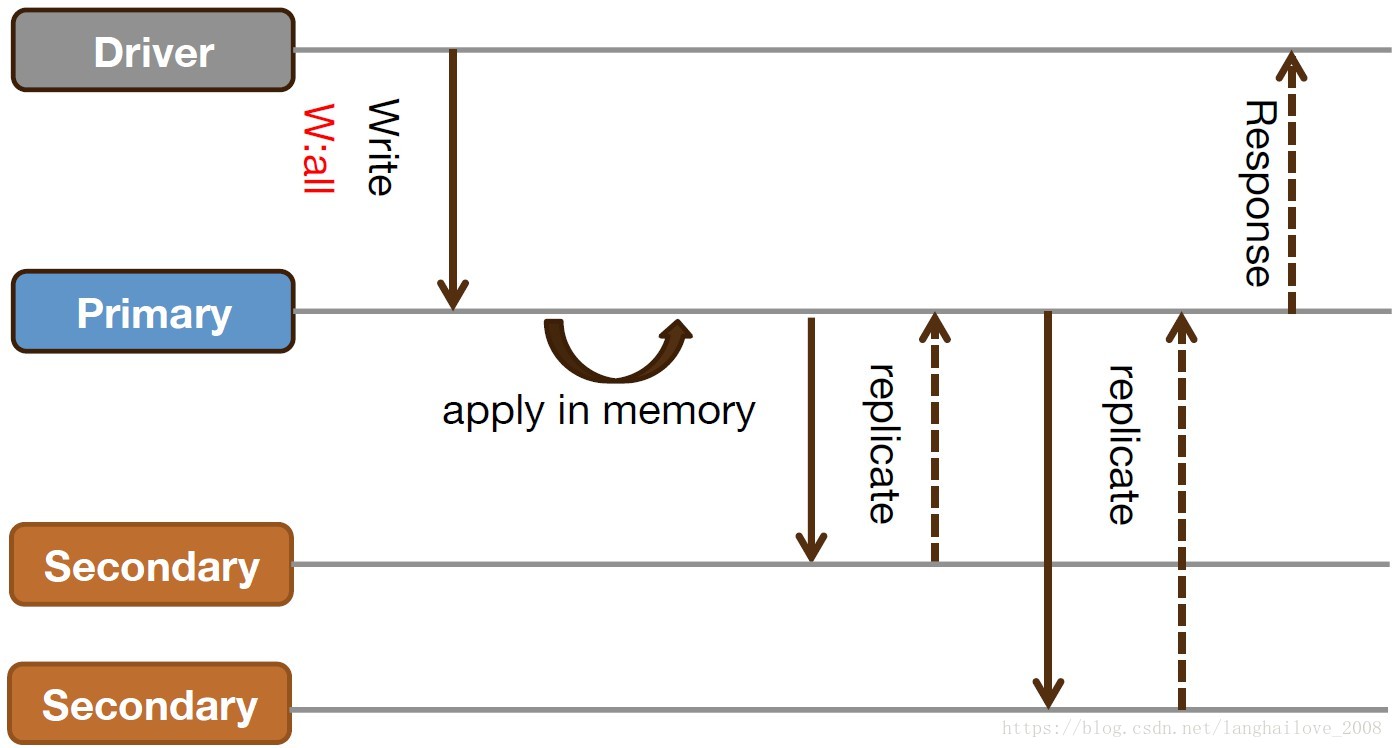
Wait for replicaHon all(write concern:all)
小结
• Primary和Secondary放在不同的机架或机房,以便容灾
• Write Concern就是在写操作性能和可靠性之间做权衡
• ⾮非关键数据,建议使⽤用默认的w:1;关键数据,建议使⽤用w:1 & j:true
• 读写分离并不能有效提⾼高系统的承载能⼒力
那MongoDB如何提高系统的承载能力呢?
性能扩展的葵花宝典:分⽚片
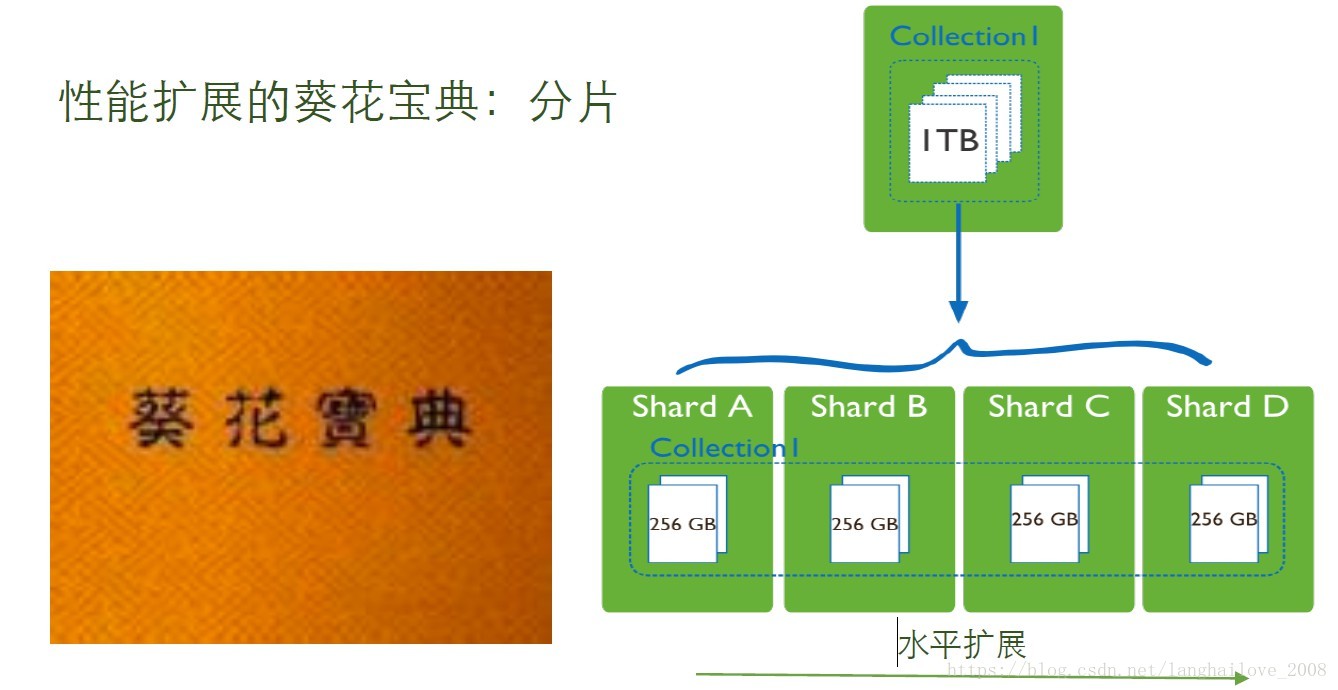
分⽚片⽤用来做什么
• 写性能扩展
• 读性能扩展!
• 地理分布数据
• 备份的快速恢复
分⽚片集群架构
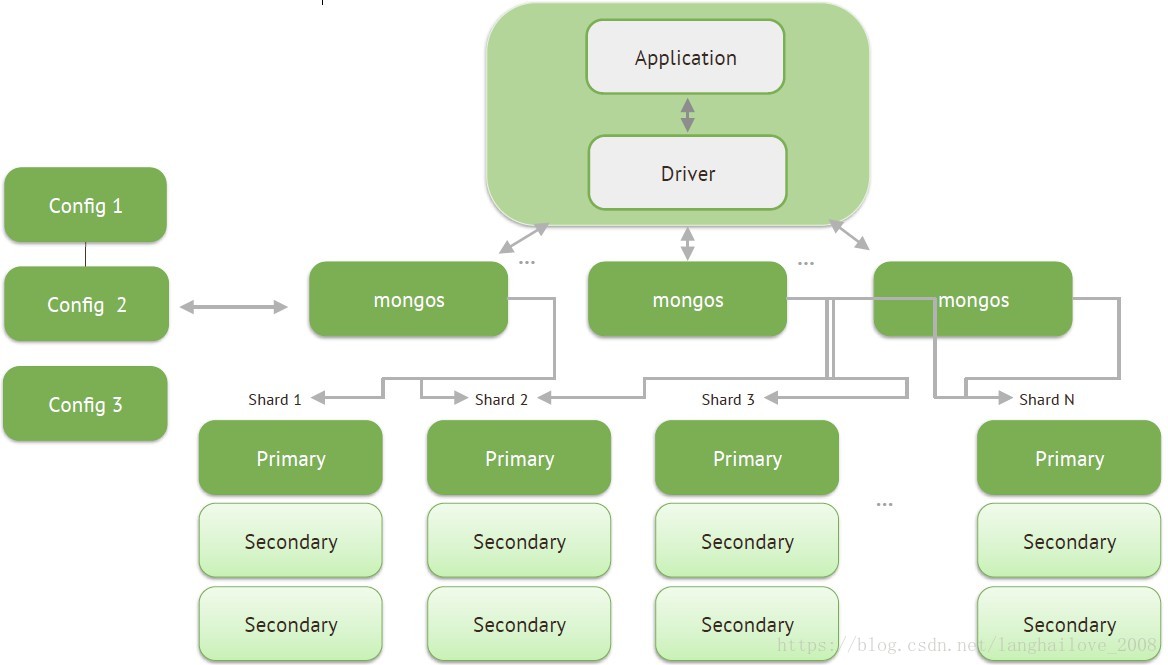
MongoDB 分⽚片技术原理
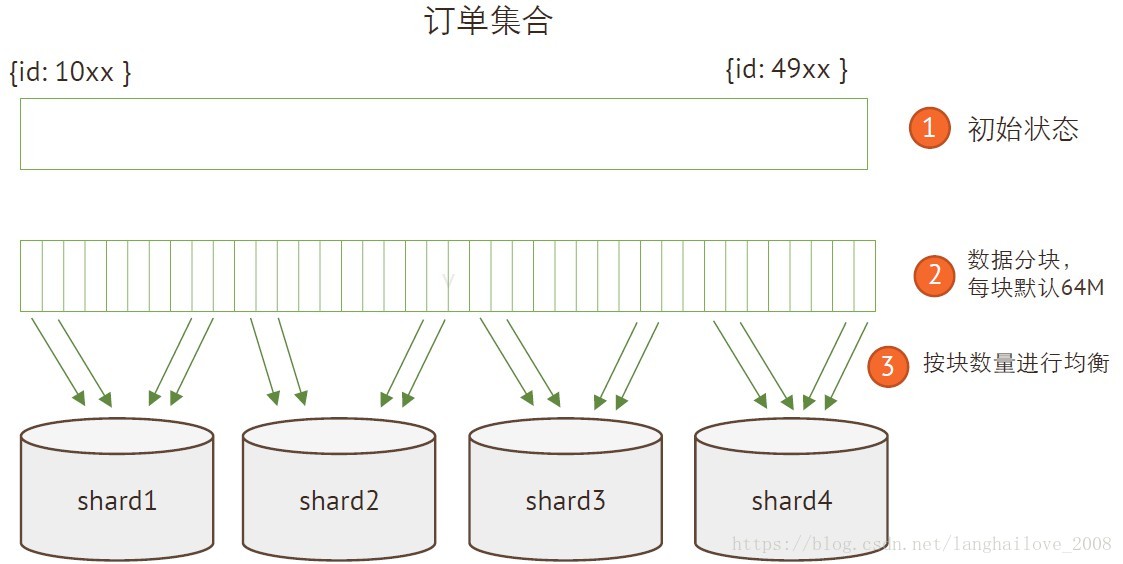
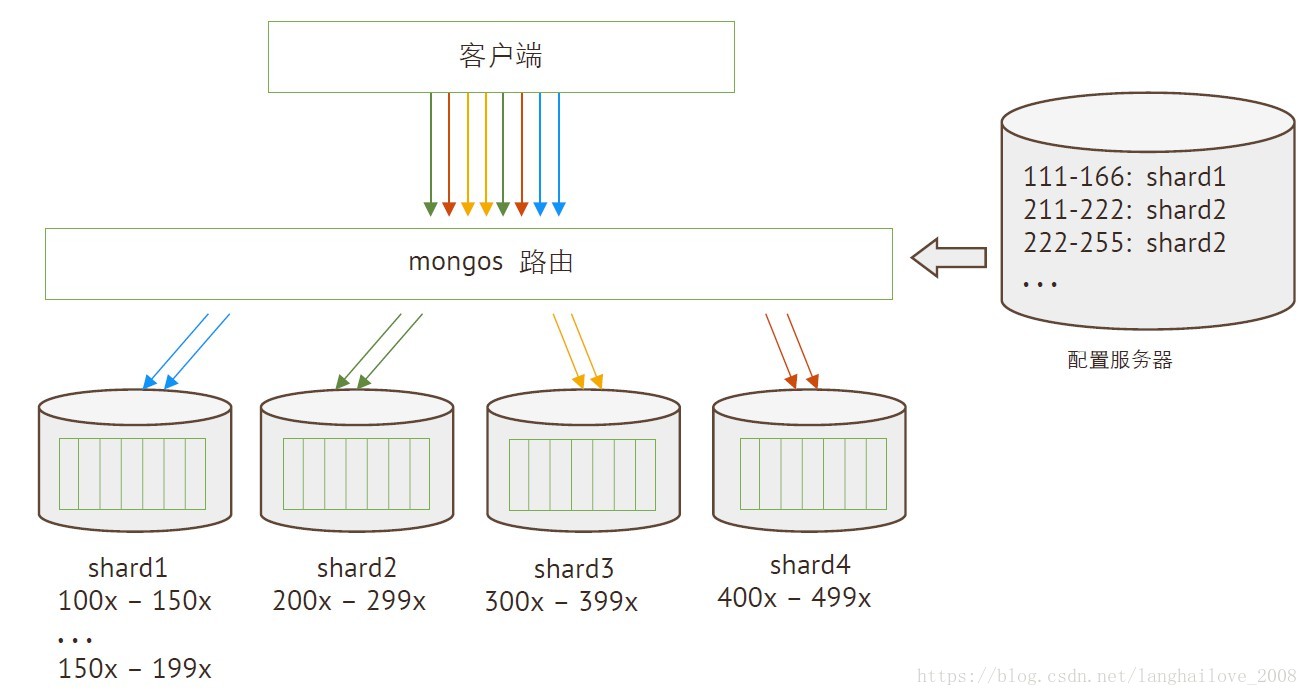
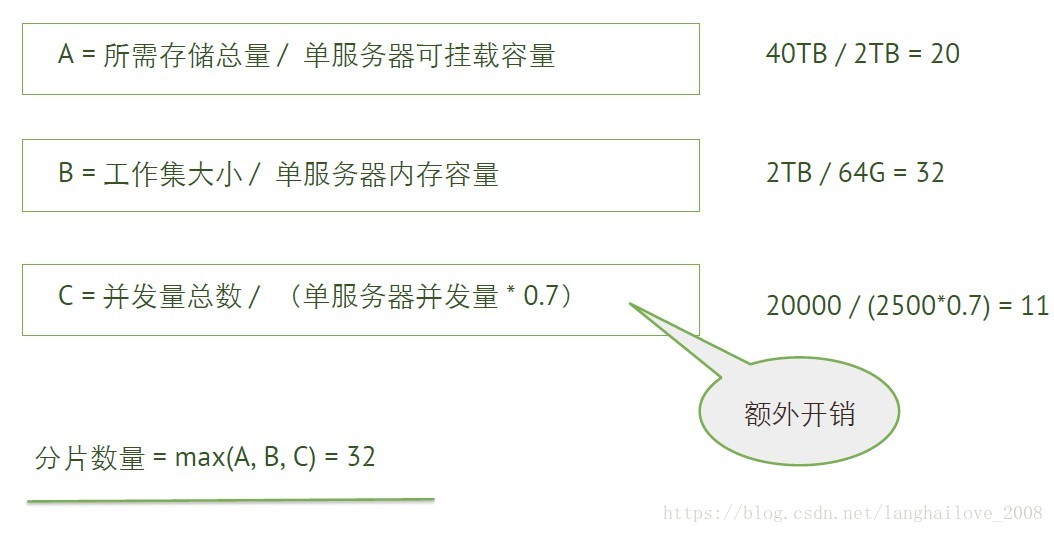
我需要多少个分⽚片?

分⽚片数量估算
我要⽤用哪种⽅方式分⽚片?
- 基于范围分⽚片
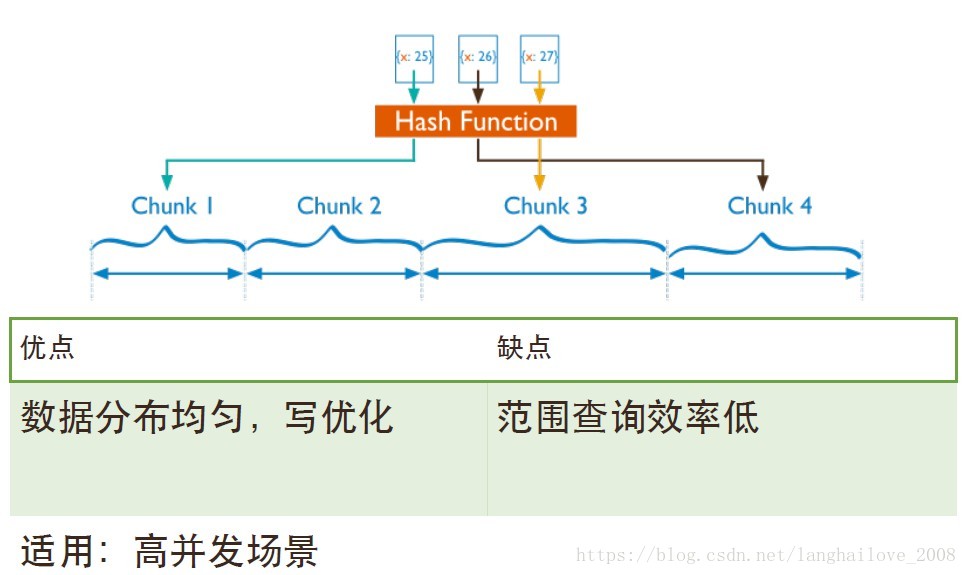
- 基于哈希值分⽚片
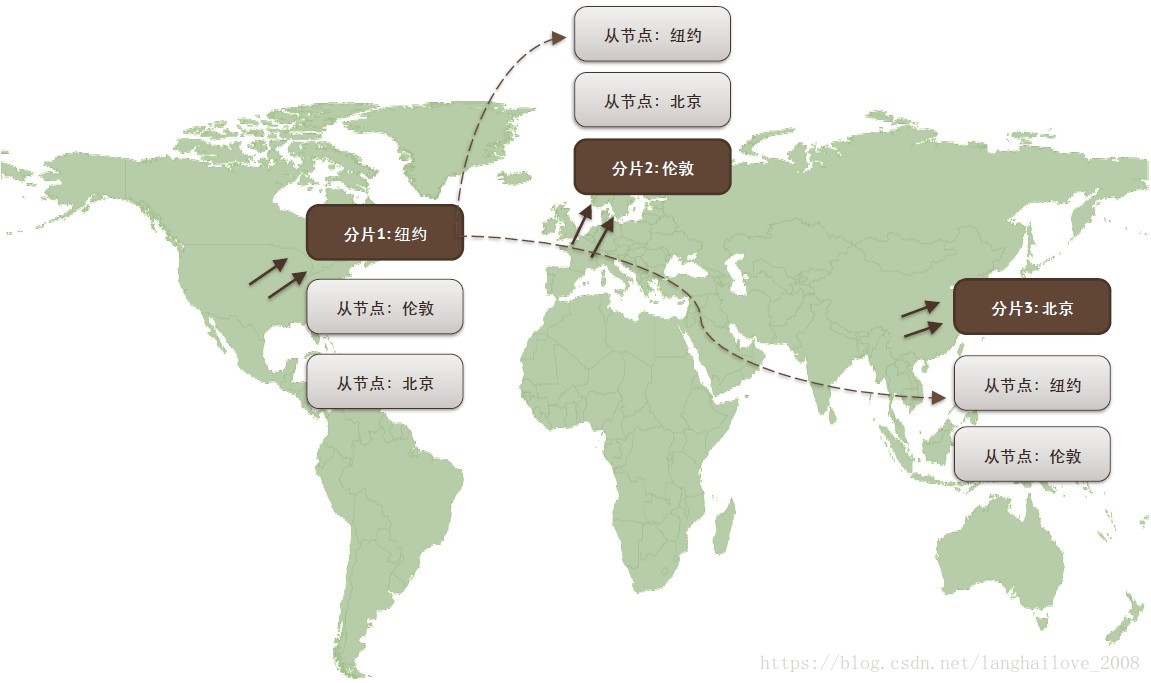
- 基于标签分⽚片

基于范围分⽚片

基于哈希分⽚片
标签分⽚片- 定制数据分布
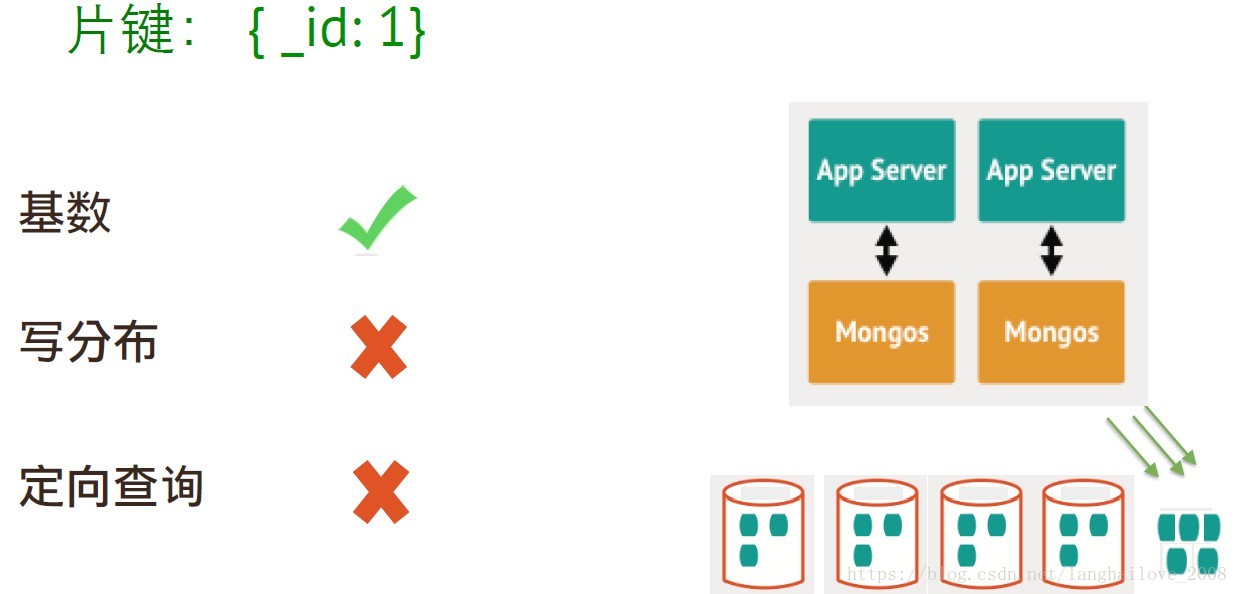
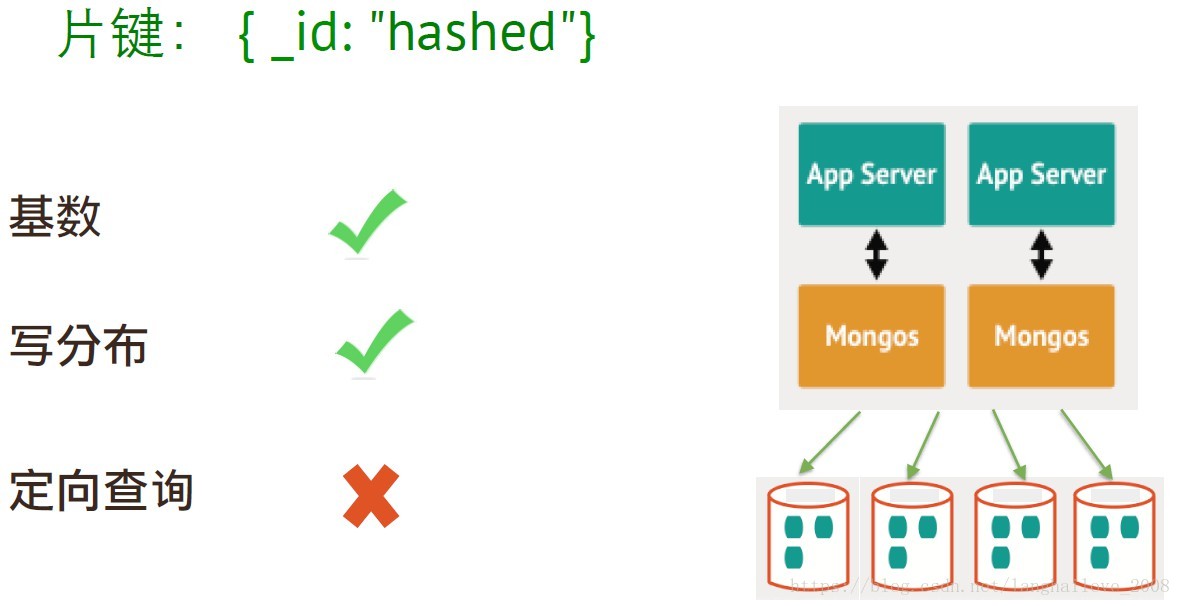
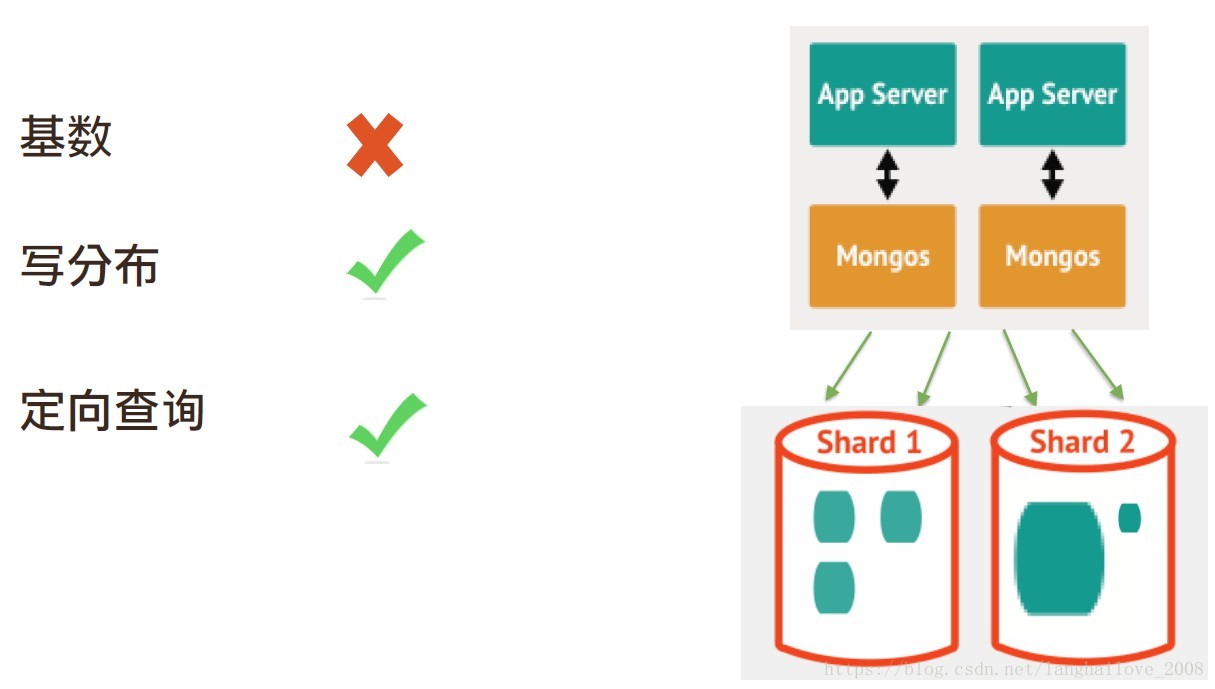
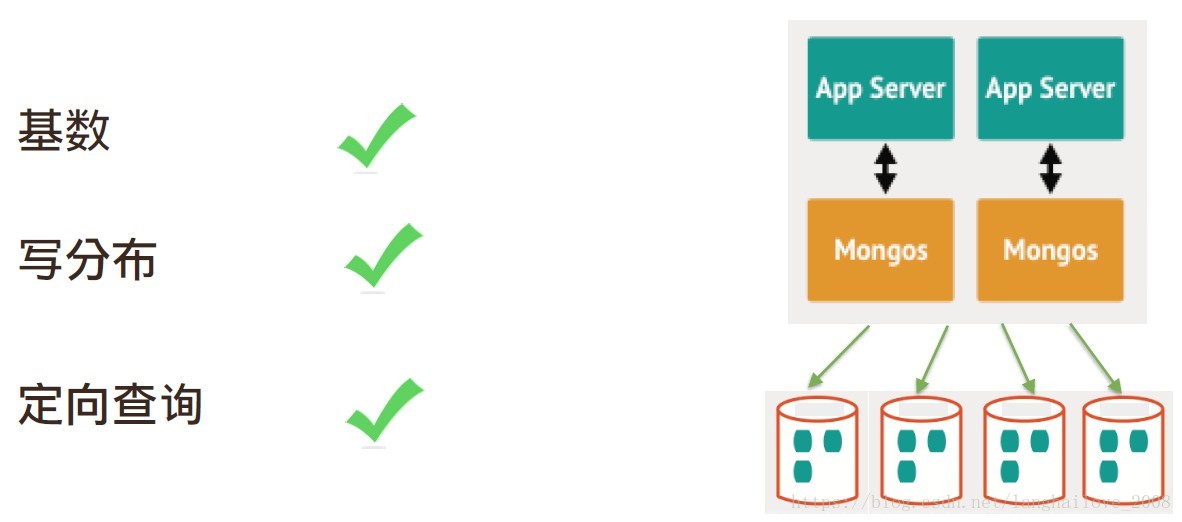
如何选择片键
片键的选择(分片的关键)
• 基数要大 (集合中⾮非重复值要多)
• 写操作分布均匀
• 查询定向性好
Email集合
{
_id: ObjectId(),
user: 123,
time: Date(),
subject: ”Test Subject”,
recipients: [”[email protected]”],
body: “Test Body“,
status:”OK”,
attachments: []
}片键: { _id: 1}
片键: { _id: “hashed”}
片键: { userid: 1}
片键: { userid:1,time:1 }
MongoDB在电商行业的应用
• 商品信息管理:商品属性及规格的⾃自由设定
• 用户关注
• 日志系统:flume>storm>mongodb
MongoDB在当当的应用
• 订单详情信息的读取响应时间平均在毫秒级,相比以前100毫秒左右的响应时长,提升了近100倍。
• 写入吞吐量每秒钟4000次以上,比之前的单mysql的能力(每秒在1000次左右)提升了近4倍。
• 故障转移,允许三分之一节点故障,不影响读写。
