如果把HTML的学习依序分为三个层次的话,应该是读懂、修改、编写。
【读懂】:只有读懂了HTML,我们才能看得懂网页结构,才有可能运用Python的其他模块去解析数据和提取数据。所以想写爬虫程序的话,一定要先学好HTML基础。
【修改】:在读懂HTML文档的基础上,学会修改HTML代码,是可以做些有趣的事情的,比如修改我女神的微博。看下图:
【编写】:如果达到了这个水平,那就可以去应聘前端工程师了,这是专业的程序员水平了。
当然,我们这一关的学习目标只要达到前两个——读懂HTML、能够修改HTML文档即可。
HTML是什么?
HTML(Hyper Text Markup Language)是用来描述网页的一种语言,也叫超文本标记语言 。
打个比方就更好理解了,HTML之于网页就好比建筑图纸之于建筑。
建筑图纸是建筑师设计房子时使用的语言,工匠会根据图纸内容,修建出它所描述的房子。
而HTML文档就是前端工程师设计网页时使用的语言,浏览器会根据HTML文档的描述,解析出它所描述的网页。
上一关,我们讲到向浏览器中输入某个网址后,浏览器会向服务器发出请求,然后服务器就会作出响应。其实,服务器返回给浏览器的这个结果就是HTML代码了。
而紧接着,浏览器会根据这个HTML代码,解析成我们所能看见的漂亮的网页。
查看网页的HTML代码
接下来,我们就来看看,每个漂亮的网页背后的HTML代码是怎样的,请一步一步跟着我操作。
注:下面我们的示范,会用谷歌浏览器(Chrome)进行演示,火狐浏览器(Firefox)的操作方式是一样的。推荐你也使用这二者之一。】

先打开我们的教学网站:人人都是蜘蛛侠。
https://wordpress-edu-3autumn.localprod.oc.forchange.cn/
在网页任意地方点击鼠标右键,然后点击“显示网页源代码”。(Windows系统的电脑还可以使用快捷键ctrl+u来查看网页源代码)

你会看到,浏览器弹出了一个新的标签页:

没错,这就是HTML源代码了。
这样查看的好处是,整个网页的源代码都完整地呈现在你面前。坏处是,在大部分情况下,它都会经过压缩,导致结构不够清晰,你不太容易懂每行代码的含义。而且,源代码和网页分开在两个页面展示。
所以更多时候,我们会用这样一种方法:
在网页的空白处点击右键,然后选择“检查”(快捷方式是ctrl+shift+i)。

接着,你会看到一个新的界面——开发者工具栏:
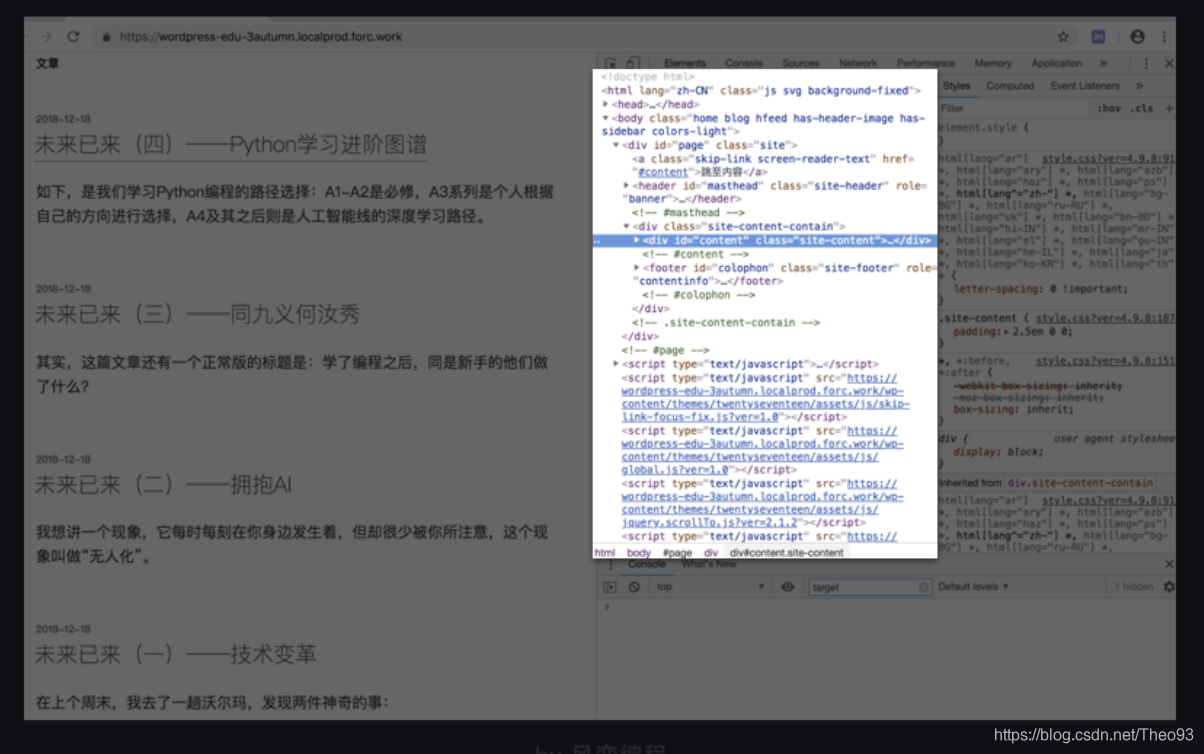
上图中标亮的部分就是网页的HTML代码。
将鼠标放在HTML源代码上,你会发现,左边网页上有一些内容会被标亮。这其实就是这行代码所描述的网页内容,它们一左一右,相互对应。

HTML的层级
尽管在HTML里面有一些陌生的符号和文字,但不要担心噢,HTML很好入门。
因为,万事万物都是有条理的。
先以房子为例:房子由不同楼层所组成,每一层中,都会包含一些房间,一个房间还可能划分为几个更小的房间,每个房间又是由门、窗、墙壁、地板等等构建组成的。

那么相对应的,建筑图纸也是由不同楼层的设计图所组成,而在每层楼的图纸中,又都详细描述了每个房间大小,以及门、窗的位置、尺寸、样式等等。
生活中是如此,在数据的世界中,这种组织的规则会更加明显。
所以HTML源代码之于网页,就像建筑图纸之于房子,会有鲜明的层级结构,以及互相对应的关系。
我们再回到刚才网页,仔细看开发者工具栏:

可以看到,HTML源代码中有一些小三角形,每一个三角形都可以展开或合上。尖角向下代表展开,向右代表合上了,这就是HTML的层级关系。
这每一个可以展开和合上的小三角形里包含的内容,都是一个层级,它很像电脑中一层一层的文件夹。

好,从整体上感受了HTML文档的特点后,我们再具体地看看HTML的组成。
HTML的组成
标签和元素
首先,我们一起看个最简单的HTML文档,感受一下。(提示:HTML代码在当前学习系统中可以直接同步显示渲染结果,点击运行之后会退出代码,进入下一条信息。)
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<h1>我是一级标题</h1>
<h2>我是二级标题</h2>
<h3>我是三级标题</h3>
<p>我是一个段落啦。一级标题、二级标题和我,我们三个一起组成了body。
</p>
</body>
</html>
好,回过头来先看HTML文档,可以看到很多夹在尖括号<>中间的字母,它们叫做【标签】。
标签通常是成对出现的:前面的是【开始标签】,比如;后面的是【结束标签】,如。
不过,也有标签是形单影只地出现,比如HTML代码的第四行(定义网页编码格式为 utf-8),就是此类。这些你知道就好,大部分情况下用的都是成双成对出现的标签。

事实上,开始标签+结束标签+中间的所有内容,它们在一起就组成了【元素】。

下面的表格列出了几个常见元素:

根据表格,请你回看一下上面那段HTML代码,里面就有
,
和
。你再对照看代码的显示结果,
是一级标题,
是二级标题,
是段落文本,它们一一对应。
你会在后面反复见到这些标签,我也会反复讲,最终,你肯定会对它们熟悉起来。
注意一下:HTML标签是可以嵌套标签的,而且可以多层嵌套;这就像是在电脑中,一个硬盘可以包含数个文件夹,文件夹中还可以嵌套文件夹。
网页头和网页体
事实上,HTML文档的基本是由【网页头】和【网页体】组成的:

HTML文档的最外层标签一定是,里面嵌套着元素与元素。元素代表了【网页头】,元素代表了【网页体】,这是最基本的网页结构。
HTML文档和网页的内容一定是一一对应的。只是,【网页头】的内容不会被直接呈现在浏览器里的网页正文中,而【网页体】的内容是会直接显示在网页正文中的。来具体看看:
先来看元素,也就是【网页头】,它里面一般会有哪些内容呢。
<head>
<meta charset="utf-8">
<title>我是网页的名字</title>
</head>
第2行的定义了HTML文档的字符编码。
第3行的

【网页头】中的编码是没办法在网页中直接被看到的,标签页的内容也不属于网页的正文。
而元素中,即【网页体】,就是那些你能看到的显示在网页中的内容了。
我写了一个简单的小网页,请对照HTML看效果:
<html>
<head>
<meta charset="utf-8">
<title>这个书苑不太冷1.0</title>
</head>
<body>
<h1>这个书苑不太冷</h1>
<h3>吴枫推荐的书:</h3>
<h2>《奇点遗民》</h2>
<p>本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。
</p>
</body>
</html>
此时,我们能看到这个HTML文档是由网页头和网页体组成的,网页头不显示在网页中。
而网页体中依次有四个内容:
元素代表一级标题,对应网页中的“这个书苑不太冷”;
元素代表三级标题,对应网页中的“吴枫推荐的书”;
元素代表二级标题,对应网页中的“奇点移民”;然后是
元素,对应网页中“本书精选…还有当下”这一整段文本。
恭喜!现在你已经基本掌握了HTML的标签与元素,以及由网页头和网页体组成的基本结构。
属性
现在,我们来玩一个找不同的游戏吧!我在刚才代码的基础上,添加了几行代码,试着找出和刚才1.0版本的不同。
<html>
<head>
<meta charset="utf-8">
<title>这个书苑不太冷2.0</title>
</head>
<body>
<h1 style="color:#20b2aa;">这个书苑不太冷</h1>
<h3>吴枫推荐的书:</h3>
<a href="https://wordpress-edu-3autumn.localprod.oc.forchange.cn/" target="_blank">点这里看看</a>
<br>
<h2>《奇点遗民》</h2>
<p>本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。
</p>
</body>
</html>
2.0和1.0相比,一共有两个不同:
元素中的文字添加了颜色;多增加了一个链接。其实啊,这些都是HTML【属性】的功劳。
(注意:HTML的属性和Python中的属性不是一个东西,不要搞混。)
HTML标签可以通过设置【属性】来为HTML元素描述更多的信息。比如上面用到的例子:
<h1 style="color:#20b2aa;">这个书苑不太冷</h1>
这行代码给
元素添加了一个style属性,属性中的内容规定了这行文字的颜色。

style属性可以用来定义网页文本的样式,比如字体大小、颜色、间距、对齐方式等等。
在上面的代码中,style属性添加在了
的开始标签中,因为属性通常都是在HTML元素的开始标签中设置的。
说完了style属性,看看href属性的用法——添加链接。
在HTML中,链接一般都由标签定义,href属性用于规定指向页面的URL,所以刚刚2.0的网页中就多了一个超链接。
除了style和href,HTML中还有两个很常用的属性,即class与id。
先看class的用法。我使用class属性,把刚才的代码2.0又升级为了3.0,下面是两个版本的HTML源代码,再玩一次找不同吧:
这个书苑不太冷2.0:
<html>
<head>
<meta charset="utf-8">
<title>这个书苑不太冷2.0</title>
</head>
<body>
<h1 style="color:#20b2aa;">这个书苑不太冷</h1>
<h3>吴枫推荐的书:</h3>
<a href="https://wordpress-edu-3autumn.localprod.oc.forchange.cn/">点这里看看</a>
<br>
<h2>《奇点遗民》</h2>
<p>本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。
</p>
</body>
</html>
这个书苑不太冷3.0:
<html>
<head>
<meta charset="utf-8">
<title>这个书苑不太冷3.0</title>
<style>
.book {
float: left;
margin: 5px;
padding: 15px;
width: 350px;
height: 240px;
border: 3px solid #20b2aa;
}
</style>
</head>
<body>
<h1 style="color:#20b2aa;">这个书苑不太冷</h1>
<h3>吴枫喜欢的书:</h3>
<a href="https://wordpress-edu-3autumn.localprod.oc.forchange.cn/">点这里看看</a>
<div class="book">
<h2>《奇点遗民》</h2>
<p>本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。
</p>
</div>
</body>
</html>
细心的你会看见,网页头中多了一个很长的
<style>
.book {
/*以下是.book的具体样式规定*/
float: left; /*控制元素浮动*/
margin: 5px; /*外边距为5像素*/
padding: 15px; /*内边距为15像素*/
width: 350px; /*宽度为350像素*/
height: 240px; /*高度为240像素*/
border: 3px solid #20b2aa; /*边框为3像素*/
}
</style>
</head>
<body>
<div id="header">
<h1 style="font-size:50px;">这个书苑不太冷</h1>
</div>
<div id="article">
<div id="nav">
<a href="#type1" class="catlog">科幻小说</a><br>
<a href="#type2" class="catlog">人文读物</a><br>
<a href="#type3" class="catlog">技术参考</a><br>
</div>
<div id="main">
<div class="books">
<h2><a name="type1">科幻小说</a></h2>
<a href="https://book.douban.com/subject/27077140/" class="title">《奇点遗民》</a>
<p class="info">本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。</p>
<img class="img" src="https://img3.doubanio.com/view/subject/l/public/s29492583.jpg">
<br/>
<br/>
<hr size="1">
</div>
<div class="books">
<h2><a name="type2">人文读物</a></h2>
<a href="https://book.douban.com/subject/26943161/" class="title">《未来简史》</a>
<p class="info">未来,人类将面临着三大问题:生物本身就是算法,生命是不断处理数据的过程;意识与智能的分离;拥有大数据积累的外部环境将比我们自己更了解自己。如何看待这三大问题,以及如何采取应对措施,将直接影响着人类未来的发展。</p>
<img class="img" src="https://img3.doubanio.com/view/subject/l/public/s29287103.jpg">
<br/>
<br/>
<hr size="1">
</div>
<div class="books">
<h2><a name="type3">技术参考</a></h2>
<a href="https://book.douban.com/subject/25779298/" class="title">《利用Python进行数据分析》</a>
<p class="info">本书含有大量的实践案例,你将学会如何利用各种Python库(包括NumPy、pandas、matplotlib以及IPython等)高效地解决各式各样的数据分析问题。由于作者Wes McKinney是pandas库的主要作者,所以本书也可以作为利用Python实现数据密集型应用的科学计算实践指南。本书适合刚刚接触Python的分析人员以及刚刚接触科学计算的Python程序员。</p>
<img class="img" src="ttps://img3.doubanio.com/view/subject/l/public/s27275372.jpg">
<br/>
<br/>
<hr size="1">
</div>
</div>
</div>
<div id="footer">Copyright © ForChange 风变科技
</div>
</body>
