简介
遗传算法(Genetic Algorithms,GA)是一种基于自然选择原理和自然遗传机制的搜索(寻优)算法,它是模拟自然界中的生命进化进制,在人工系统中实现特定目标而优化。遗传算法的实质是通过群体搜索技术,更具适者生存的原则逐代进化,最终得到最优解或准最优解。它必须做以下操作:初始群体的产生、求每一个体的适应度、根据适者生存的原则选择优良个体、被选出的优良个体两两配对,通过随机交叉其染色体的基因并随机变异某些染色体的基因生成下一代群体,按此方法使群体逐代进化,直到满足进化终止条件。
| 生物遗传概念 | 遗传算法中的作用 |
|---|---|
| 适者生存 | 算法停止时,最优目标值的可行解有最大可能被留住 |
| 个体 | 可行解 |
| 染色体 | 可行解的编码 |
| 基因 | 可行解中每一分量的特征 |
| 适应性 | 适应度函数 |
| 种群 | 根据适应度函数值选取的一组可行解 |
| 交配 | 通过交配原则产生一组新可行解的过程 |
| 变异 | 编码的某一分量发生变化的过程 |
——《数学建模算法与应用》(司守奎)
模型及算法
用遗传算法解决前面的文章实例2中提到的问题
种群大小M=50;最大代数G=1000;
交叉率\(p_c=1\),交叉概率为1能保证种群的充分进化;
变异率\(p_m=0.1\),一般而言,变异发生的可能性较小。
编码策略
采用十进制编码,用随机数列\(w_1,w_2,···,w_{21}\)作为染色体,其中\(0 \le w_i \le 1(i=2,3,···,20),w_1=0,w_21=1\);每一个随机序列都和种群中的一个个体一一相对应
初始种群
先利用经典的近似算法——改良圈算法求得一个较好的初始种群。
对于随机产生的初始圈
\[ C=C_1···C_{u-1}C_uC_{u+1}···C_{v-1}C_vC_{v+1}···C_{21} ,2 \le u < v \le 20,2 \le C_u <C_v \le 20 \]
交换 u 和 v 之间顺序,新的路径为
\[ C_1···C_{u-1}C_vC_{v+1}···C_{u+1}C_uC_{v+1}···C_{21} \]
记 \(\Delta f=(d_{c_{u-1}c_v}+d_{c_{u}c_{v+1}})-(d_{c_{u-1}c_u}+d_{c_{v}c_{v+1}})\),若\(\Delta f<0\),则以新路径修改旧的路径,直到不能够修改为止,就得到一个可行解直到产生M个可行解,并把这M个可行解转换成染色体编码
目标函数
目标函数为侦察所有目标的路径长度,适应度函数就取为目标函数。要求
\[ min f(C_1,···,C_{21})=\sum_{i=1}^{21}d_{c_ic_{i+1}} \]交叉操作
交叉操作采用单点交叉。对于选定的两个父代个体\(f_1=w_1w_2···w_{21},f_2=w_1^,w_2^,···w_{21}^,\)随机的选取第 t 个基因处为交叉点,则经过交叉运算后得到的子代个体为\(s_1\)和\(s_2,s_1\)的基因由\(f_1\)的前 t 个基因和\(f_2\)的后21 - t个基因构成,\(s_2\)的基因由\(f_2\)的前 t 个基因和\(f_1\)的后21 - t个基因构成。
变异操作
按照给定的变异率,对选定变异的个体,随机的选取三个整数,满足 1<u<v<w<21 ,把 u,v 之间(包括)的基因段插到 w的后面
选择
采用确定性的选择策略,也就是在父代种群和子代种群中选择目标函数值最小的M个个体进化到下一代,这样可以保证父代的优良特性被保存下来。
Matlab代码
clc,clear;
close all;
% 读取数据
data=load('data.txt');
x = data(:, 2);
y = data(:, 3);
start=[data(1,2),data(1,3)];
data = [data(:,[2 3]); start];
% 计算距离的邻接表
count = length(data(:, 1));
d = zeros(count); %距离矩阵d初始化
for i = 1:count-1
for j = i+1:count
d(i,j)=( sum( ( data( i , : ) - data( j , : ) ) .^ 2 ) ) ^ 0.5 ;
end
end
d =d + d'; % 对称 i到j==j到i
w=50; % 种群个数
g=100; % 进化代数
rand('state', sum(clock)); % 初始化随机数发生k器
% 通过改良图算法选取初始种群w
for k = 1:w
c = randperm(count-2); % 产生一个1-19的全排列
c1 = [1,c+1,count]; % 生成初始解
for t = 1:count % 修改圈
flag = 0; % 退出标志
for m = 1:count-2
for n = m+2:count-1
if d(c1(m),c1(n))+d(c1(m+1),c1(n+1)) < d(c1(m),c1(m+1))+d(c1(n),c1(n+1))
c1(m+1:n) = c1(n:-1:m+1);
flag = 1;
end
end
end
if flag == 0
J(k,c1)=1:count;
break % 记录下较好的解并退出当前循环
end
end
end
J(:,1) = 0;
J = J/count; % 把整数序列转换成[0,1]区间上的实数,即转换成染色体编码
% 遗传算法
for k = 1:g
A = J; % 交配产生子代A的初始染色体
c = randperm(w); % 产生下面交叉操作的染色体对
for i = 1:2:w
F = 2+floor((count-2)*rand(1)); % 产生交叉操作的地址
temp = A(c(i),[F:count]); % 中间变量的保存值
A(c(i+1), [F:count]) = A(c(i+1),[F:count]); % 交叉操作
A(c(i+1),F:count) = temp;
end
by = []; % 为了防止下面产生空地址,先初始化
while isempty(by)
by = find(rand(1,w)<0.1); % 产生变异操作的地址
end
B=A(by,:); % 产生变异操作的初始染色体
for j=1:length(by)
bw=sort(2+floor((count-2)*rand(1,3))); % 产生变异操作的3个地址
B(j,:)=B(j,[1:bw(1)-1,bw(2)+1:bw(3),bw(1):bw(2),bw(3)+1:count]);% 交换位置
end
G=[J;A;B]; % 父代和子代种群合在一起
[SG,ind1] = sort(G,2); % 把染色体翻译成1···21的序列ind1
num = size(G,1);
long = zeros(1,num); %路径长度的初始值
for j = 1:num
for i = 1:count-1
long(j)=long(j)+d(ind1(j,i),ind1(j,i+1)); % 计算每条路径长度
end
end
[slong,ind2]=sort(long); % 对路径长度从小打到排序
end
path = ind1(ind2(1),:);
flong=slong(1);
for i =1:count
data1(:, i) = data(path(1,i), :)';
end
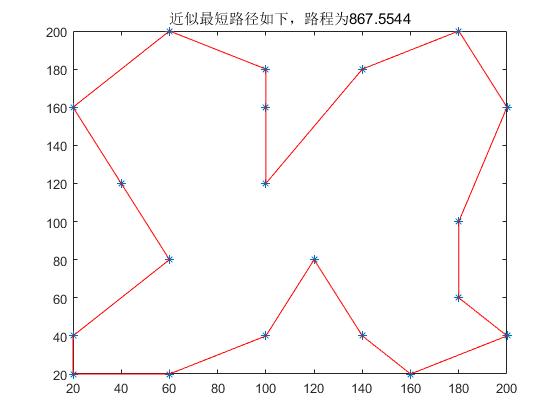
plot(x, y, '*', data1(1, :), data1(2, :), 'r');
title( [ '近似最短路径如下,路程为' , num2str( flong ) ] ) ;
disp(flong);