本篇博客记录使用Lucene的API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据),以完善我之前的记事本系统为例,直接上核心代码:
1、Lucene工具类
package com.ue.util;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.highlight.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.RAMDirectory;
/**
* @author LiJun
* @create 2019-07-02 18:23
*/
public class LuceneUtil {
/**
* 获取索引文件存放的文件夹对象
* @param path
* @return
*/
public static Directory getDirectory(String path) {
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(path));
} catch
(IOException e) {
e.printStackTrace();
}
return directory;
}
/**
* 索引文件存放在内存
* @return
*/
public static Directory getRAMDirectory() {
Directory directory = new RAMDirectory();
return directory;
}
/**
* 文件夹读取对象
* @param directory
* @return
*/
public static DirectoryReader getDirectoryReader(Directory directory) {
DirectoryReader reader = null;
try {
reader = DirectoryReader.open(directory);
} catch
(IOException e) {
e.printStackTrace();
}
return reader;
}
/**
* 文件索引对象
*
* @param reader
* @return
*/
public static IndexSearcher getIndexSearcher(DirectoryReader reader) {
IndexSearcher indexSearcher = new IndexSearcher(reader);
return indexSearcher;
}
/**
* 写入索引对象
*
* @param directory
* @param analyzer
* @return
*/
public static IndexWriter getIndexWriter(Directory directory, Analyzer analyzer) {
IndexWriter iwriter = null;
try {
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
// Sort sort=new Sort(new SortField("content", Type.STRING));
// config.setIndexSort(sort);//排序
config.setCommitOnClose(true);
// 自动提交
// config.setMergeScheduler(new ConcurrentMergeScheduler());
// config.setIndexDeletionPolicy(new
// SnapshotDeletionPolicy(NoDeletionPolicy.INSTANCE));
iwriter = new IndexWriter(directory, config);
} catch
(IOException e) {
e.printStackTrace();
}
return iwriter;
}
/**
* 关闭索引文件生成对象以及文件夹对象
*
* @param indexWriter
* @param directory
*/
public static void close(IndexWriter indexWriter, Directory directory) {
if (indexWriter != null) {
try {
indexWriter.close();
} catch
(IOException e) {
indexWriter = null;
}
}
if (directory != null) {
try {
directory.close();
} catch
(IOException e) {
directory = null;
}
}
}
/**
* 关闭索引文件读取对象以及文件夹对象
*
* @param reader
* @param directory
*/
public static void close(DirectoryReader reader, Directory directory) {
if (reader != null) {
try {
reader.close();
} catch
(IOException e) {
reader = null;
}
}
if (directory != null) {
try {
directory.close();
} catch
(IOException e) {
directory = null;
}
}
}
/**
* 高亮标签
*
* @param query
* @param fieldName
* @return
*/
public static Highlighter getHighlighter(Query query, String fieldName) {
Formatter formatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");
Scorer fragmentScorer = new QueryTermScorer(query, fieldName);
// QueryScorer fragmentScorer=new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, fragmentScorer);
highlighter.setTextFragmenter(new SimpleFragmenter(200));
return highlighter;
}
}
2、对某一表进行索引操作的帮助类
package com.ue.component;
import com.ue.model.Diary;
import com.ue.service.DiaryService;
import com.ue.util.DateUtil;
import com.ue.util.LuceneUtil;
import com.ue.util.StringUtils;
import org.apache.commons.io.FileUtils;
import org.apache.commons.lang3.StringEscapeUtils;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.*;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.store.Directory;
import org.jsoup.Jsoup;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.io.File;
import java.io.StringReader;
import java.util.*;
import static com.ue.config.CommonConfig.INDEXPATH;
/**
* @author LiJun
* @create 2019-07-02 21:16
* 将所有的日记生成索引文件进行存储
*/
@Component
public class DiaryIndex {
@Autowired
private DiaryService diaryService;
/**
* 添加日记索引(发表日记的时候添加索引信息)
* @throws Exception
*/
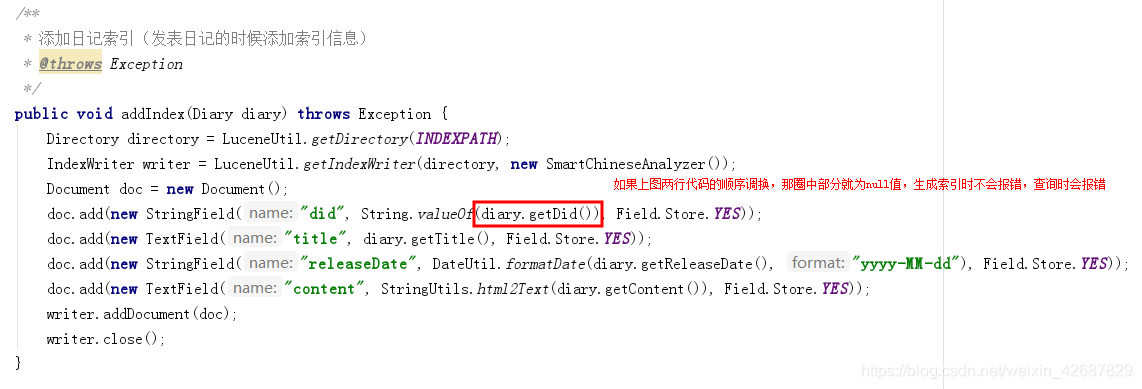
public void addIndex(Diary diary) throws Exception {
Directory directory = LuceneUtil.getDirectory(INDEXPATH);
IndexWriter writer = LuceneUtil.getIndexWriter(directory, new SmartChineseAnalyzer());
Document doc = new Document();
doc.add(new StringField("did", String.valueOf(diary.getDid()), Field.Store.YES));
doc.add(new TextField("title", diary.getTitle(), Field.Store.YES));
doc.add(new StringField("releaseDate", DateUtil.formatDate(diary.getReleaseDate(), "yyyy-MM-dd"), Field.Store.YES));
doc.add(new TextField("content", StringUtils.html2Text(diary.getContent()), Field.Store.YES));
writer.addDocument(doc);
writer.close();
}
/**
* 删除指定日记的索引
* @param did
* @throws Exception
*/
public void deleteIndex(String did) throws Exception {
Directory directory = LuceneUtil.getDirectory(INDEXPATH);
IndexWriter writer = LuceneUtil.getIndexWriter(directory, new SmartChineseAnalyzer());
writer.deleteDocuments(new Term("did", did));
writer.forceMergeDeletes();//强制删除
writer.commit();
writer.close();
}
/**
* 更新日记索引
* @throws Exception
*/
public void updateIndex(Diary diary) throws Exception {
Directory directory = LuceneUtil.getDirectory(INDEXPATH);
IndexWriter writer = LuceneUtil.getIndexWriter(directory, new SmartChineseAnalyzer());
Document doc = new Document();
doc.add(new StringField("did", String.valueOf(diary.getDid()), Field.Store.YES));
doc.add(new TextField("title", diary.getTitle(), Field.Store.YES));
doc.add(new StringField("releaseDate", DateUtil.formatDate((Date) diary.getReleaseDate(), "yyyy-MM-dd"), Field.Store.YES));
doc.add(new TextField("content", StringUtils.html2Text(diary.getContent()), Field.Store.YES));
writer.updateDocument(new Term("did", String.valueOf(diary.getDid())), doc);
writer.close();
}
/**
* 将数据库中所有的日记进行索引,然后存储索引文件到指定的位置
* 当索引文件丢失的时候使用
*/
public void indexDiarys() throws Exception {
System.out.println("-------------------------开始生成索引-------------------------");
File file = new File(INDEXPATH);
Directory directory = null;
IndexWriter indexWriter = null;
if (file != null) {
FileUtils.deleteDirectory(file);
directory = LuceneUtil.getDirectory(INDEXPATH);
indexWriter = LuceneUtil.getIndexWriter(directory, new SmartChineseAnalyzer());
List<Map<String, Object>> maps = diaryService.listPager(null, null);
String contentText = "";
for (Map diary : maps) {
Document doc = new Document();
doc.add(new StringField("did", String.valueOf(diary.get("did")), Field.Store.YES));
doc.add(new TextField("title", (String) diary.get("title"), Field.Store.YES));
doc.add(new StringField("releaseDate", DateUtil.formatDate((Date) diary.get("releaseDate"), "yyyy-MM-dd"), Field.Store.YES));
contentText = Jsoup.parse((String) diary.get("content")).text();
doc.add(new TextField("content", contentText, Field.Store.YES));
indexWriter.addDocument(doc);
}
}
LuceneUtil.close(indexWriter, directory);
System.out.println("-------------------------结束生成索引-------------------------");
}
/**
* 按关键字索引日记
* @param q
* @return
* @throws Exception
*/
public List<Diary> searchDiary(String q) throws Exception {
Directory directory = LuceneUtil.getDirectory(INDEXPATH);
DirectoryReader reader = LuceneUtil.getDirectoryReader(directory);
IndexSearcher searcher = LuceneUtil.getIndexSearcher(reader);
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();
//拿一句话到索引目中的索引文件中的词库进行关键词碰撞
Query query = new QueryParser("title", analyzer).parse(q);
Query query2 = new QueryParser("content", analyzer).parse(q);
BooleanQuery.Builder booleanQuery = new BooleanQuery.Builder();
booleanQuery.add(query, BooleanClause.Occur.SHOULD);
booleanQuery.add(query2, BooleanClause.Occur.SHOULD);
//优先高亮title
Highlighter highlighter = LuceneUtil.getHighlighter(query, "title");
//组合高亮
TopDocs topDocs = searcher.search(booleanQuery.build(), 100);
//处理得分命中的文档
List<Diary> diaryList = new ArrayList<>();
Diary diary = null;
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
diary = new Diary();
diary.setDid(Integer.valueOf(doc.get("did")));
diary.setReleaseDateStr(doc.get("releaseDate"));
String title = doc.get("title");
String content = StringEscapeUtils.escapeHtml4(doc.get("content"));
if (title != null) {
TokenStream tokenStream = analyzer.tokenStream("title", new StringReader(title));
String hTitle = highlighter.getBestFragment(tokenStream, title);
if (StringUtils.isBlank(hTitle)) {
diary.setTitle(title);
} else {
diary.setTitle(hTitle);
}
}
if (content != null) {
TokenStream tokenStream = analyzer.tokenStream("content", new StringReader(content));
String hContent = highlighter.getBestFragment(tokenStream, content);
if (StringUtils.isBlank(hContent)) {
if (content.length() <= 200) {
diary.setContent(content);
} else {
diary.setContent(content.substring(0, 200));
}
} else {
diary.setContent(hContent);
}
}
diaryList.add(diary);
}
LuceneUtil.close(reader, directory);
return diaryList;
}
}
3、对应的controller层、service实现类代码(因为我有部分逻辑是在service实现类里进行处理的)
- controller层:
/**
* 保存或者修改日记
* @param req
* @param diary
* @return
*/
@RequestMapping("/save")
public String save(HttpServletRequest req,Diary diary) {
this.diaryService.save(diary);
req.setAttribute("view", "/diary/edit");
return "redirect:/user/mainTemp";
}
/**
* 删除日记
* @param req
* @param did
* @return
*/
@RequestMapping("/del/{did}")
public String del(HttpServletRequest req,@PathVariable("did")Integer did) {
this.diaryService.del(did);
return "redirect:/user/mainTemp";
}
/**
* 将全部的博客索引文件重新生成
* @return
*/
@ResponseBody
@RequestMapping("/indexDiarys")
public Map indexDiarys(){
Map map = new HashMap();
try {
diaryIndex.indexDiarys();
map.put("success",true);
} catch (Exception e) {
e.printStackTrace();
}
return map;
}
/**
* 根据关键字查询相关博客信息
* @param q
* @return
* @throws Exception
*/
@RequestMapping("/q")
public ModelAndView search(@RequestParam(value="q",required=false) String q, HttpServletRequest request)throws Exception{
PageBean pageBean = new PageBean();
pageBean.setRequest(request);
ModelAndView mav=new ModelAndView("mainTemp");
mav.addObject("view", "/diary/result");
//开始索引日记
List<Diary> diaryList=diaryIndex.searchDiary(q);
pageBean.setTotal(diaryList.size());
int endIndex = Math.min(pageBean.getPage() * pageBean.getRows(), diaryList.size());
//查询出符合条件的所有记录然后进行截取
mav.addObject("diaryList", diaryList.subList(pageBean.getStartIndex(), endIndex));
//上一页、下一页的链接
mav.addObject("q", q);
mav.addObject("resultTotal", pageBean.getTotal());
mav.addObject("pageCode", PageUtil.createPageCode(pageBean));
return mav;
}- service实现类:
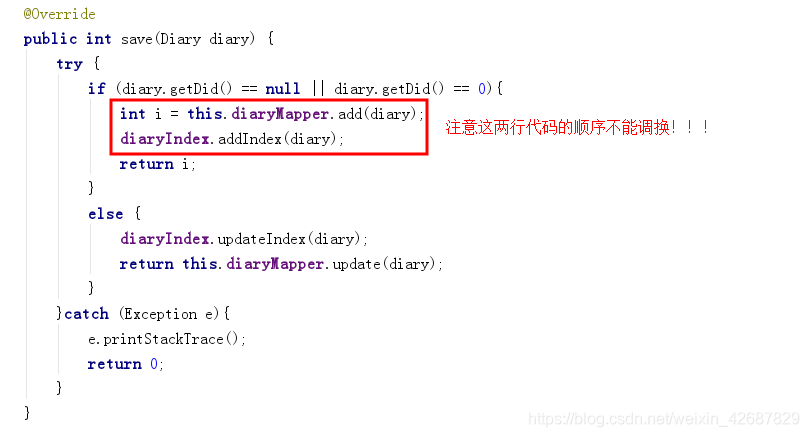
@Override
public int save(Diary diary) {
try {
if (diary.getDid() == null || diary.getDid() == 0){
int i = this.diaryMapper.add(diary);
diaryIndex.addIndex(diary);
return i;
}
else {
diaryIndex.updateIndex(diary);
return this.diaryMapper.update(diary);
}
}catch (Exception e){
e.printStackTrace();
return 0;
}
}
@Override
public int del(Integer did) {
try {
diaryIndex.deleteIndex(did + "");
} catch (Exception e) {
e.printStackTrace();
}
return this.diaryMapper.del(did);
}4、实现后的效果
这是我在之前的记事本系统的基础上将Lucene整合进来的,之前的效果:
https://blog.csdn.net/weixin_42687829/article/details/90550886
整合Lucene后的效果: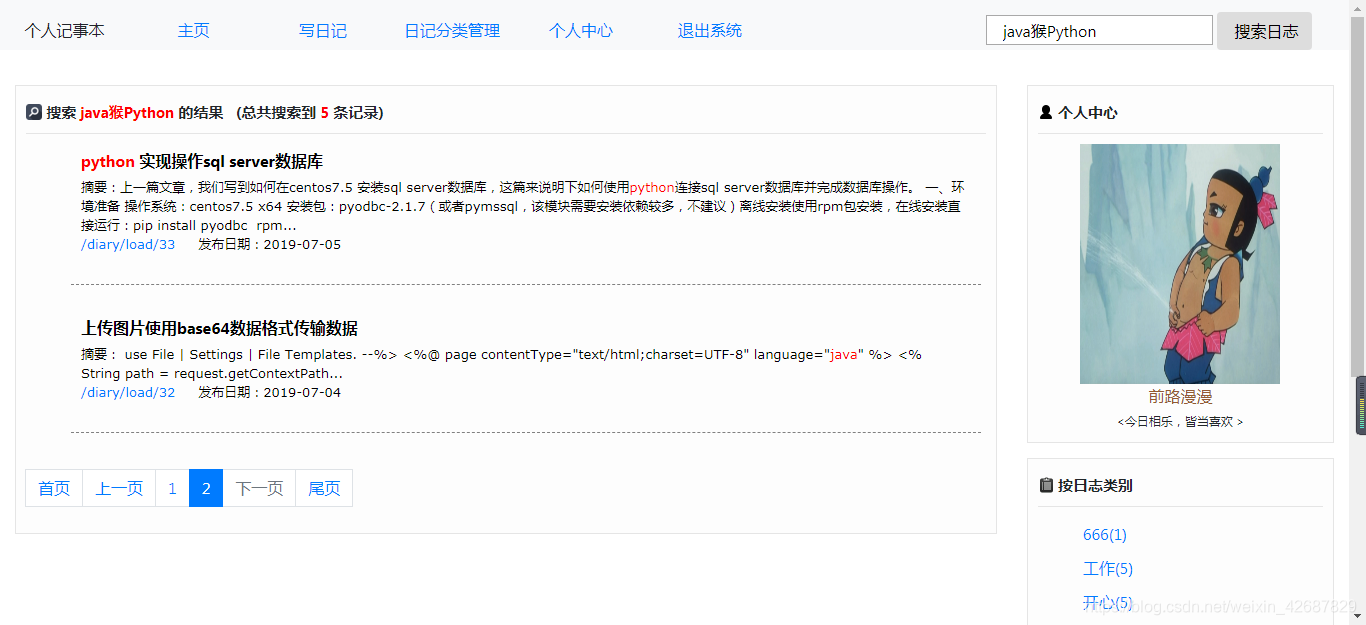
5、过程中需要注意的问题
扫描二维码关注公众号,回复:
9030163 查看本文章

