一、下载lucene的开发包
Lucene是开发全文检索功能的工具包,从官方网站下载Lucene4.10.3,并解压。
官方网站:http://lucene.apache.org/
版本:lucene4.10.3
Jdk要求:1.7以上
需要导的包:
Lucene包:
lucene-core-4.10.3.jar
lucene-analyzers-common-4.10.3.jar
lucene-queryparser-4.10.3.jar
其它:
commons-io-2.4.jar
junit-4.9.jar
二、创建索引库
第一步:创建一个java工程,并导入jar包。
第二步:创建一个indexwriter对象。
- 指定索引库的存放位置Directory对象
- 指定一个分析器,对文档内容进行分析。
第二步:创建document对象。
第三步:创建field对象,将field添加到document对象中。
第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。
第五步:关闭IndexWriter对象。
Field域的属性
是否分析:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
是否存储的标准:是否要将内容展示给用户
| Field类 |
数据类型 |
Analyzed 是否分析 |
Indexed 是否索引 |
Stored 是否存储 |
说明 |
| StringField(FieldName, FieldValue,Store.YES)) |
字符串 |
N |
Y |
Y或N |
这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) |
Long型 |
Y |
Y |
Y或N |
这个Field用来构建一个Long数字型Field,进行分析和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) |
重载方法,支持多种类型 |
N |
N |
Y |
这个Field用来构建不同类型Field 不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader)
|
字符串 或 流 |
Y |
Y |
Y或N |
如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
三、具体代码实现:
/**
*
* @author 阿荣
*lucene入门
*/
public class demo{
//创建索引
@Test
public void testIndex() throws IOException{
//指定索引的生成位置
Directory directory = FSDirectory.open(new File("D:\\lucene\\index"));
// 创建一个indexwriter对象。
//创建索引分析器
StandardAnalyzer analyzer = new StandardAnalyzer();
//创建indexConfig配置对象
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
//创建一个indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 指定索引库的源文件
File dir = new File("D:\\C盘迁移\\Desktop\\SSM框架\\Lucene&solr\\searchsource");
for(File f :dir.listFiles()){
// System.out.println(FileUtils.readFileToString(f));
//文件名
String fileName = f.getName();
//文件内容
String fileContent = FileUtils.readFileToString(f);
//文件路径
String filePath = f.getPath();
//文件的大小
long fileSize = FileUtils.sizeOf(f);
//将四项存入到索引域当中
//创建文件名域
//第一个参数:域的名称
//第二个参数:域的内容
//第三个参数:是否存储
Field fileNameField = new TextField("filename", fileName, Store.YES);
//文件内容域
Field fileContentField = new TextField("content", fileContent, Store.YES);
//文件路径域(不分析、不索引、只存储)
Field filePathField = new StoredField("path", filePath);
//文件大小域
Field fileSizeField = new LongField("size", fileSize, Store.YES);
//创建document对象
Document document = new Document();
document.add(fileNameField);
document.add(fileContentField);
document.add(filePathField);
document.add(fileSizeField);
//创建索引,并写入索引库
indexWriter.addDocument(document);
}
// 关闭IndexWriter对象。
indexWriter.close();
}
}四、通过IKAnalyzer2012FF_u1进行索引的分析
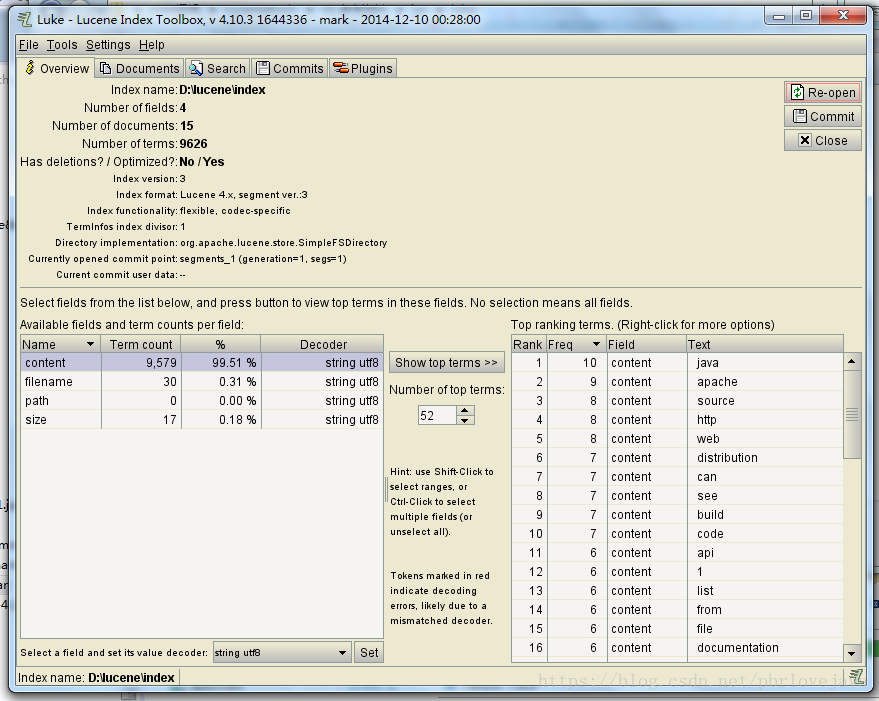
可知索引已经创建成功了,一共提取出了9579个题词(term)