第三章 线性模型
线性模型



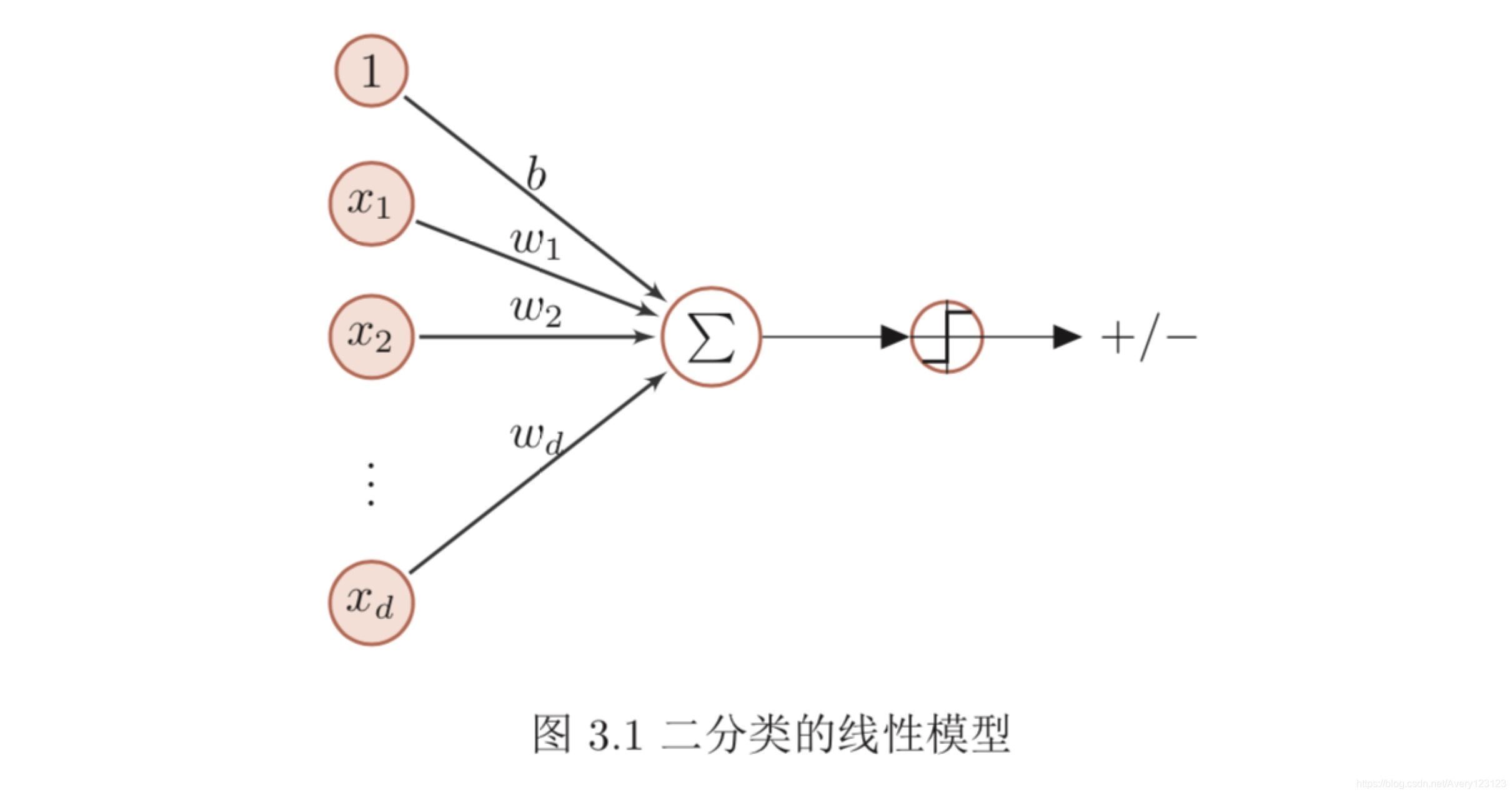
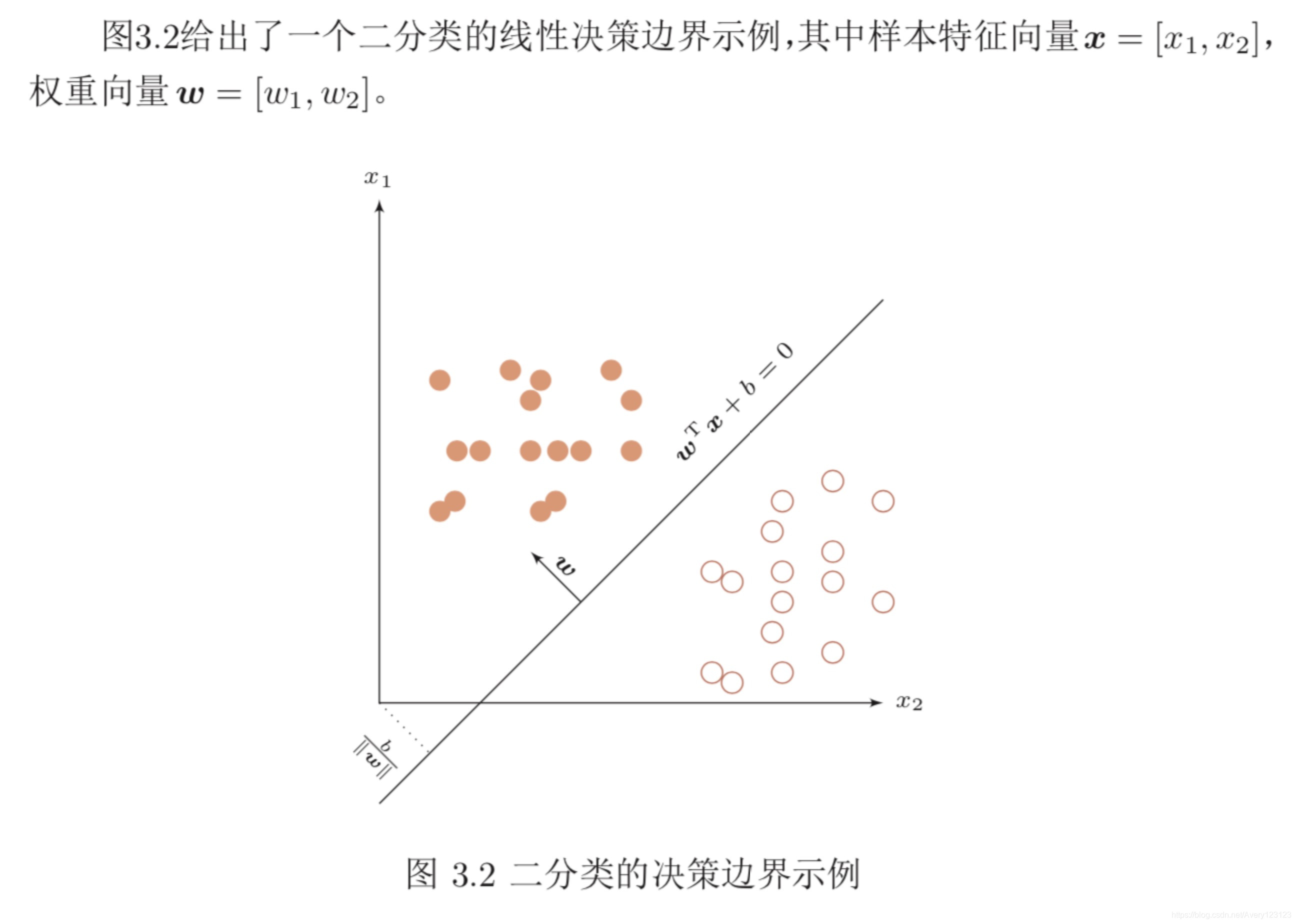
线性判别函数和决策边界

二分类


多分类

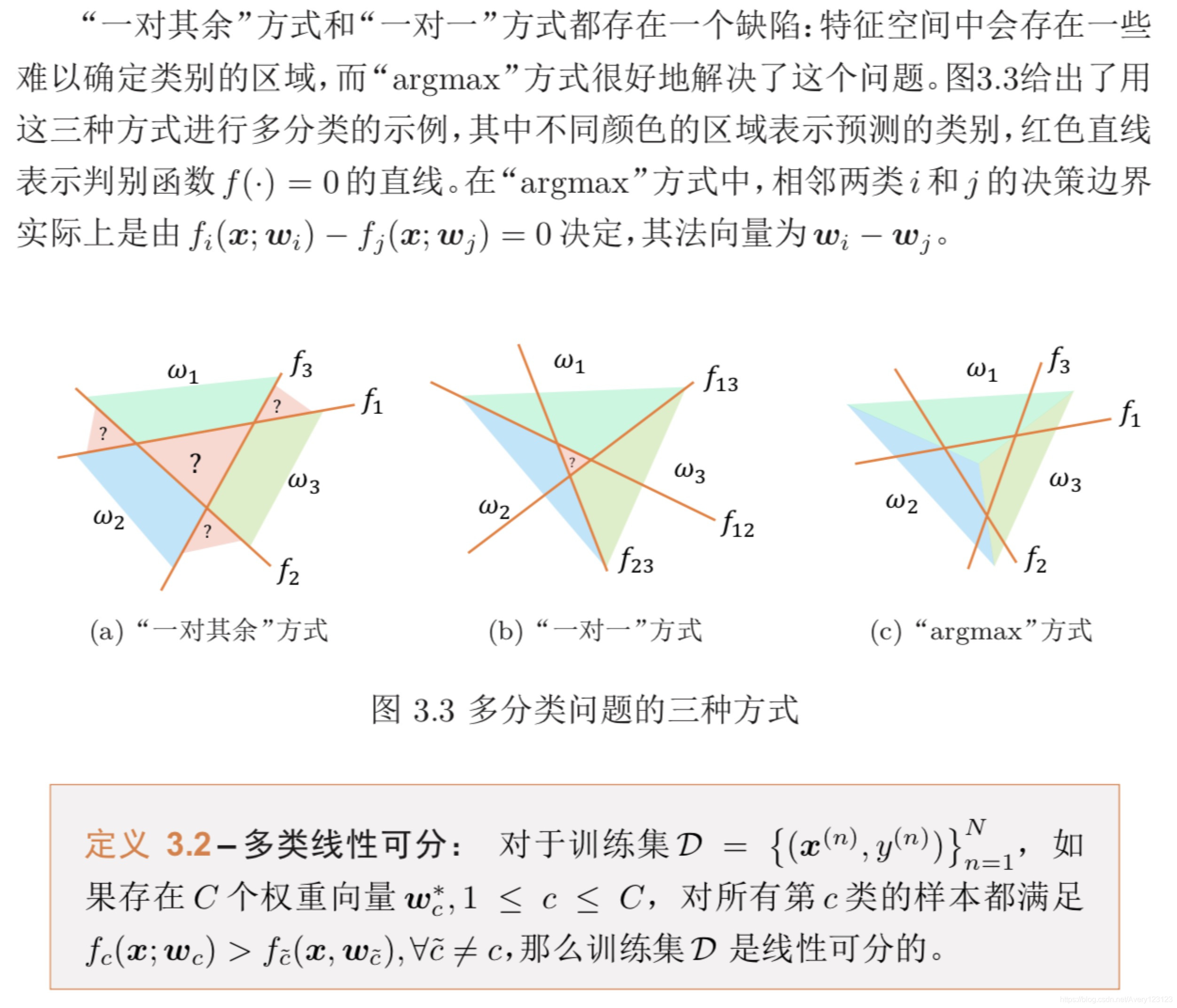
从上面定义可以得到,如果数据集是多类线性可分的,那么一定存在一个“argmax”方式的线性分类器可以将它们正确分开。
Logistic 回归



参数学习
Logistic 回归采用交叉熵作为损失函数,并使用梯度下降法来对参数进行
优化。


Softmax 回归
Softmax回归(Softmax Regression),也称为多项(Multinomial)或多类
(Multi-Class)的 Logistic 回归,是 Logistic 回归在多分类问题上的推广。

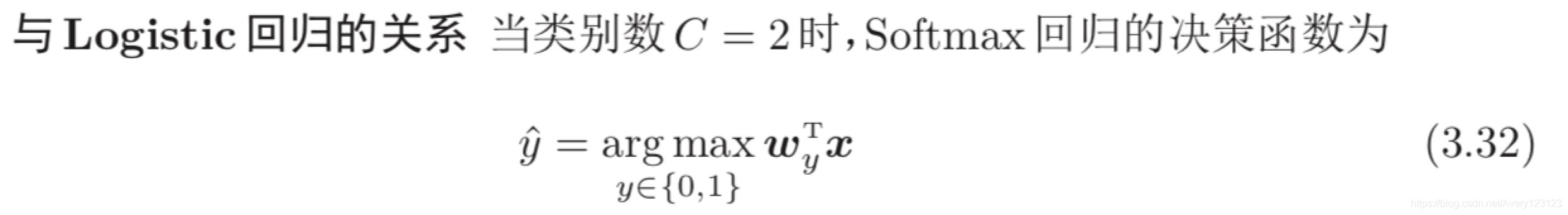

参数学习



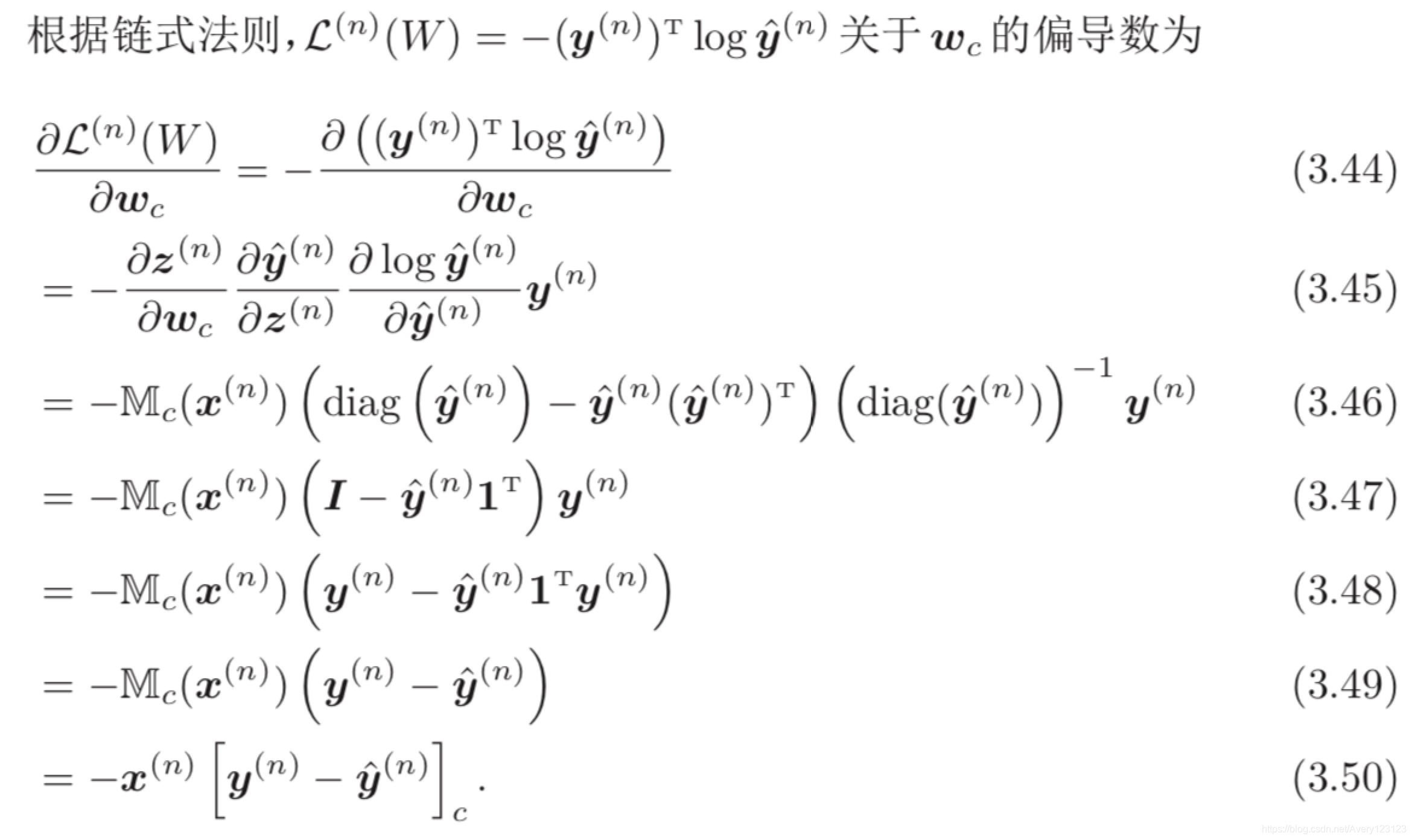

要注意的是,Softmax 回归中使用的 C 个权重向量是冗余的,即对所有的 权重向量都减去一个同样的向量 v,不改变其输出结果。因此,Softmax 回归往往需要使用正则化来约束其参数。此外,我们还可以利用这个特 性来避免计算 softmax 函数时在数值计算上溢出问题。
感知器

参数学习


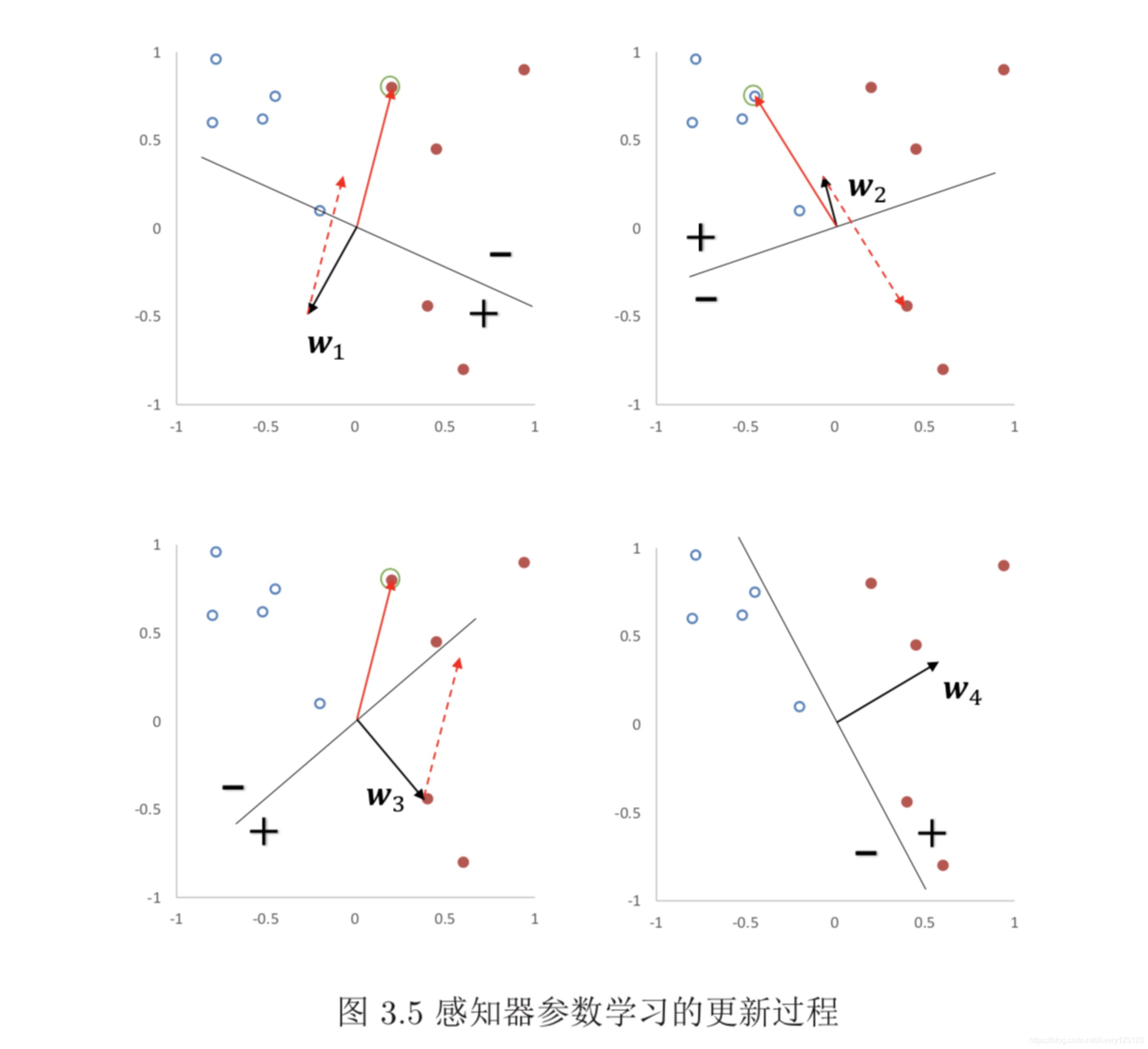
感知器的收敛性




参数平均感知器
根据定理3.1,如果训练数据是线性可分的,那么感知器可以找到一个判别 函数来分割不同类的数据。如果间隔 γ 越大,收敛越快。但是感知器并不能保证 找到的判别函数是最优的(比如泛化能力高),这样可能导致过拟合。
感知器学习到的权重向量和训练样本的顺序相关。在迭代次序上排在后面 的错误样本比前面的错误样本,对最终的权重向量影响更大。比如有 1 000 个训 练样本,在迭代 100 个样本后,感知器已经学习到一个很好的权重向量。在接下 来的 899 个样本上都预测正确,也没有更新权重向量。但是,在最后第 1 000 个样 本时预测错误,并更新了权重。这次更新可能反而使得权重向量变差。


扩展到多分类
原始的感知器是一种二分类模型,但也可以很容易地扩展到多分类问题,甚 至是更一般的结构化学习问题 [Collins,2002]。




广义感知器的收敛性
广义感知器在满足广义线性可分条件时,也能够保证在有限步骤内收敛。广 义线性可分条件的定义如下:

支持向量机


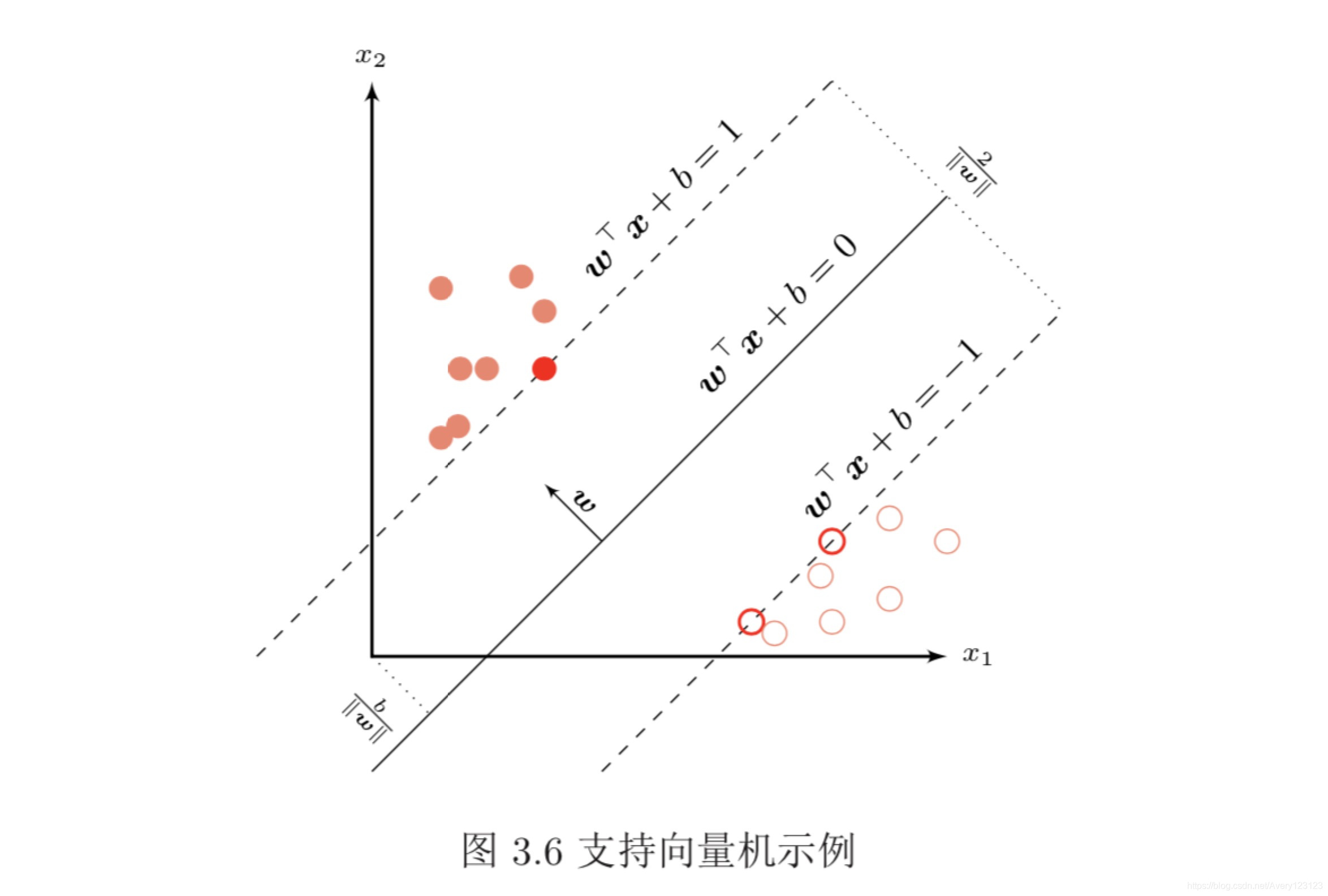
参数学习
核函数
软间隔
损失函数对比
本章介绍的三种二分类模型:Logistic 回归、感知器和支持向量机。虽然它们 的决策函数相同,但由于使用了不同的损失函数以及相应的优化方法,导致它们 在实际任务上的表现存在一定的差异。





