应用背景介绍:
自然语言具有时序特征,因此可以通过循环神经网络对自然语言进行处理。自然语言是以词、句、文章这些语言元素为单位的。python中最常用的word2vec工具是可以将单词转换成向量,将单词转换成向量的好处主要有以下两个:
(1)将单词向量化,实现数字化处理,从而直接通过神经网络进行计算;
(2)利用了向量之间的距离计算,从而可以计算出不同的单词之间的距离,从而不同的单词之间的关系可以用距离向量来表示。
提醒:
在进行训练之前,需要通过如下的语句安装gensim模块:
pip install gensim
本例代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import gensim
sentences = [['this', 'is', 'a', 'hot', 'pie'], ['this', 'is', 'a', 'cool', 'pie'],
['this', 'is', 'a', 'red', 'pie'], ['this', 'is', 'not', 'a', 'hot', 'pie']]
model = gensim.models.Word2Vec(sentences, min_count=1)
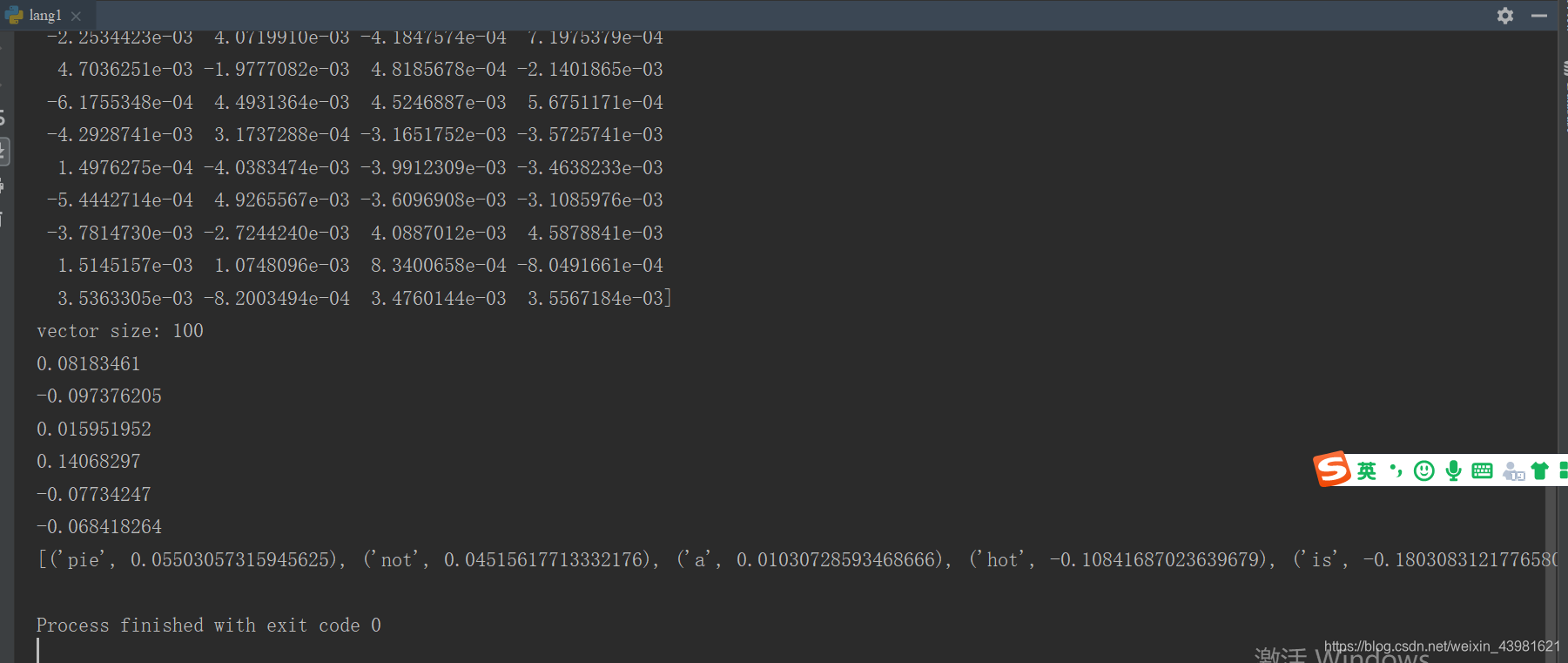
print(model.wv['this'])
print(model.wv['is'])
print('vector size:', len(model.wv['is']))
print(model.wv.similarity('this', 'is'))
print(model.wv.similarity('this', 'not'))
print(model.wv.similarity('this', 'a'))
print(model.wv.similarity('this', 'hot'))
print(model.wv.similarity('this', 'cool'))
print(model.wv.similarity('this', 'pie'))
print(model.wv.most_similar(positive=['cool', 'red'], negative=['this']))
代码说明:
(1)sentences 是本例中的训练数据,是4句话,并且是按照全小写,每个词分开的格式组成一个二维数组;
(2)model = gensim.models.Word2Vec(sentences, min_count=1)中的参数min_count官方的解释是:Ignores all words with total frequency lower than this,作用是忽略掉出现次数小于min_count的单词;
(3)print(model.wv[‘this’])输出’this’的单词向量,是一个100项数字组成的向量;
(4)print(model.wv.similarity(‘this’, ‘is’))输出单词’this’和‘is’的相似值;
(5)print(model.wv.most_similar(positive=[‘cool’, ‘red’], negative=[‘this’])),most_similar表示获取本模型中与指定单词最相近的词,其中positive表示指定需要寻找相近单词的词,negative用于指定希望与其相似度较远的单词。
运行结果如下: