神经网络NLP
对于自然语言处理技术,传统机器学习算法例如SVM、LR等,对映射到高维空间的文本特征进行处理,大部分应用在文本分类、情感分析等。近年来,一些非线性模型在自然语言处理来领域取得了极大的成功,这里简单介绍一些神经网络的背景知识以及在文本处理中的应用。
神经网络结构
常用于自然语言处理领域的神经网络结构包括:Feed-Forward network, Recurrent network, Recursive network等。
其中Feed Forward神经网络包括全连接的MLP、具有卷积层和池化层的CNN网络。RNN网络包括S-RNN、LSTM、GRU等,Recursive network是结合树模型的神经网络。
文本特征表示
使用神经网络最重要的就是明确输入输出是什么,输入需要量化成数学表示的向量或矩阵,便于神经网络计算。对于文本而言,最传统的表示方式是One-hot表示,即建立一个N维的词典,然后文本中出现某个单词,就用1表示,从而表示这个特征。但这种表示方式不能明确词语之间的相似性,另外还导致特征空间过大,不便于计算。现在出现了各种embedded的方法,就是把主要特征映射到某一特征空间,用向量表示,相似词语在该空间中距离较近,能够明确词语之间的相似性。常见的表示工具有谷歌的word2vec工具。
得到文本的特征表示后,使用神经网络进行文本分类步骤:
(1)针对文本需要划分的输出类,进行相关特征提取;
(2)针对提取的特征(可能是词语、词性、语言模型等),将其数学表示、向量化;
(3)把所有特征的向量表示拼接;
(4)将拼接得到的特征表示输入到神经网络,使用已标记的训练数据集合进行神经网络参数训练
前馈神经网络
全连接MLP网络
1. 网络框架
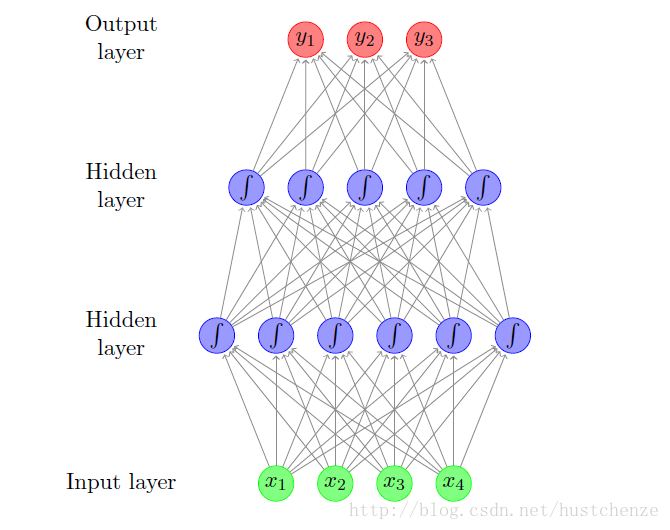
2.输入输出对应关系
每一个计算单元都是一个感知机,感知机的输入一般表示为
感知机的输出可以表示为:
因此对于上图中输出可以表示为:
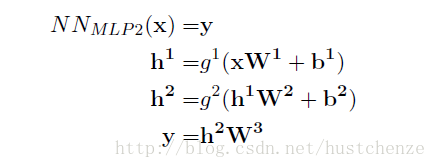
3.常见的激励函数
(1)Sigmoid函数
(2)tanh函数
(3)ReLU函数
4.对于神经网络的输出进行再次变换
例如是一个多分类问题,输出可以表示为y1,y2,…,yN,N分类的问题,想要知道最终是属于哪一类的,需要做一个Softmax。softmax函数可以表示为:
谁的输出最大,就取那一类为输出类
损失函数
对于神经网络的训练,最重要的就是要明确目标函数,训练的目标是什么,就是要使得模型尽可能地取拟合训练数据样本,目标函数就是去最小化模型输出与样本标签之间的差距。损失函数就是这一用途。常见的损失函数有:(
Hinge函数:
对数损失函数
交叉熵
CNN应用于文本
传统对文本的表示为CBOW(Bag of words),没有语序的概念,只能说明拥有某个词和某个词出现的频率这样的。例如:“他不好,他相当坏”与“他不坏,他相当好”可能就区分不开。CNN的结构,就帮助模型记住了大量的局部信息,能够保存位置顺序。基本的convolution + pooling的结构如下所示:
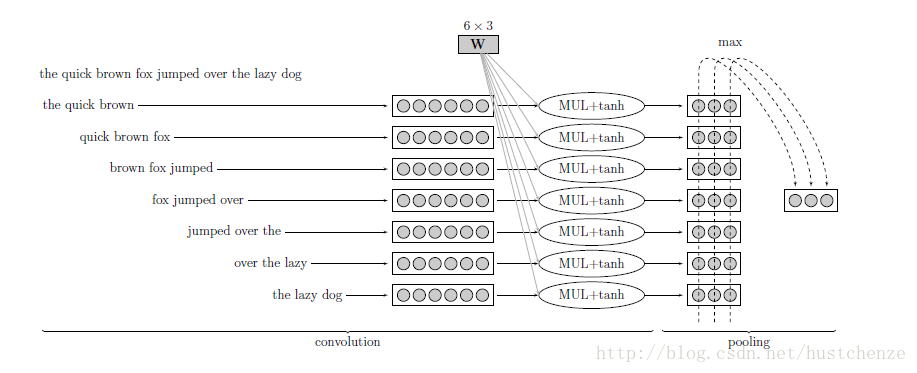
将文本编程小的phrase,然后分别训练前向神经网络,再使用pooling将多个神经网络整合输出。能够辅助记住局部文本信息。
RNN
RNN 在自然语言处理中得到广泛使用,保留句子序列信息。应用于机器翻译、问答系统等领域。
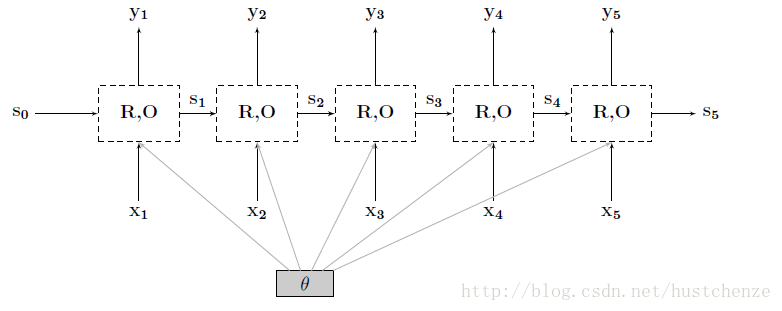
递归调用,前一时刻的信息输出给后一个序列。
RNN有很多种变形,例如LSTM就是解决RNN训练过程中梯度消失问题产生的长短时记忆网络,GRU就是解决LSTM训练过于复杂产生的神经网络。 Bi-RNN就是考虑未来序列信息用于增强模型的变形RNN等。
Recursive NN
区别于RNN,它是将句法树引入的神经网络,具体介绍参考http://www.jianshu.com/p/403665b55cd4