一、实验目的
(1)通过实验掌握 Spark SQL 的基本编程方法;
(2)熟悉 RDD 到 DataFrame 的转化方法;
(3)熟悉利用 Spark SQL 管理来自不同数据源的数据。
二、实验平台
操作系统: centos6.4 Spark 版本:1.5.0 数据库:MySQL
三、实验内容
实验一
1.Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。

为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
进入spark-shell中,输入以下命令:
val sqlcontext = new org.apache.spark.sql.SQLContext(sc) val df = sqlcontext.read.json("file:///usr/local/sparkdata/employee.json")
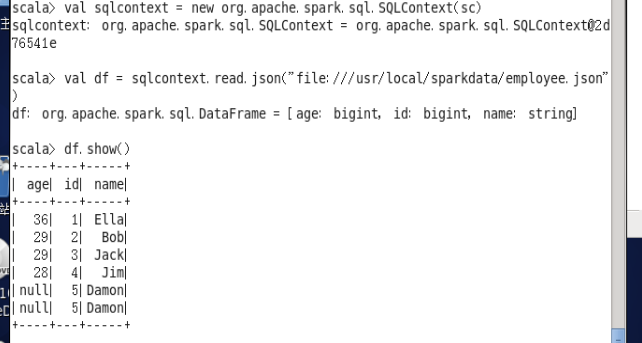
接着完成实验:
(1) 查询所有数据;
df.show()
(2) 查询所有数据,并去除重复的数据;
df.distinct().show()
(3) 查询所有数据,打印时去除 id 字段;
df.drop("id").show()
(4) 筛选出 age>30 的记录;
df.filter(df("age")>30).show()
(5) 将数据按 age 分组;
df.sort(df("age").asc).show()
(6) 将数据按 name 升序排列;
df.sort(df("name").asc).show()
(7) 取出前 3 行数据;
df.take(3)或df.head(3)
(8) 查询所有记录的 name 列,并为其取别名为 username;
df.select(df("name").as("username")).show()
(9) 查询年龄 age 的平均值;
df.agg("age"->"avg").show()
(10) 查询年龄 age 的最小值。
df.agg("age"->"min").show()
实验二
2.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):

请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到 DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代 码。
实验三
3. 编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的 两行数据。

(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所 示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
