1
import requests
url = "https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status() ##
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取出错")
ip地址查询
url = "http://m.ip138.com/ip.asp?ip="
try:
r = requests.get(url + "202.204.80.112")
r.raise_for_status() ##
r.encoding = r.apparent_encoding
print(r.text[-500:]) ##防止文本过大导致卡机
except:
print("爬取失败")
beautifulsoup
from bs4 import BeautifulSoup
import requests
r = requests.get("http://python123.io/ws/demo.html")
r.text
demo = r.text
soup = BeautifulSoup(demo, "html.parser")
#soup = BeautifulSoup(open("d://demo.html"), "html.parser")
print(soup.prettify()) ##格式化打印
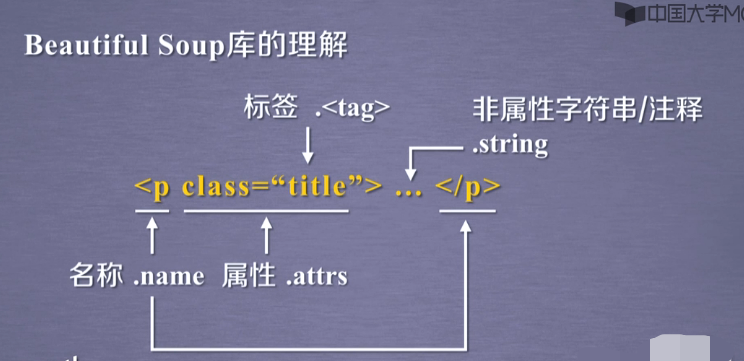
基本元素
标签使用
soup.a.name
tag = soup.a
tag.attrs
tag.attrs['class']
tag.attrs['href']


标签树上行遍历
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)