使用到了json库和requests库
使用到了bilibili读取视频信息的api
api url : http://api.bilibili.com/archive_stat/stat?aid=23
简单看一下api能获取到的信息的样子
{"code":0,"message":"0","ttl":1,"data":{"aid":23,"view":"--","danmaku":69619,"reply":23402,"favorite":55513,"coin":6196,"share":15953,"now_rank":0,"his_rank":173,"like":9313,"dislike":114,"no_reprint":0,"copyright":2}}
使用json库的json() 编码后,数据变成数组的形式,我们想要播放量的话就应该这样写
hot_video = VID_info["data"]["view"]
如果是想要弹幕数量的话就应该是
hot_video = VID_info["data"]["danmaku"]
如果是想要message信息的话就应该是
hot_video = VID_info["message"]
总是就是这么个规律,所以同理你可以爬取视频的其他信息。使用同样的思路request不同的api页面也能够获取不同的信息。。
最后把信息写入文本文件中,python写入文件的话一定要把打开文件的方式设置为 ‘a’ ,也就是在最后加入的append方式
在文件close()之前你是看不到数据的,想要让数据换行的话,在f.write()中最后一定要自己加一个 "\n" 换行,不然python不会自己换行
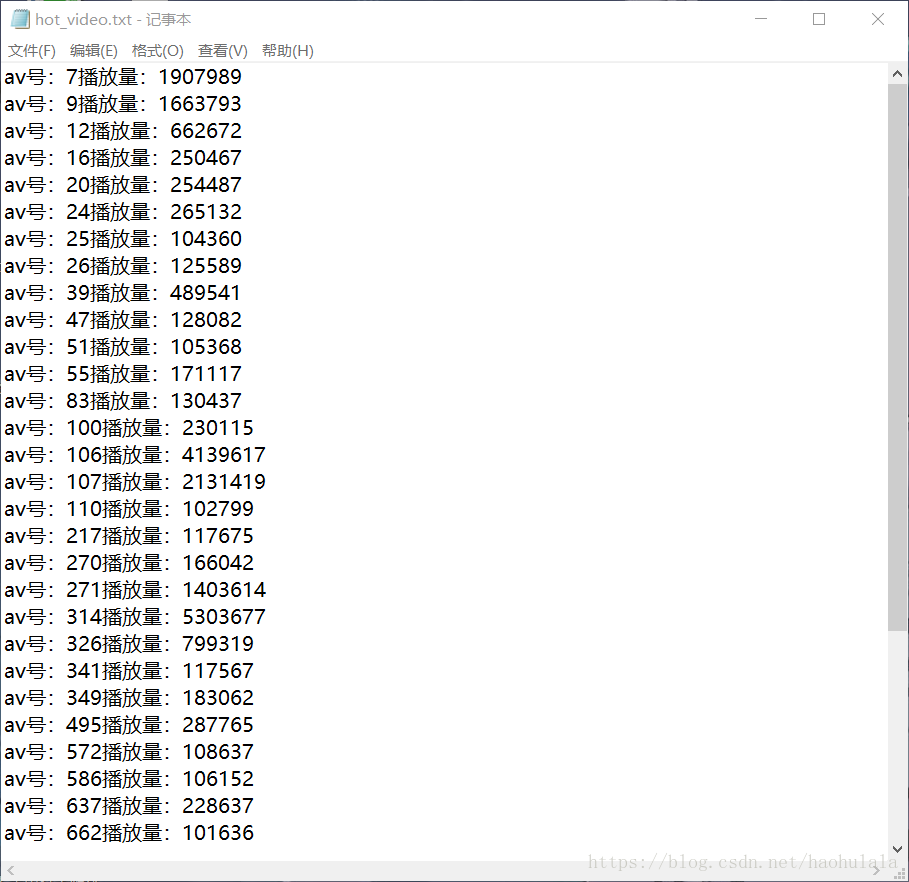
先上图,av号从1-1000 的视频中播放数量超过10w的av号有39个:
代码:
# -*- coding:UTF-8 -*-
#这个程序用来爬去b站视频中播放量过10w的av号
import json
import requests
def require_video(video_id):
URL_VIDinfo = "http://api.bilibili.com/archive_stat/stat?aid=" #b站视频信息api
PARAMS = {"aid":video_id }
VID_info = requests.get(url = URL_VIDinfo,params = PARAMS).json()
if(VID_info["message"] == "0"):
hot_video = VID_info["data"]["view"]
if hot_video != "--":
return hot_video
else:
return -1
else:
return -1
def main():
num_of_hot_video = 0
number = 1
f = open("hot_video.txt" , "a")
for video_id in range(6,1000):
video = require_video(video_id)
print(video)
if(video == -1):
print("第" + str(number) + "个视频不存在")
number += 1
elif(int(video) >= 100000):
num_of_hot_video += 1
f.write("av号:" + str(video_id) + "播放量:" + str(video) + "\n")
print("第" + str(number) + "个视频的播放量为:" + str(video))
number += 1
else:
number += 1
f.close()
print("av号从7开始的视频中播放数超过10w的视频有" + str(num_of_hot_video) + "个")
if __name__ == "__main__":
main()