大家好我是冈坂日川,闲着没事就又来做点好玩的,今天给大家一个已经包装好的,只要输入参数就可以获取哔哩哔哩相应弹幕词云的程序!好玩好玩!
效果

前言
-
B站是有给我们提供一个弹幕接口的,所以我们可以直接获取!
-
如何使用我的代码
1. 打开Pycharm 2. 安装requests、bs4 、pandas、jieba 、wordcloud 库 3. 获取B站指定视频 cid 4. 执行代码 输入cid 和 词云保存地址 5. 大功告成
一、代码
import requests #获取html
from bs4 import BeautifulSoup #网页解析
import pandas as pd #词频
import jieba #分词
import wordcloud #词云
x = input("请输入你的cid:")
url= 'https://comment.bilibili.com/'+str(x)+'.xml'
request = requests.get(url)#获取页面
request.encoding='utf8'#因为是中文,我们需要进行转码,否则出来的都是unicode
soup = BeautifulSoup(request.text, 'lxml')
results = soup.find_all('d')#找出所有'd'
comments = [comment.text for comment in results]#因为出来的时候是bs4格式的,我们需要把他转化成list
comments = [x.upper() for x in comments]#统一大小写
comments_clean = [comment.replace(' ','') for comment in comments]#去掉空格
#去掉没用的词
set(comments_clean)#看一下都有啥类似的没用的词语
useless_words = ['//TEST',
'/TESR',
'/TEST',
'/TEST/',
'/TEXT',
'/TEXTSUPREME',
'/TSET',
'/Y',
'\\TEST']
comments_clean = [element for element in comments_clean if element not in useless_words]#去掉不想要的字符
#查看词频
cipin = pd.DataFrame({'danmu':comments_clean})
cipin['danmu'].value_counts()
#分词
danmustr = ''.join(element for element in comments_clean)#把所有的弹幕都合并成一个字符串
words = list(jieba.cut(danmustr))#分词
fnl_words = [word for word in words if len(word)>1]#去掉单字
#生成词云
wc = wordcloud.WordCloud(width=1000, font_path='simfang.ttf',height=800)#设定词云画的大小字体,一定要设定字体,否则中文显示不出来
wc.generate(' '.join(fnl_words))
from matplotlib import pyplot as plt
plt.imshow(wc)
#保存词云图片
y=input(r"请输入你的保存地址:如(C:\Users\bnkj\Desktop\学习\):")
wc.to_file(str(y)+r"danmu_pic.png")
二、获取 cid

我们已 手工耿 大哥的这个视频为例
- 按 F12 查看网页源码
- 右上角点击 Network

3.刷新网页并播放视频
4.右部中间选择区域以找到 heartbeat
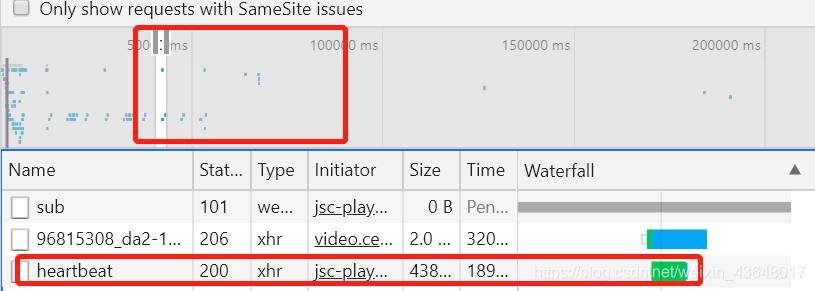
5.点击 heartbeat 出现页面下滑找到 cid
6.复制 cid

三、执行结果
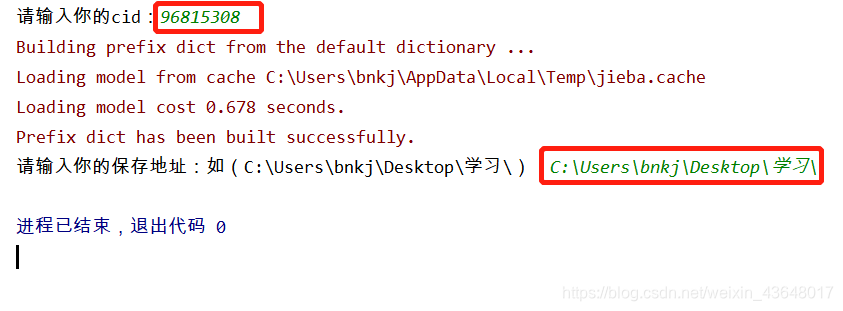
- 红框内为用户输入的内容
- 执行后的词云图

斜体样式代码已经写好了,按照我的步骤复制黏贴输入cid和保存路径就可以获取你想看到的视频的词云啦,嘻嘻!