优化问题概述
由于受多种变量的影响,一个问题会存在许多可能解。我们需要使用优化算法去搜索空间中的最优解。
优化算法是通过尝试许多不同解并给这些解打分以确定其是否更优来找到问题的最优解,应用场合是存在大量可能的题解以至于我们无法对它们进行一一尝试的情况。
该章节中用了指定组团旅行计划的例子对优化算法进行了描述。
问题描述
本例中,家庭成员来自全国各地,并且他们希望在纽约会面。他们将在同一天到达,并在同一天离开,他们会一起(搭乘相同的交通工具)从飞机场离开以及一起到达飞机场去。每一天各地的航班信息已知。
目标:家庭中的各位成员应该如何选择各自乘坐的航班
读入数据并构造字典
1.航班数据格式:起点、终点、起飞时间、到达时间、价格
2.采用txt存储,将数据读入,并用字典去存储,格式为key(起点,终点):value(起飞时间、到达时间、价格)
3.建立一个将字符串表示的标准时间转换为int型的分钟表示的函数
#航班数据格式:起点、终点、起飞时间、到达时间、价格
#拆字符串split() 去头和尾字符strip()
flights={}
with open('schedule.txt') as f:
for line in f:
#切割字符串 建立key为航班起点与终点的信息,value为空
origin,dest,depart,arrive,price=line.strip('\n').split(',')
flights.setdefault((origin,dest),[])
#将航班详情添加到航班信息中 由于同一起点终点的航班可能会有多班
#所以字典的形式应为key(origin,dest):value[(depart1,arrive1,int(price1)),(depart2,arrive2,int(price2))...]
flights[(origin,dest)].append((depart,arrive,int(price)))
#计算某个给定时间在一天中的分钟数 传入字符串形式表示的时间
def getminutes(t):
x=time.strptime(t,"%H:%M")
return x[3]*60+x[4]
描述题解以及构造目标函数
1.首先需要将该问题抽象化,能够用一组用数字构成的列表去描述题解,这样方便编程
2.这里使用一个list去描述题解,该数字表示改成员所乘坐的航班在航班字典中的次序号
例:1代表第一个家庭成员在飞往纽约时乘坐的航班在该天中第二班(0是第一班)飞往纽约的航班。
[1,4,3,2,7,3,6,3,2,4,5,3]
将此过程用程序翻译
#将人们决定搭乘的所有航班打印成表格
#描述乘坐的航班信息的方式为在该天中同一起点终点的航班的次序号
#r的形式为长度为人数两倍的列表,包含的信息即为航班的次序号
def printschedule(r):
for d in range(int(len(r)/2)):
name=people[d][0]
origin=people[d][1]
#从原始地出发到目标地的航班信息
out=flights[(origin,destination)][r[2*d]]
#返回的航班信息
ret=flights[(destination,origin)][r[2*d+1]]
#打印出每个人所乘坐的航班信息
print("%10s%10s %5s-%5s $%3s %5s-%5s $%3s" %(name,origin,out[0],out[1],out[2],ret[0],ret[1],ret[2]))
成本函数
成本函数即为目标函数,在优化问题中,成本函数的值越小,代表方案越好。
在构成成本函数时,需要考虑不同的因素
1.价格:航班总价格
2.旅行时间:每个人在飞机上的总时间
3.等待时间:在机场等待他人的时间
4.汽车租用时间:租用的费用与租用的天数相关
#成本函数计算 考虑相关因素:
#价格:所有航班的总票价
#旅行时间:每个人在飞机上花的总时间
#等待时间:在机场等待其他成员到达的时间
#出发时间:航班过早带来的减少睡眠的时间
#汽车租用时间:若集体租用一辆汽车,必须在一天之内早于起租时刻之前将车辆归还,否则将多付一天的租金
def schedulecost(sol):
totalprice=0
latestarrival=0
earliestdep=24*60
for d in range(int(len(sol)/2)):
#得到往程航班和返程航班信息
origin=people[d][1]
outbound=flights[(origin,destination)][sol[2*d]]
returnf=flights[(destination,origin)][sol[2*d+1]]
#总价格等于所有往返航程的价格之和
totalprice+=outbound[2]
totalprice+=returnf[2]
#记录最晚到达时间和最早离开时间
if latestarrival<getminutes(outbound[1]):
latestarrival=getminutes(outbound[1])
if earliestdep>getminutes(returnf[0]):
earliestdep=getminutes(returnf[0])
#每个人必须在机场等待直到最后一个人到达为止
#他们也必须在相同时间到达,并等候他们的返程航班
totalwait=0
for d in range(int(len(sol)/2)):
origin=people[d][1]
outbound=flights[(origin,destination)][sol[2*d]]
returnf=flights[(destination,origin)][sol[2*d+1]]
totalwait+=latestarrival-getminutes(outbound[1])
totalwait+=getminutes(returnf[0])-earliestdep
#判断租车费用是否需要再加一天
if earliestdep>latestarrival:
totalprice+=50
return totalprice+totalwait
成本函数建立之后,需要做的就是在目标空间中搜索了
随机搜索
算法描述:
1.指定所有人需要乘坐的航班的最大次序号和最小次序号
2.建立一个新的随机解
3.将新的随机解得到的成本值与之前的成本值对比,如果更小的话则接受此随机解作为新解
4.大量迭代
#随机搜索
#传入参数@domain 列表[(该方向航班序列号min,该方向航班序列号max),(,)...],长度是两倍的人数
# @constf计算成本使用的函数
def randomoptimize(domain,constf):
best=999999999
bestr=None
for i in range(1000):
#创建一个随机解
r=[random.randint(domain[i][0],domain[i][1]) for i in range(len(domain))]
#得到成本
cost=constf(r)
#与到目前为止的最优解进行比较
if cost<best:
bestr=r
best=cost
return bestr
爬山法
随机搜索较为低效,因为没法充分利用已经发现的优解,考虑到拥有较低成本的解很可能接近于更低成本的解,故引入爬山法。
算法描述:
1.开局一个随机解
2.然后在各个维度变化,找到成本最低的那个变化方向
3.持续迭代,直到找不到更优的解
#爬山法
def hillclimb(domain,costf):
sol=[random.randint(domain[i][0],domain[i][1]) for i in range(len(domain))]
#主函数
while 1:
#创建相邻的列表
neighbors=[]
for j in range(len(domain)):
#在每个方向上相对于原值偏离一点 相当于len维向量
#neighbors为两倍len长度的列表,每一个索引值改变某一维上的值,或加1或减1
if sol[j]>domain[j][0]:
neighbors.append(sol[0:j]+[sol[j]-1]+sol[j+1:])
if sol[j]<domain[j][1]:
neighbors.append(sol[0:j]+[sol[j]+1]+sol[j+1:])
#在相邻解中寻找最优解
current=costf(sol)
best=current
for j in range(len(neighbors)):
cost=costf(neighbors[j])
if cost<current:
sol=neighbors[j]
best=cost
#遍历所有的相邻解,在周围都没有更好的解,则退出循环
if best==current:
break
return sol
模拟退火算法
由于爬山法容易进入到局部最小值,故引入模拟退火算法
算法描述:
1.开局一个随机解,并用一个变量来表示温度,该温度最逐渐降低
2.对当前的解随机一个维度进行随机方向的变化
3.如果变化后的解的成本更低,则完全接受;如果成本更高的话,以一定概率接受这个更差的解
4.降温,并进行不断迭代,直到温度达到目标一下为止
#模拟退火算法
#找到更优解就替换,但如果找到的解更差的话以一定概率接受,概率大小与温度有关
#此算法有几率会跳出局部最优解,但不一定能达到全局最优解
def annealingoptimize(domain,costf,T=10000.0,cool=0.95,step=1):
#随机初始化值
vec=[(random.randint(domain[i][0],domain[i][1])) for i in range(len(domain))]
while T>0.1:
#选择一个索引值 即改变哪一维度的值
i=random.randint(0,len(domain)-1)
#选择一个改变索引值的方向 即该维度的值增加还是减小
dirt=random.randint(-step,step)
#创建一个代表题解的新列表,改变其中某一维度的值
vecb=vec[:]
vecb[i]+=dirt
#限制幅度,不能超过量程
if vecb[i]<domain[i][0]:
vecb[i]=domain[i][0]
elif vecb[i]>domain[i][1]:
vecb[i]=domain[i][1]
#计算当前成本和新的成本
ea=costf(vec)
eb=costf(vecb)
#接受新解的条件
if (eb<ea or random.random()<pow(math.e,-(eb-ea)/T)):
vec=vecb
#降低温度
T=T*cool
return vec
需要注意的是,模拟退火也不能保证找到全局最优解,只是能以一定概率跳出局部最优。

遗传算法
遗传算法的作用与模拟退火类似
算法描述:
1.开局生成一串随机解,称为种群,并对其按成本由低到高进行排序
2.选择前一定数量的解(物种)保留到新种群,新种群剩下的解(物种)由这些解变异或者交叉去生成,其中是变异还是交叉由一定概率决定。
3.经过大量迭代
注:
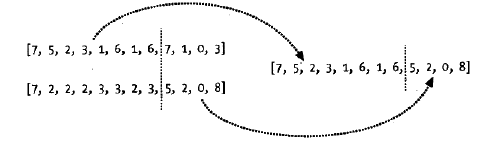
变异:解的某一维度上发生随机变化

交叉:两个解从某一维度开始交错
#遗传算法
#利用变异和交叉去构建新种群
#传入参数@popsize 种群大小
# @step 变异步长
# @mutprob 种群的新成员是由变异还是交叉得来的概率
# @elite 种群中被认为是优解传入下一代的部分
# @maxiter 运行多少代,即迭代次数
def geneticoptimize(domain,costf,popsize=50,step=1,mutprob=0.2,elite=0.2,maxiter=100):
#变异操作
def mutate(vec):
i=random.randint(0,len(domain)-1)
temp=random.random()
if vec[i]>domain[i][0] and temp<0.5:
return vec[0:i]+[vec[i]-step]+vec[i+1:]
elif vec[i]<domain[i][1] and temp>=0.5:
return vec[0:i]+[vec[i]+step]+vec[i+1:]
else:
return vec
#交叉操作
def crossover(r1,r2):
i=random.randint(0,len(domain)-2)
return r1[0:i]+r2[i:]
#构建初始种群
pop=[]
for i in range(popsize):
vec=[random.randint(domain[i][0],domain[i][1]) for i in range(len(domain))]
pop.append(vec)
#每一代有多少胜出者
topelite=int(elite*popsize)
#主循环
for i in range(maxiter):
scores=[(costf(v),v) for v in pop]
scores.sort()
ranked=[v for (s,v) in scores]
#从纯粹的胜出者开始
pop=ranked[0:topelite]
#添加变异和配对后的胜出者
while len(pop)<popsize:
#变异
if random.random()<mutprob:
c=random.randint(0,topelite)
pop.append(mutate(ranked[c]))
#交叉
else:
c1=random.randint(0,topelite)
c2=random.randint(0,topelite)
pop.append(crossover(ranked[c1],ranked[c2]))
#打印当前最优值
print(scores[0][0])
return scores[0][1]
总结
算法都不是很难,关键在于如何将一个问题描述为易于编程处理的结构。书中将其变化成一个由数字构成的列表的方法非常值得学习。
