基础概念
图像编码的原因:
数据时信息传递的手段,相同的信息可以通过不同的数据量去表示,尝试用不同的表达方式以减少表示图像的数据量,对图像的压缩可以通过对图像的编码实现。

数据压缩
减少表示给定信息所需要的数据量,包含不相关和重复信息的数据称之为冗余数据。数据压缩的目的就是消除冗余数据。
压缩率和相对冗余度
n1为压缩前的数据量(比特数),n2位压缩后的数据量
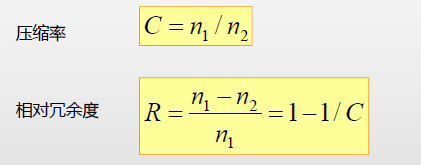
三种数据冗余类型
编码冗余
编码是用于表示信息实体和事件集合的符号系统(字母、数字、比特和类似的符号等)。
码字:每个信息和事件(灰度值)被赋予一个编码符号的序列(0x00–0xFF)
码长:码字中的符号数量(8)
码本:构成码字的所有编码符号的集合(0和1)
例:在多数二维灰度阵列中,用于表示灰度的8比特编码所包含的比特数要比表示该灰度所需要的比特数多。
每个像素的平均比特数
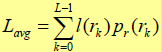
其中rk为某一灰度值,pr(rk)为该灰度值出现的概率,l(rk)为该灰度值使用的码字的码长(即所用的比特数),根据上式可以得出Lavg(比特/像素)
注:
1.如果用较少的比特数表示出现概率较大的灰度级,用较多的比特数表示出现概率较小的灰度级,得到的平均比特数较小。
2.如果平均比特数不能达到最小,就说明存在编码冗余。
空间和时间冗余
空间:相邻像素是空间相关的,即信息重复了
时间:相邻两帧中重复的信息
心理视觉冗余
图像中被人的视觉系统忽略的信息可以被当做是冗余信息去除
信息论相关
图像信息的度量
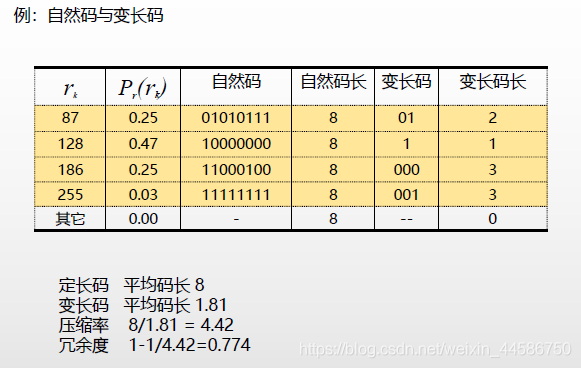
信息论中,一个具有概率P(E)的随机时间E所包含的信息量I(E)为
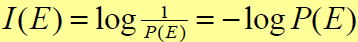
对数的底决定了信息的单位,一般取2
信源与熵
信源:一幅图像可以看做一个具有随机离散输出的信源,信源可以从一个有限的符号集中产生一个随机符号序列。
产生单符号的信源
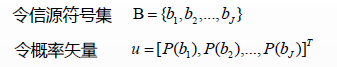
信源输出的平均信息H(u)
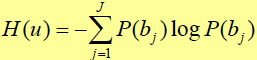
H(u)称信源的熵,表示观察到单个信源符号(即bi直接构成信息)输出时所获得的平均信息量。
注:
1.图像中,熵表示图像灰度级的平均比特数(划重点)或图像信源的平均信息量
2.当信源各个符号出现的概率相等时,信源的熵最大,信源此时提供最大的单个符号的平均信息量。
产生块随机变量的信源
产生的符号集是n个一组的符号

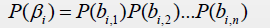
对于这类信源的熵:
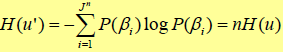
其熵对应单符号信源熵的n倍。
香农第一定理
确定了对零记忆信源的每个信源符号编码可达到的最小平均码字长度,即nH(u)
编码效率:
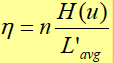
图像压缩系统模型
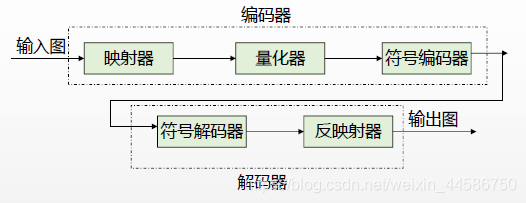
编码器:
映射器:对输入数据变换以减少像素的相关冗余(降低空间和时间冗余,例如游程编码)
量化器:减少映射器输出的精度减少心理视觉冗余
符号编码器:将短码赋给最频繁出现的量化器的输出以减少编码冗余
解码器:
符号解码器 反映射器
量化器—不可逆,解码中没有量化器的逆操作,故量化器不可用在无失真编码中
常用压缩算法
1.哈夫曼编码
基本原则:
较少的比特数表示概率较大的灰度值,较多的比特数表示概率较小的灰度值
编码过程:
1.缩减信源符号数量(全8bit到各种小于8bit的编码)
2.对每个信源符号赋值(信源符号由自己赋值,且每个信源符号各不相同(长度也是),故可以通过查表去解码)
编码注意事项:
从最后一步剩下的两个概率开始逐步向前进行编码。每步只需对两个分支各赋予一个二进制码,如对概率大的赋予码元0,对概率小的赋予码元1,记住在尾部添加!

哈夫曼编码特点:
1.Huffman码在字长变长码中最佳,码长平均长度很接近于符号的熵值。
2.满足即时性的编码(即读完一个码字就将其对应的信源符号(灰度值)确定)。
3.解码具有唯一性。
位平面编码
位面:
灰度图像的每个比特可看作表示了一个二值的平面。
位面0:最低位面
位面7:最高位面
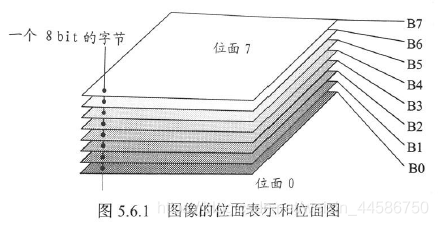
直接位平面分解的缺点:
像素微小变化可能会引起位平面复杂变化。

灰度码方法:
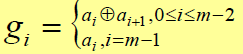
特点:上述计算后像素灰度微小变化不影响所有位平面。

注:
1.低位面图比高位面图包含细节多,更随机。
2.灰度码表达的位面图比对应的二值位面图复杂度更低,具有视觉意义信息的位面图数量更多。
位平面编码
游程编码:
对1组从左到右扫描而得的连续的0或1游程用游程的长度编码,默认以0开始
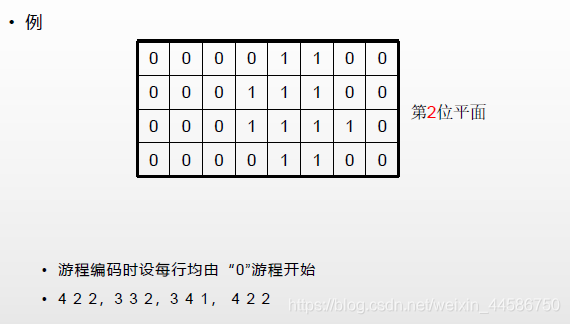

游程编码后再进行哈夫曼编码,却存在问题?
1.如果不采用任何编码手段,则数据量为843=96bit
2.采用了游程编码,得到42个像素点,后对这些像素点进行哈夫曼编码,计算得到平均码字长度为2.453,这样的话编码后的数据量达到了2.453*42=103bit
为神马编码完了反而数据量增大了。。。
预测编码
基本思想:
1.图像相邻像素存在很强的相关性,通过观察其相邻像素取值,可以预测一个像素的大概情况。
2.预测值和实际值存在误差,称为预测误差。
3.预测误差的方差必然比原图像像素的方差小,因此对预测误差进行编码必然压缩其平均码长。
线性预测编码:

注:
1.编码时对预测序列en进行编码,可以压缩数据量
2.在en的头部加上10(即初值值),这样就可以不断迭代(10+0,10+0+2……)
有损预测编码:
和无损预测编码的差别:
增加了量化器,将预测误差映射到有限个输出中。
例:德尔塔调制

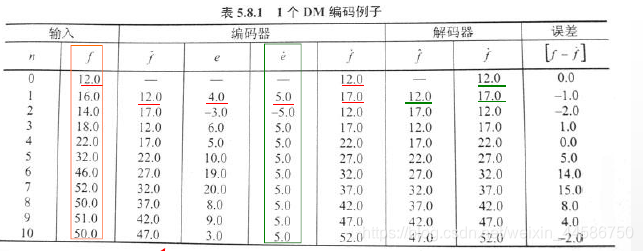
步骤:
1.存入初始条件
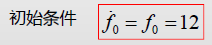
2.得到过去预测
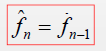
3.计算预测误差
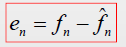
4.量化预测误差
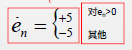
5.计算预测值,然后跳回2
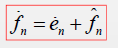
注:
1.同样对量化后的预测误差进行编码,再在头部存入初始值,即可通过迭代得到解码器的输出。
