数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别,大大缩短了业务处理时间,提升了工作效率和质量。
手写数字识别是每个深度学习者的必经之路,正如学习编程时,我们输入的第一个程序是打印"Hello World!"一样。 在飞桨的入门教程中,我们选取了基于MNIST数据集的手写数字识别模型作为启蒙教材,以便更好的帮助用户快速掌握飞桨平台的使用。
MNIST是深度学习领域标准、易用的成熟数据集,包含60000条训练样本和10000条测试样本,由一系列如下图所示的手写数字图片和对应标签。其中每张图片都是28x28的像素矩阵,经过了大小归一化和居中处理,标签对应着0~9的10个数字。

MNIST数据集是从 NIST 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集和测试集,其中训练集来自250位不同的标注员,且训练集和测试集的标注员完全不同。
MNIST吸引了大量的科学家基于此数据集训练模型。1998年,LeCun分别用单层线性分类器、多层感知器(Multilayer Perceptron, MLP)和多层卷积神经网络LeNet进行实验,使得测试集上的误差不断下降(从12%下降到0.7%)。在研究过程中,LeCun提出了卷积神经网络(Convolutional Neural Network),大幅度地提高了手写字符的识别能力,也因此成为了深度学习领域的奠基人之一。此后,科学家们又基于K近邻(K-Nearest Neighbors)算法、支持向量机(SVM)、神经网络和Boosting方法等做了大量实验,并采用多种预处理方法(如去除歪曲、去噪、模糊等)来提高识别的准确率。
如今的深度学习领域,卷积神经网络占据了至关重要的地位,从最早Yann LeCun提出的简单LeNet,到如今ImageNet大赛上的优胜模型VGGNet、GoogLeNet、ResNet等,人们在图像分类领域,利用卷积神经网络得到了一系列惊人的结果。飞桨各模型代码结构一致,大大降低了用户的操作难度
在探讨手写数字识别模型的实现方案之前,我们先“偷看”一下程序代码。不难发现,与上一章学习过的“房价预测”模型的代码比较,二者是极为相似的,如下图所示。
- 从整体结构上看,均为数据处理、定义网络结构和训练过程三个部分。
- 从代码细节来看,两个模型的程序也高度一致。
图2:“房价预测”和“手写数字识别”两者的实现代码“神似”

这就是我们使用飞桨框架搭建深度学习模型的优势,只要完成一个模型的程序案例学习,其它任务都是触类旁通的。在工业实践中,多数使用飞桨框架搭建模型的程序员无需每次都另起炉灶,而是在飞桨模型库中寻找与目标任务类似的模型,在该模型的代码上少量修改即可完成新任务。
"横纵式"建模方法,轻松掌握深度学习建模
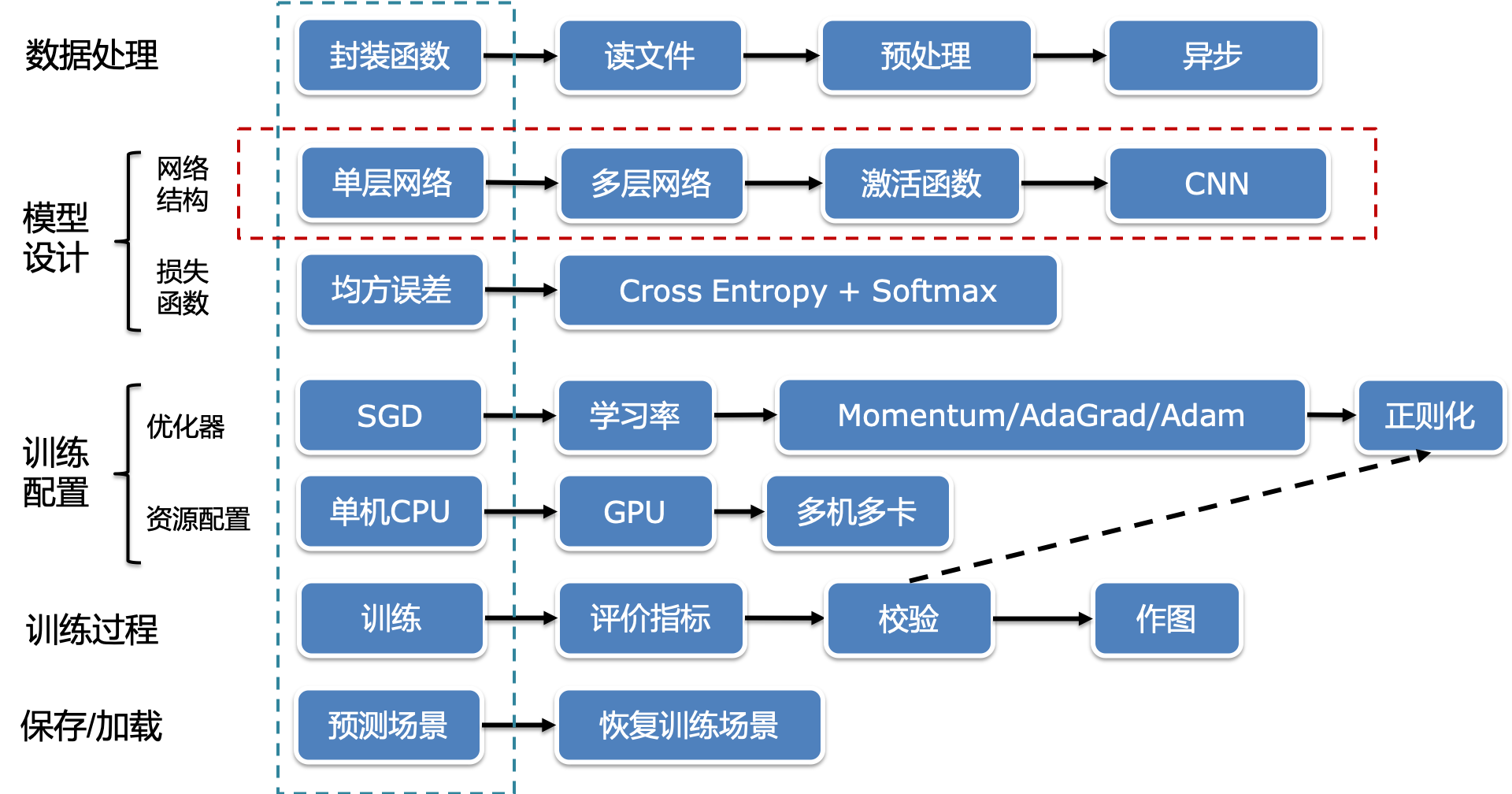
在接下来的学习中,为了便于大家的理解,我们采用飞桨为您专门设计的“横纵式”建模方法。 首先概要介绍模型的基本建模结构和极简实现,其次再深入探讨每个模块更复杂但有效的实现方案。例如在网络结构的部分,我们会演示如何从“单层网络”到“多层网络并加入非线性函数”,再到引入善于用于处理图像信号的“卷积神经网络”,如下图所示。
图3:“横纵式”建模方法
说明:
探讨网络结构如何优化的过程中,程序的其他模块维持不变。