百度正式发布PaddlePaddle深度强化学习框架PARL
近日,百度PaddlePaddle正式发布了深度强化学习框架 PARL,同时开源了基于该框架的、在 NeurIPS 2018 强化学习赛事中夺冠的模型完整训练代码。
项目地址如下:https://github.com/PaddlePaddle/PARL
PARL 框架的名字来源于 PAddlepaddle Reinfocement Learning,是一款基于百度 PaddlePaddle 打造的深度强化学习框架。PARL 与现有强化学习工具和平台相比,具有更高的可扩展性、可复现性和可复用性,支持大规模并行和稀疏特征,能够快速 对工业级应用案例的验证。
为了帮助用户快速搭建可以和环境交互的机器人,PARL 抽象出数个基础类,包括 Model、Algorithm、Agent 等。
Model 类负责强化学习算法中的网络前向计算(forward)部分,通常嵌套在 Algorithm 类中。
Algorithm 类则定义了网络的更新机制(backward),通常属于一个 Agent。
Agent 类负责和环境进行交互,负责数据 I/O,并且收集数据训练集下的 algorithm。
通过这样的设计方案,PARL 保证了算法的可扩展性:针对同一个场景,用户想调研不同的网络结构对算法效果影响的时候,比如调研 RNN 建模或者 CNN 建模,只需要重写 model 部分即可;针对不同场景想用同一个算法调研的时候,也是也只需重写 model 即可。可复现性主要体现在框架提供的 algorithm 集合上,在下一段和复用性一起结合理解。
此外,PARL 的这种结构设计方式也保证了高复用性。仓库内的提供了大量经典算法的例子 (algorithms 目录内), 包括主流的 DQN 、DDQN、Dueling DQN、DDPG、PPO 等,值得注意的是,这些算法由于和网络结构进行了解耦(网络结构的定义在 Model 类中),因此,算法并不针对特定任务,而相当于一个相当通用的算法抽象。用户在通过 PARL 搭建强化学习算法来解决自己目前遇到的问题时,可以直接 import 这些经典算法,然后只需要定义自己的网络前向部分,即可在短时间内构建出经典的 RL 算法。这种高复用性在极大地降低了用户的开发成本之外,也让 PARL 提供的多个算法的完整的超参数列表得以确保仓库内模型具备复现论文级别指标的能力。

下图是 PARL 官方提供的一个构建示例,展示了如何快速构建可以解决 Atari 游戏的 DQN 模型。用户只需要定一个前向网络(Model 类),然后调用框架算法集合里面的 DQN algorithm 即可构建一个经典 DQN 算法了。DQN 算法里面的繁琐的构建 target 网络,同步 target 网络参数等细节,已经包含在构建的 algorithm 里面,用户无需再特别关注。
百度对强化学习的关注由来已久。早在 2012 年,百度就将在 multi-armed bandit 问题上的研究成果部署到了推荐系统中,应用于搜索、对话、推荐等产品,通过点击反馈结合在线训练的方式,动态调整探索 (exploration) 和收益 (exploitation) 的平衡点,在降低探索风险的同时最大化推荐收益。近年来,强化学习在百度工业应用方面落地在了凤巢,新闻 Feed 推荐等产品线上,在学术方面也在机器人控制、通用人工智能等领域发表了多篇学术论文。2018 年,在第二届机器人控制会议 CoRL 上,百度发表了干预强化学习机制的工作。而在 NeurIPS 2018 的强化学习赛事上,百度也击败了 400 多支来自全球各个研究机构的参赛队伍,获得冠军。
随着强化学习领域的发展,多家 AI 公司都在尝试进行深度强化学习框架的设计,比如 Intel 的 Coach、OpenAI 的 baseline、Google 的 Dopamine 等。如今的开源社区中仍然是「百家争鸣」态势,并未出现一个主导的 RL 框架。
这其中主要的一个原因是强化学习近年来发展迅猛,新的研究方向不断涌现导致设计框架难以追赶算法本身的发展速度。从 15 年 Deepmind 发表 DQN 算法以来,大量的 DQN 算法变种纷纷涌现,包括 Double DQN、Dueling DQN、Rainbow 等,同时在连续控制 (continuous control RL),分层控制 (hierarchical RL),多机器人控制 (multi-agent RL) 上涌现出相当多的新技术,甚至和元学习(meta-learning)以及环境建模(model-based)等结合起来。当前社区中存在的开源框架均可支持上述的一部分算法,但是由于技术迭代太快,并没有一个框架能够覆盖所有新算法。
第二个原因是深度强化学习算法和应用,具有方法各异、超参难调、随机性大等特点,即便是针对同一个问题,使用同一种算法,不同的实现方式会带来极大的差异,学术界也一再强调强化学习可复现性问题。综合这些因素,要实现一个统一的模型和计算平台,是相当困难的事情。
PARL 在设计之初就将上述问题考虑在内,强调可复制(reproducible)可重用(reusable)以及可扩展(extensible)。
此外,由于 PARL 基于百度内部的成熟应用开源,因此更能方便地定制大规模并行算法。通过调用简单的函数接口,用户可以将算法从单机版扩展成 GA3C、A3C、IMPALA 等并行训练架构。PARL 对于通讯机制,数据 I/O 等也有独特的加速处理。此外,基于 PaddlePaddle 对大规模工业级排序/推荐等稀疏模型的支持能力,PARL 也能轻松扩展到百亿级别数据或特征的训练。
根据百度在 NeurIPS 上做的技术分享,基于 PARL 最多可以同时通过 8 块 GPU 来拉动近 20000 个 CPU 节点运算,完全发挥整个 CPU 集群的计算潜力,在 NeurIPS 2018 强化学习赛事中,成功将需要近 5 个小时迭代一轮的 PPO 算法加速到了不到 1 分钟每轮,实现了相对单机运算数百倍的加速比。这种目前开源社区中框架难以支持的并行提速,是他们拿下本次冠军的关键因素之一。
PaddlePaddle实战NLP经典模型 BiGRU + CRF详解
命名实体识别(Named Entity Recognition,NER)是 NLP 几个经典任务之一,通俗易懂的来说,他就是从一段文本中抽取出需求的关键词,如地名,人名等。
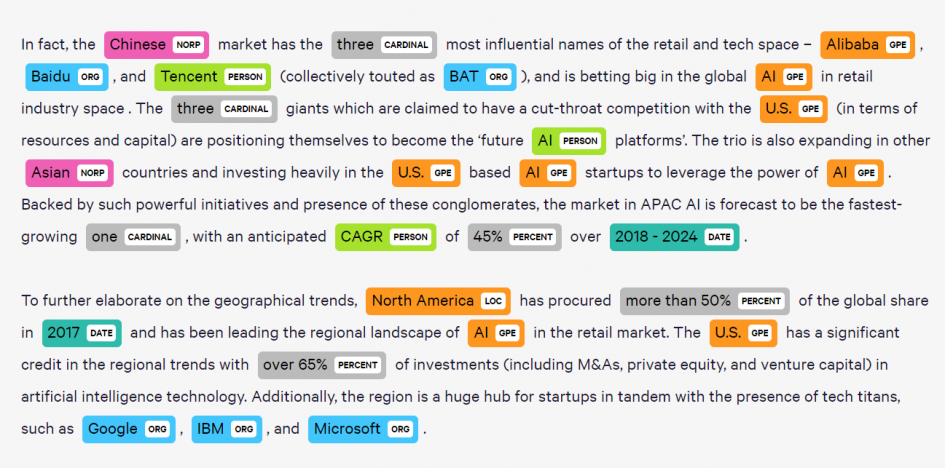
如上图所示,Google、IBM、Baidu 这些都是企业名、Chinese、U.S. 都是地名。就科学研究来说,命名实体是非常通用的技术,类似任务型对话中的槽位识别(Slot Filling)、基础语言学中的语义角色标注(Semantic Role Labelling)都变相地使用了命名实体识别的技术;而就工业应用而言,命名实体其实就是序列标注(Sequential Tagging),是除分类外最值得信赖和应用最广的技术,例如智能客服、网络文本分析,关键词提取等。
下面我们先带您了解一些 Gated RNN 和 CRF 的背景知识,然后再教您一步一步用 Paddle Paddle 实现一个命名实体任务。另外,我们采用经典的 CoNLL 数据集。
Part-1:RNN 基础知识
循环神经网络(Recurrent Neural Networks,RNN)是有效建模有时序特征输入的方式。它的原理实际上非常简单,可以被以下简单的张量公式建模:
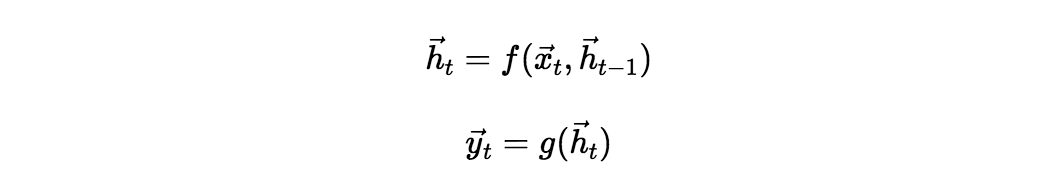
其中函数 f, g 是自定的,可以非线性,也可以就是简单的线性变换,比较常用的是:
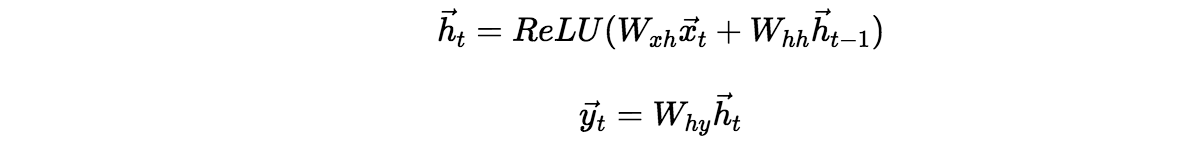
虽然理论上 RNN 能建模无限长的序列,但因为很多数值计算(如梯度弥散、过拟合等)的原因致使 RNN 实际能收容的长度很小。等等类似的原因催生了门机制。
大量实验证明,基于门机制(Gate Mechanism)可以一定程度上缓解 RNN 的梯度弥散、过拟合等问题。LSTM 是最广为应用的 Gated RNN,它的结构如下:
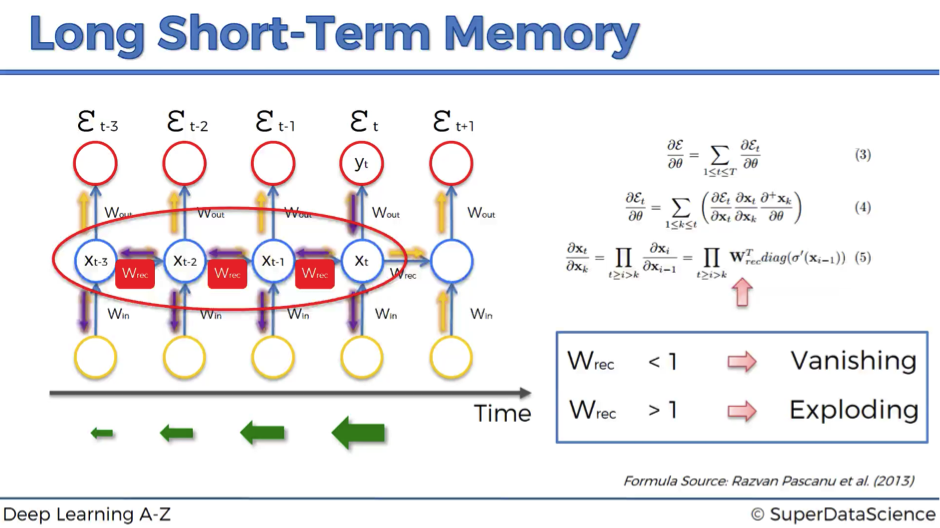
如上图所示,运算 tanh(取值 -1 ~ 1) 和 α(Sigmoid,取值 0 – 1)表示控制滤过信息的 “门”。
除了 LSTM 外,GRU(Gated Recurrent Unit) 也是一种常用的 Gated RNN:
- 由于结构相对简单,相比起 LSTM,GRU 的计算速度更快;
- 由于参数较少,在小样本数据及上,GRU 的泛化效果更好;
事实上,一些类似机器阅读的任务要求高效计算,大家都会采用 GRU。甚至现在有很多工作开始为了效率而采用 Transformer 的结构。
Part-2:CRF 基础知识
给定输入 X=(x_1,x_2,⋯,x_n),一般 RNN 模型输出标注序列 Y=(y_1,y_2,⋯,y_n) 的办法就是简单的贪心,在每个词上做 argmax,忽略了类别之间的时序依存关系。
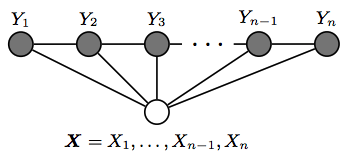
线性链条件随机场(Linear Chain Conditional Random Field),是基于马尔科夫性建模时序序列的有效方法。算法上可以利用损失 l(x)=-log(exp〖(x〗)) 的函数特点做前向计算;用维特比算法(实际上是动态规划,因此比贪心解码肯定好)做逆向解码。
形式上,给定发射特征(由 RNN 编码器获得)矩阵 E 和转移(CRF 参数矩阵,需要在计算图中被损失函数反向优化)矩阵 T,可计算给定输入输出的匹配得分:
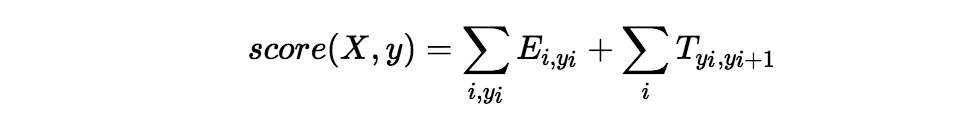
其中 X 是输入词序列,y 是预测的 label 序列。然后使以下目标最大化:
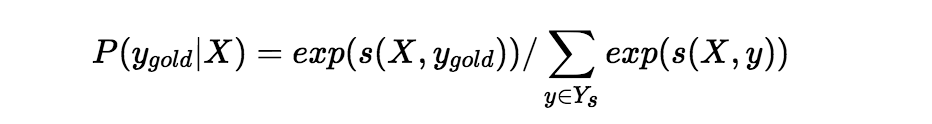
以上就是 CRF 的核心原理。当然要实现一个 CRF,尤其是支持 batch 的 CRF,难度非常高,非常容易出 BUG 或低效的问题。之前笔者用 Pytorch 时就非常不便,一方面手动实现不是特别方便,另一方面用截取开源代码接口不好用。然而 PaddlePaddle 就很棒,它原生的提供了 CRF 的接口,同时支持损失函数计算和反向解码等功能。
Part-3:建模思路
我们数据简单来说就是一句话。目前比较流行建模序列标注的方法是 BIO 标注,其中 B 表示 Begin,即标签的起始;I 表示 In,即标签的内部;O 表示 other,即非标签词。如下面图所示,低端的 w_i,0≤i≤4 表示输入,顶端的输出表示 BIO 标注。
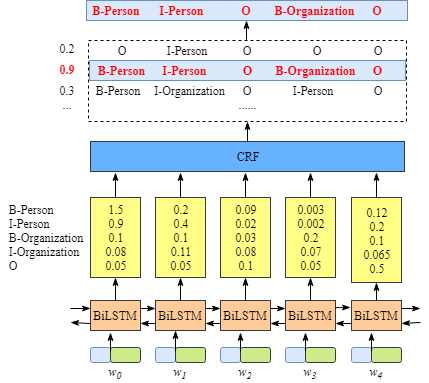
模型的结构也如上图所示,我们首先用 Bi-GRU(忽略图中的 LSTM) 循环编码以获取输入序列的特征,然后再用 CRF 优化解码序列,从而达到比单用 RNNs 更好的效果。
Part-4:PaddlePaddle实现
终于到了动手的部分。本节将会一步一步教您如何用 PaddlePaddle 实现 BiGRU + CRF 做序列标注。由于是demo,我们力求简单,让您能够将精力放到最核心的地方!
# 导入 PaddlePaddle 函数库.
import paddle
from paddle import fluid
# 导入内置的 CoNLL 数据集.
from paddle.dataset import conll05
# 获取数据集的内置字典信息.
word_dict, _, label_dict = conll05.get_dict()
WORD_DIM = 32 # 超参数: 词向量维度.
BATCH_SIZE = 10 # 训练时 BATCH 大小.
EPOCH_NUM = 20 # 迭代轮数数目.
HIDDEN_DIM = 512 # 模型隐层大小.
LEARNING_RATE = 1e-1 # 模型学习率大小.
# 设置输入 word 和目标 label 的变量.
word = fluid.layers.data(name='word_data', shape=[1], dtype='int64', lod_level=1)
target = fluid.layers.data(name='target', shape=[1], dtype='int64', lod_level=1)
# 将词用 embedding 表示并通过线性层.
embedding = fluid.layers.embedding(size=[len(word_dict), WORD_DIM], input=word,
param_attr=fluid.ParamAttr(name="emb", trainable=False))
hidden_0 = fluid.layers.fc(input=embedding, size=HIDDEN_DIM, act="tanh")
# 用 RNNs 得到输入的提取特征并做变换.
hidden_1 = fluid.layers.dynamic_lstm(
input=hidden_0, size=HIDDEN_DIM,
gate_activation='sigmoid',
candidate_activation='relu',
cell_activation='sigmoid')
feature_out = fluid.layers.fc(input=hidden_1, size=len(label_dict), act='tanh')
# 调用内置 CRF 函数并做状态转换解码.
crf_cost = fluid.layers.linear_chain_crf(
input=feature_out, label=target,
param_attr=fluid.ParamAttr(name='crfw', learning_rate=LEARNING_RATE))
avg_cost = fluid.layers.mean(crf_cost)
# 调用 SGD 优化函数并优化平均损失函数.
fluid.optimizer.SGD(learning_rate=LEARNING_RATE).minimize(avg_cost)
# 声明 PaddlePaddle 的计算引擎.
place = fluid.CPUPlace()
exe = fluid.Executor(place)
main_program = fluid.default_main_program()
exe.run(fluid.default_startup_program())
# 由于是 DEMO 因此用测试集训练模型.
feeder = fluid.DataFeeder(feed_list=[word, target], place=place)
shuffle_loader = paddle.reader.shuffle(paddle.dataset.conll05.test(), buf_size=8192)
train_data = paddle.batch(shuffle_loader, batch_size=BATCH_SIZE)
# 按 FOR 循环迭代训练模型并打印损失.
batch_id = 0
for pass_id in range(EPOCH_NUM):
for data in train_data():
data = [[d[0], d[-1]] for d in data]
cost = exe.run(main_program, feed=feeder.feed(data), fetch_list=[avg_cost])
if batch_id % 10 == 0:
print("avg_cost:\t" + str(cost[0][0]))
batch_id = batch_id + 1相信经过本节您已经掌握了用 PaddlePaddle 实现一个经典序列标注模型的技术~
PaddlePaddle-GitHub的正确打开姿势
GitHub是一个面向开源及私有软件项目的托管平台、也是项目版本管理工具,会使用它是程序员入门的必备技能。PaddlePaddle也不例外,所有的源码及项目进展都在GitHub上开源公布。但对于刚入门写程序的同学来说,一打开GitHub看起来云里雾里,会有种无从下手的感觉,本文给同学介绍PaddlePaddle在GitHub仓库上的快速上手指南。
PaddlePaddle项目介绍
登录GitHub账号后,会进入到你的主页。在左上角的搜索处搜索PaddlePaddle即可进入PaddlePaddle项目主页面:
在仓库选项卡上方,已经置顶了4个最常用的仓库(Repositories,以下简称Repo):
Paddle:这个Repo中,存放了PaddlePaddle框架的所有代码。由于在Python调用时的包名叫Paddle,仓库遂起名叫Paddle。
Paddle Mobile: Paddle Mobile是移动端及嵌入式设备的深度学习框架。他与PaddlePaddle框架紧密结合,减少中间翻译造成的性能损失,使得运行PaddlePaddle模型时运行性能极高,兼容设备非常广泛,支持安卓、iOS、ARM开发板、麒麟芯片、Mali GPU、骁龙GPU、树莓派等,并且支持FPGA开发板。如果您在进行深度学习移动端开发,强烈建议使用Paddle Mobile框架。
Models:是PaddlePaddle官方的模型库,里面提供了深度学习诸多领域的经典模型复现。在每次PaddlePaddle版本更新后,我们的测试及研发人员都会对其中每一个模型在20种模拟开发环境下进行测试,以确保用户在学习使用中避免出现问题。目前对于仓库内大部分经典模型都应配备了相应的预训练模型,欢迎大家来体验。
Book:Book是Jupyter notebook的简称,是目前主流的机器学习案例教学方案,具有免安装PaddlePaddle、免配置环境、提供交互式web编程页面的优势。PaddlePaddle团队为初学者提供的八个典型的实验案例,包含深度学习主流的几个方向。Book使用Docker+jupyter的打包方案,使初学者即装即用。
后面的部分是PaddlePaddle生态中所有的项目(repo),例如PARL是PaddlePaddle强化学习框架,FluidDoc包含了所有PaddlePaddle相关的文档,这里就不一一列举了。
四大置顶项目介绍
一、GitHub Repo的功能介绍:
进入到Paddle仓库之后(每一个Repo皆是如此)
区域①: 右上角有三个按钮:
Watch是对Paddle仓库保持关注,如果此仓库有更新的动态就会推到你的个人主页上。
Star是点赞加收藏的结合体,用户可以通过一个repo的star数来判断公众对他的认可度。您Star过的repo都可以通过点击头像,下拉框中的your star中找到:
Fork是将仓库的代码全部拷贝至你的账户中,除了备份功能外,将来还可以对Paddle项目提交Pull request。
区域②: 在接下来的选项卡中:
Code就是访问这个repo时默认打开的页面,展示了这个repo的代码结构
Issues是向Paddle研发人员提问的小社区,在Paddle的issues中有研发同学24小时值班,大家有问题随时提问哟。
Pull requests里面给大家公示了所有贡献者给Paddle核心分支提交代码的审核进度、审核失败的原因以及那些代码通过了审核。
Projects是GitHub中的项目管理方式,里面展示的是一个一个项目看板,看板上每一个待办的项目的进展进度。
Wiki中是Paddle项目及开发层面上的一些知识文档和规范文档
Insights显示Paddle仓库最近的活动信息、仓库信息和该仓库的各项指标,让用户轻松了解该仓库的活动倾向。
区域③: 再下面一栏中:
表示此项目有过21423次代码更新,有14条项目分支,公开发布过21个版本,有180个代码贡献者以及遵循Apache-2.0协议规范。下面的彩虹条表示各语言的代码在项目中所占的比例。
二、Paddle Repo介绍:
区域④:占页面的最主要部分是文件内容及代码的目录结构:
Benchmark目录里存放了性能评测对比的结果、代码以及数据
Cmake目录里存放的是源码编译之间的链式结构
doc目录里存放的是文档文件,但此目录已经不再维护,已迁移至FluidDoc Repo
Go目录里存放的是使用go语言编写具备高性能通信分布式代码。
Paddle目录里存放的是Paddle底层C++以及CUDA的实现代码
Python目录里存放的是Python接口的实现以及调用方式
Tool目录里存放的是一些工程检测和代码调试的工具
在实际开发过程中,看的最多的就是Python目录,在下图目录中展示了Python各种函数接口的实现方法:
这里有在使用Paddle时用到的各种函数包,例如在Paddle中常见的data_feeder、executor、io、optimizer。如果在开发过程中对某个函数、算子的实现、使用方式比较疑惑,可以在这里直接查看Python接口的源码来弄明白问题。
三、Paddle Mobile Repo介绍:
Benchmark是Paddle Mobile框架在各个硬件平台,用各个经典算法的运行效率测试结果。
Demo是官方提供的Paddle Mobile测试demo程序下载脚本,有安卓版和iOS版
Doc里存放着给开发者提供的Paddle Mobile在各个硬件平台的开发指南
Metal是iOS的一个图形渲染框架,里面提供了Paddle Mobile在此框架下的结合代码
Src是source的缩写,里面存放的是Paddle Mobile的实现代码
Test目录里放的是研发人员用来测试模型、op用的工程代码,可以用 CMake编译成二进制执行文件。
Tools里存放的大多是在移动端所需要的调试程序,比如iOS编译程序、安卓调试脚本、中断监视程序。
四、Models Repo:
Models是PaddlePaddle的模型仓库,在此repo中,展示了如何用 PaddlePaddle 来解决常见的机器学习任务,提供若干种不同的易学易用的神经网络模型。
Models下fluid是PaddlePaddle最新版本的模型实现代码,在这里按照深度学习的应用方向(语音合成、图像、自然语言处理、语音转录等)进行分类。
预训练权重地址存放在每个细分项目的readme.md文档里,打开细分项目的文档,拉至最下方,例如image_classification:
可以看到一个Released models的表格。在表格的model列是模型的名称,这个名称是一个超链接,链接对应的是这个模型的预训练权重下载地址,点击模型名称即可下载相应的预训练模型。
预训练模型使用攻略可参考文章:
《PaddlePaddle预训练模型大合集,还有官方使用说明书》
五、Book Repo:
Book是PaddlePaddle针对初学者的一个特色教程,它是一本“交互式”电子书 —— 每一章都可以运行在一个Jupyter Notebook里。
由项目截图可以看出,一共提供了8个学习项目。学习项目安排得不仅循序渐进,而且包含了多个目前深度学习的主流方向:图像分类、抽象数据处理、推荐系统、文本序列化、角色语义标注、情感分析系统、机器翻译系统。
Paddle-book将Jupyter、PaddlePaddle、以及各种被依赖的软件都打包进一个Docker image了。所以您不需要自己来安装各种软件以及PaddlePaddle,只需要安装Docker即可。
安装Docker后,只需要在命令行窗口里运行一步,就会从DockerHub.com下载和运行本书的Docker image:
docker run -d -p 8888:8888 paddlepaddle/book
下载完成后,在本地浏览器中访问 http://localhost:8888,即可阅读和在线编辑本书。由于Jupyter的特性,您甚至可以直接在上面运行代码。
Paddle-book漫游指南就到这里结束了,想了解更多的小伙伴可以登录PaddlePaddle的GitHub体验一下:https://github.com/PaddlePaddle/。
您也可以登录PaddlePaddle的官网:www.paddlepaddle.org,通过右上方的链接进入:
新年就要到啦,祝大家在新的一年里PaddlePaddle学的愉快,用的舒心。
PaddlePaddle源代码解析之:Parameter切分逻辑分析#1994
相关参数
-
--parameter_block_size- 参数服务器的参数分块大小。如果未设置,将会自动计算出一个合适的值.- 类型: int32 (默认: 0).
-
--parameter_block_size_for_sparse- 参数服务器稀疏更新的参数分块大小。如果未设置,将会自动计算出一个合适的值.- 类型: int32 (默认: 0).
相关数据结构
parameter_block_size
本地以ParameterSegments为单位。
ParameterSegments和parameter是一一对应的
parameter block切分逻辑代码位置
详细的计算过程在下面prepareSendData中。
void ParameterClient2::sendAndReceiveParameter()
void ParameterClient2::prepareSendData()
serverId的计算:
nameHash:由parameterName决定
blockId:由parameter_block_size和当前所取到的block偏移有关系。
int serverId = std::abs((blockId + nameHash) % serviceNum_);
prepare data 详解
在调用sendAndReceiveParameter之前,首先要调用prepareSendData,preparedata负责切分好parameter数据,并分配到合适的pserver上。下面是dense parameter的过程:
最后的parallelInputIovs是做切分的地方,SendJob这个数据结构中,包含了具体的数据parallelInputIovs,上面的for循环中,通过beginDim和endDim来控制buf的地址,实现切分。
preparedata生成的sendJob,会被放入sendJobQueue_
最终会调用ProtoClient的send发送出去
结论:
parameter切分是把parameter当成一个buf,按blocksize切分。