
本文基于百度PaddlePaddle教程:
https://aistudio.baidu.com/aistudio/projectdetail/349025
一、深度学习的发展历程
1. 首先说说医学上的发现
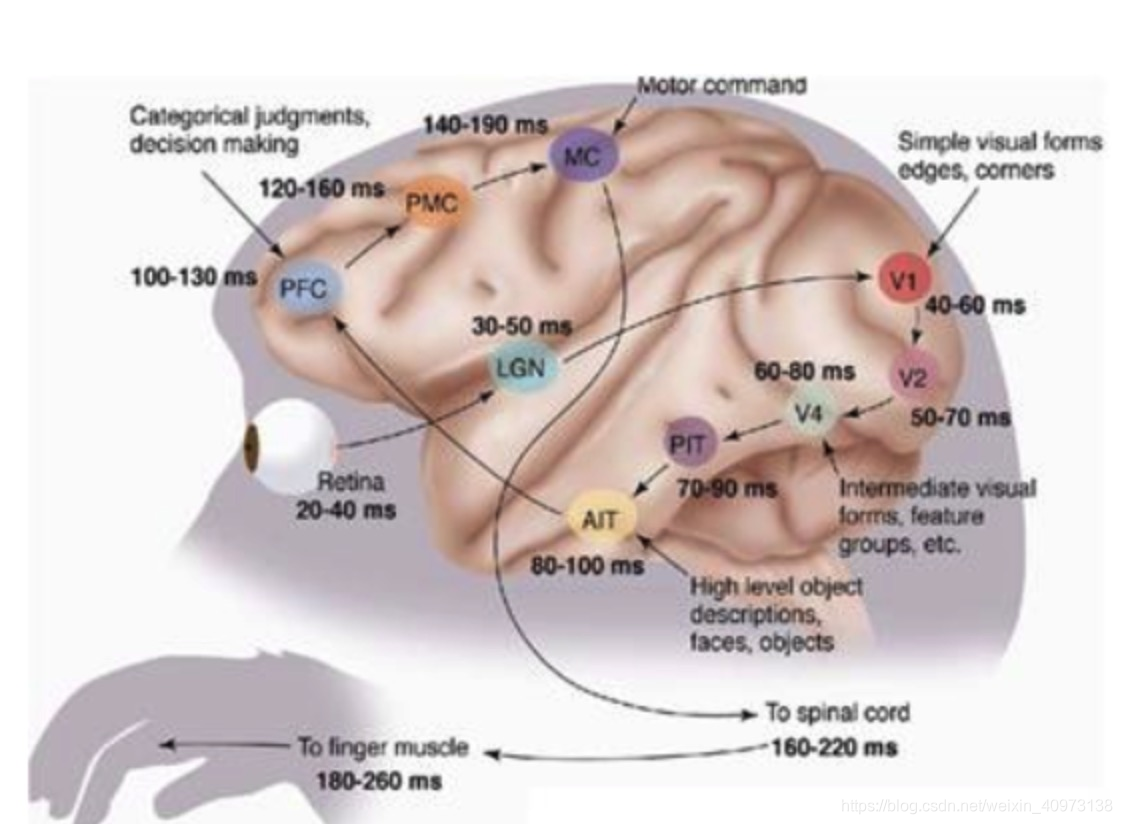
1981年的诺贝尔将颁发给了David Hubel和Torsten Wiesel,以及Roger Sperry。他们发现了人的视觉系统处理信息是分级的。
从视网膜(Retina)出发,经过低级的V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化,也即越来越能表现语义或者意图。
边缘特征 —–> 基本形状和目标的局部特征——>整个目标 这个过程其实和我们的常识是相吻合的,因为复杂的图形,往往就是由一些基本结构组合而成的。同时我们还可以看出:大脑是一个深度架构,认知过程也是深度的。
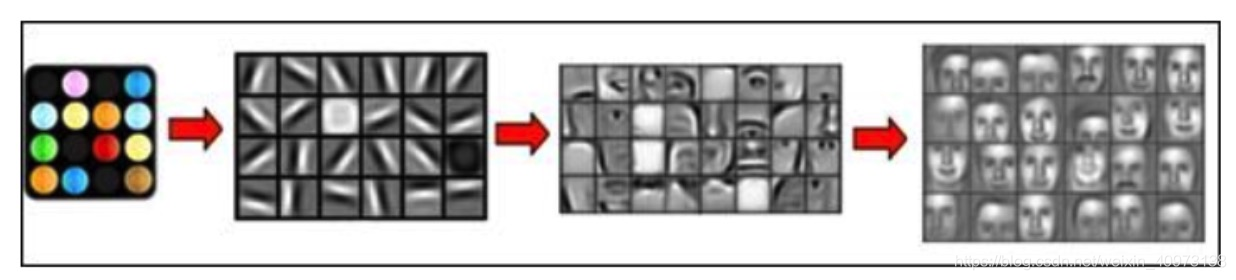
2. 深度学习的出现
低层次特征 - - - - (组合) - - ->抽象的高层特征
深度学习,就是通过组合低层特征形成更加抽象的高层特征(或属性类别)。
例如,在计算机视觉领域,深度学习算法从原始图像去学习得到一个低层次表达,例如边缘检测器、小波滤波器等,然后在这些低层次表达的基础上,通过线性或者非线性组合,来获得一个高层次的表达。此外,不仅图像存在这个规律,声音也是类似的。比如,研究人员从某个声音库中通过算法自动发现了20种基本的声音结构,其余的声音都可以由这20种基本结构来合成!
二、机器学习
机器学习是实现人工智能的一种手段,也是目前被认为比较有效的实现人工智能的手段。
简单来说,机器学习就是通过算法,使得机器能从大量历史数据中学习规律,从而对新的样本做智能识别或对未来做预测。
2. 人工智能和机器学习
人工智能是计算机科学的一个分支,研究计算机中智能行为的仿真。
每当一台机器根据一组预先定义的解决问题的规则来完成任务时,这种行为就被称为人工智能。
基本上,机器学习是人工智能的一个子集;更为具体地说,它只是一种实现AI的技术,一种训练算法的模型,这种算法使得计算机能够学习如何做出决策。
从某种意义上来说,机器学习程序根据计算机所接触的数据来进行自我调整。
3. 监督式学习和非监督式学习
监督式学习需要使用有输入和预期输出标记的数据集。
当你使用监督式学习训练人工智能时,你需要提供一个输入并告诉它预期的输出结果。
如果人工智能产生的输出结果是错误的,它将重新调整自己的计算。这个过程将在数据集上不断迭代地完成,直到AI不再出错。
非监督式学习是利用既不分类也不标记的信息进行机器学习,并允许算法在没有指导的情况下对这些信息进行操作。
三、深度学习如何工作
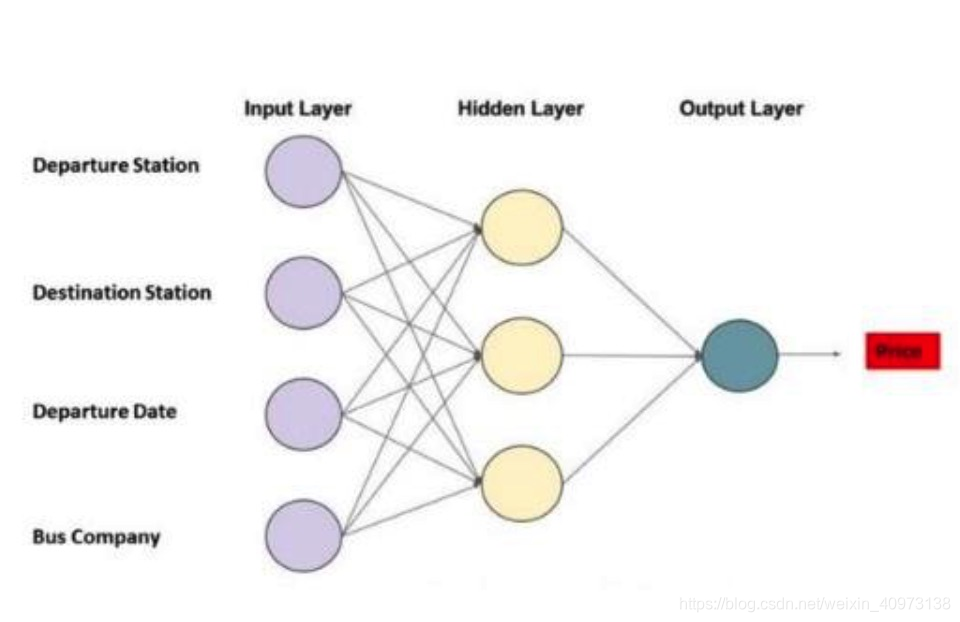
我们将通过建立一个公交票价估算在线服务来了解深度学习是如何工作的。
我们希望我们的巴士票价估价师使用以下信息/输入来预测价格:

1. 神经网络
神经网络是一组粗略模仿人类大脑,用于模式识别的算法。神经网络这个术语来源于这些系统架构设计背后的灵感,这些系统是用于模拟生物大脑自身神经网络的基本结构,以便计算机能够执行特定的任务。
和人类一样, “AI价格评估”也是由神经元(圆圈)组成的。此外,这些神经元还是相互连接的。
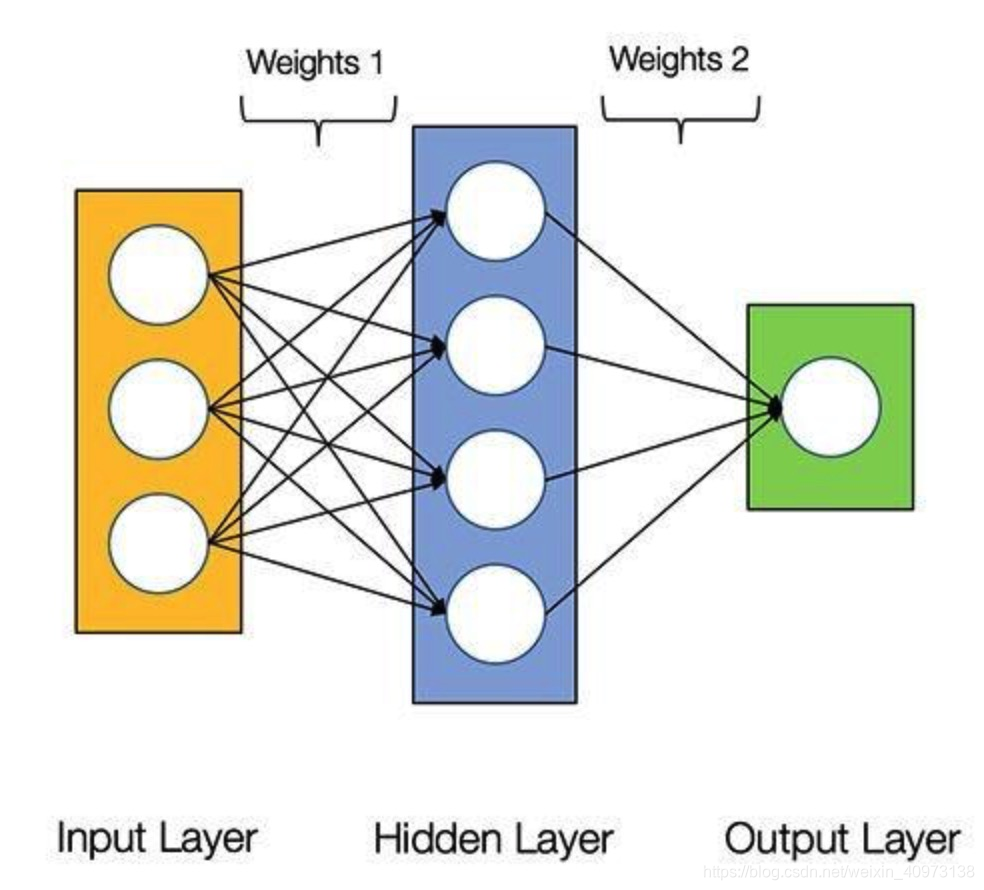
神经元分为三种不同类型的层次:
- 输入层接收输入数据。在我们的例子中,输入层有四个神经元:出发站、目的地站、出发日期和巴士公司。输入层会将输入数据传递给第一个隐藏层;
- 隐藏层对输入数据进行数学计算。创建神经网络的挑战之一是决定隐藏层的数量,以及每一层中的神经元的数量;
- 人工神经网络的输出层是神经元的最后一层,主要作用是为此程序产生给定的输出,在本例中输出结果是预测的价格值。
神经元之间的每个连接都有一个权重。这个权重表示输入值的重要性。模型所做的就是学习每个元素对价格的贡献有多少。这些“贡献”是模型中的权重。一个特征的权重越高,说明该特征比其他特征更为重要。
在预测公交票价时,出发日期是影响最终票价的最为重要的因素之一。因此,出发日期的神经元连接具有较大的“权重”。
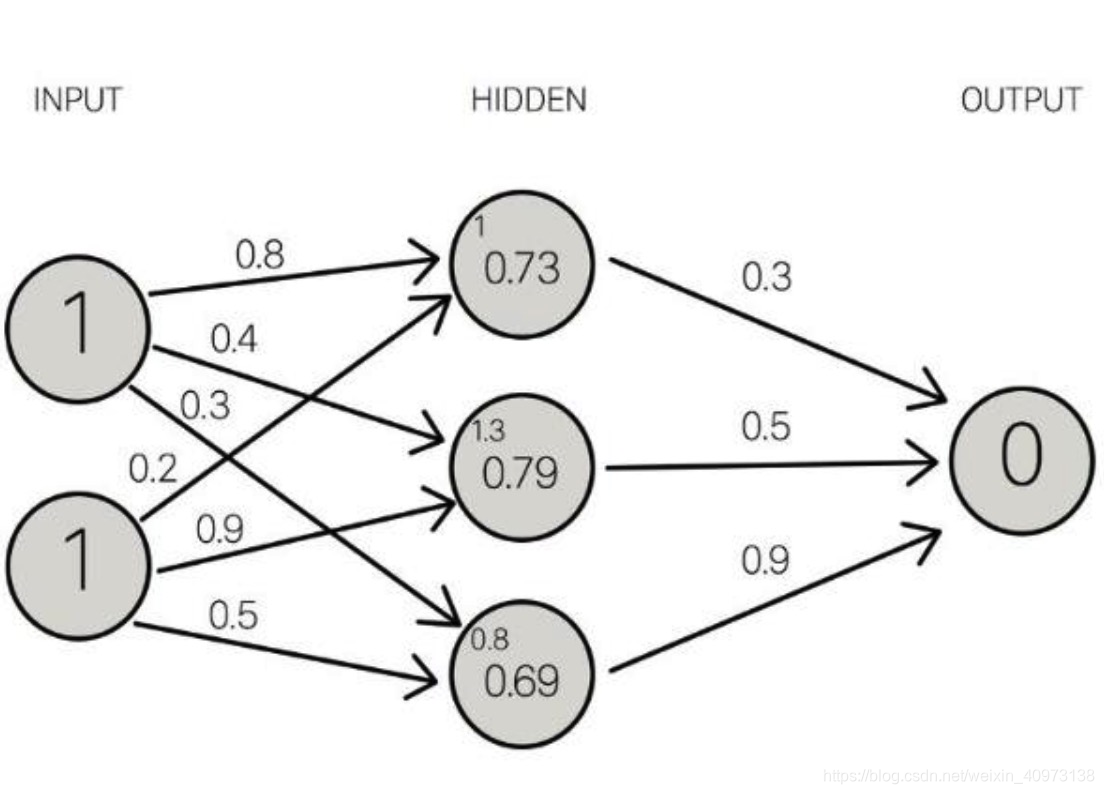
每个神经元都有一个激活函数。它主要是一个根据输入传递输出的函数。 当一组输入数据通过神经网络中的所有层时,最终通过输出层返回输出数据。
2. 通过训练改进神经网络
为了提高“AI价格评估”的精度,我们需要将其预测结果与过去的结果进行比较,为此,我们需要两个要素:
- 大量的计算能力;
- 大量的数据。
训练AI的过程中,重要的是给它的输入数据集(一个数据集是一个单独地或组合地或作为一个整体被访问的数据集合),此外还需要对其输出结果与数据集中的输出结果进行对比。
一旦我们遍历了整个数据集,就有可能创建一个函数来衡量AI输出与实际输出(历史数据)之间的差异。这个函数叫做成本函数。即成本函数是一个衡量模型准确率的指标,衡量依据为此模型估计X与Y间关系的能力。
模型训练的目标是使成本函数等于零,即当AI的输出结果与数据集的输出结果一致时(成本函数等于0)。
3. 如何降低成本函数?
通过使用一种叫做梯度下降的方法。梯度衡量得是,如果你稍微改变一下输入值,函数的输出值会发生多大的变化(导数)
梯度下降法是一种求函数最小值的方法。在这种情况下,目标是取得成本函数的最小值。 它通过每次数据集迭代之后优化模型的权重来训练模型。通过计算某一权重集下代价函数的梯度,可以看出最小值的梯度方向。
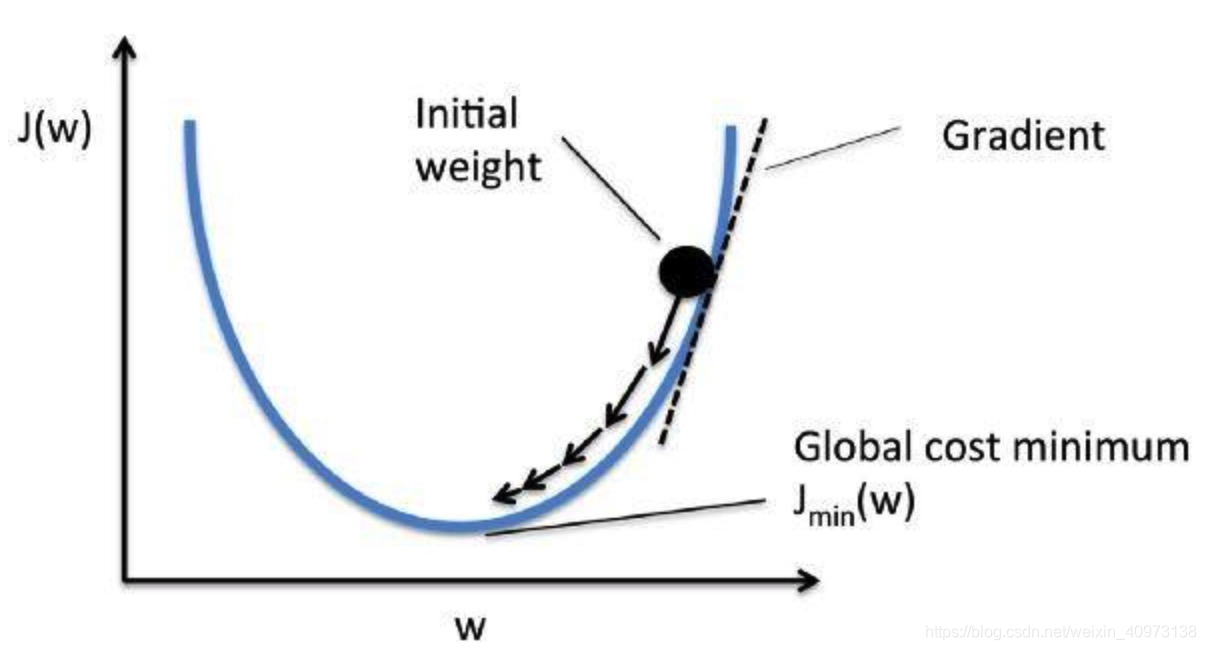
为了降低成本函数值,多次遍历数据集非常重要。
