决策树(中篇)
上期提到了一棵决策树的构建关键是不断去找最优特征作为划分结点,而谁是最优的就需要一个评判标准,常见的有基于信息增益法,基于信息增益率法和基于基尼指数法,分别对应ID3算法,C4.5算法和CART算法。
预备知识
1948年信息论之父克劳德·艾尔伍德·香农从热力学中借用“熵1 ”的概念第一次提出信息熵(information entropy)用来描述信源的不确定性,解决信息的测度问题。通常,一个信源发送出什么信号是不确定的,衡量它可以根据其出现的概率来度量,出现机会多,概率大,不确定性就小;反之不确定性就大,因此,不确定性函数
是概率
的减函数,同时还要求两个独立信号所产生的不确定性等于各自不确定性之和,即
, 同时满足这两个条件的恰好有对数函数

最简单的信源仅取0和1两个元素,即二元信源,其概率分别为P和1-P(
),该信源的熵函数图形即为上图所示。从图形可以看到,当
的时候,信息熵最大,最可怕的就是这种模棱两可的状态,当
或
的时候,信息熵等于0,极端的就是这种完全确定状态,且具有非负性。
一般的,假设信源发出的信号有
种取值
, 对应出现的概率为
,这时信源的不确定性为所有信号不确定性的和,称为信息熵
在现实中,对于具体数据集来说,需要利用样本概率进行估计。依然沿用上一期的数据集
假设数据集标签有
个类别:
,每个类别出现的概率可估算为
,其中
表示类别
中样本数,
为总样本数,这样数据集
的总体信息熵为
有了信息熵的概念就好定义信息增益和信息增益率。
信息增益(ID3算法)
用某个特征划分数据集之后的信息熵与划分前信息熵的差值称为关于该特征的信息增益(information gain)。假设用特征
去划分数据集
, 且设划分后的信息熵为
, 于是,信息增益
对于确定的数据集,其在划分前的信息熵是确定的,由公式可以看到划分后
越小,
越大,说明特征
对划分提供的信息越多,选择该特征作为划分对象后的不确定性程度越小。ID3算法2就是一个经典的决策树学习算法,其核心是在各层级结点都用信息增益作为判断准则进行特征选择,使得在每个被选择的特征对象进行分裂后,都能获得最大的信息增益,树结构的不确定性最小,使得树的平均深度较小,划分效率较高。
ID3算法流程
ID3学习算法流程一般有下面步骤
- 对原数据集D,计算所有特征的信息增益;
- 计算关于每一个特征的信息增益,选择信息增益最大的特征作为划分对象,把具有相同划分取值的样本归到同一个子数据集,进入下一层级;
- 如果子数据集的标签只有一种,则是叶结点,直接打上标签,然后返回调用处;如果子数据集的标签不止一种,继续本算法。
由于ID3算法采用信息增益作为分裂判断准则,由熵函数的性质可以发现,信息增益会倾向选择出现两极分化的特征作为优先划分对象,即高度分支特征,然后这类特征在现实中不一定是最优的属性,同时ID3算法只能处理离散特征,对于连续型特征,在划分之前还需要对其进行离散化预处理,为了解决的选择高度分支特征倾向和离散特征局限的问题,便有C4.5决策树学习算法。
信息增益率(C4.5算法)
C4.5算法采用信息增益率准则,信息增益率是在信息增益的基础上加一个惩罚系数用来做平衡调节,当出现高度分支特征的时候,其信息熵小,信息增益值大,于是给一个较小的惩罚系数,反之给一个较大的惩罚系数。用公式写出来就是
惩罚系数
常定义为数据集
以特征
作为随机变量的熵的倒数,即
其中
为特征
的类别数,
为数据集
所含样本数,
为特征
的第
类别的所含样本数,且
。从公式可以看出,当特征高度分化时,其对应的信息增益值较大,但其倒数较小,惩罚系数较小;反之,惩罚系数较大,惩罚系数恰巧起到一个平衡调节作用。C4.5 算法流程和 ID3 算法流程大致差不多,信息增益和信息增益率都是利用信息论里的知识来作为判定准则,有其局限性,下面要介绍CART算法则是用基尼知数来度量的,更直白的刻画分错分对的实际情况。
基尼指数(CART算法)
基尼指数(Gini index)用来刻画模型的不纯度,表示一个随机选中的样本被分错的概率,也叫基尼不纯度(Gini impurity),如果被分错了,我们就称其不纯,当然,我们希望这种错误越少越好,也就是模型纯度越高越好,基尼指数越小,模型的不纯度越低,反过来,纯度越高,模型被划分的越好,因此,选择那些基尼指数越小的特征作为划分对象。
假设数据集有
个类别,样本点属于第
类别的概率为
,那么该数据集的基尼指数定义为
其中
。
在CART3决策树学习算法中,如果数据集
根据特征
被分割成
个子数据集,那么在特征
下条件下,数据集
的基尼指数可以写成
熵VS基尼指数
既然熵和基尼指数都可以用来作最优特征选择判断,下面通过二分类来看一下两者的差别
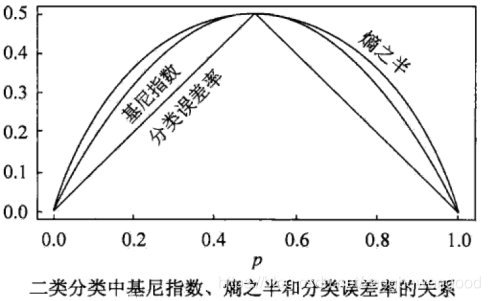
从两者在二分类中的表现曲线看到,熵之半曲线的凸性要强于基尼指数曲线的凸性,且当概率为0.5的时候,两者均达到最大值,两者具体关系可以通过泰勒展式来理清。
剪枝
上一期,我们提到了不能让一棵树无限生长,即使这棵树对已有的数据集划分的一清二楚,但是对未知的数据集却有可能表现的非常糟糕,这就是人们常说的过拟合,这时候就需要对其进行剪枝,使得模型的泛化能力更强。养过向日葵的朋友知道,向日葵是一种向上生长在顶端开花的植物,如果新芽从侧面长出来,就要掐掉,否则向日葵就会开出满天星的效果。决策树的剪枝与养花的剪枝技术如出一辙,决策树里面的剪枝是指用父结点代替其下面的所有子结点作为一个叶结点,下面两图比较形象的刻画剪枝过程
对比上下两个树形结构图发现,后者直接用B结点代替掉了其子结点 D 和子结点E,并且自己作为一个叶结点,使得树的结构更加简单4,剪枝就是用更加简单的树结构去替代更加复杂的树结构,然后评估这种替代带来的利弊。常用的剪枝技术有先剪枝和后剪枝。
先剪枝是指增加一些划分终止的条件,提前结束树的生长,这与生物学中为了维护向日葵的顶端优势而先把侧芽掐剪掉是一回事。比如,事先设定分裂的阈值(信息增益值,信息增益率,基尼指数),当分裂前后的所求得的参数小于阈值就不再划分了,该结点作为叶结点。
后剪枝是指在一棵树生长“完全”后再对其进行剪枝,这与你平时看到的园艺工人用一个大大的剪刀把道路两旁景观树木修剪成某形状是一回事。
依然用上面的两个树图来说明,如果是从第一个图到第二个图是后剪枝,而直接到第二个图是先剪枝。现实中,往往采用后剪枝办法,常见的后剪枝技术有REP(Reduced Error Pruning)方法,PEP(Pessimistic Error Pruning)方法,CCP(Cost-Complexity Pruning)方法及EBP(Error-Base-Pruning)方法。
后话
这一节只稍微谈了一下3种分裂规则算法以及剪枝技术,下一节,把信息熵与基尼指数等相关证明和信息增益的具体计算以及剪枝技术的数学表述补充完善,再下一节,将会进入实践阶段。
