Spring Data JPA(Java Persistence API),是Spring框架的主要构建块之一。如果您想使用持久数据,它也是一个强大的工具。
目录
一、Spring Data与JPA的介绍
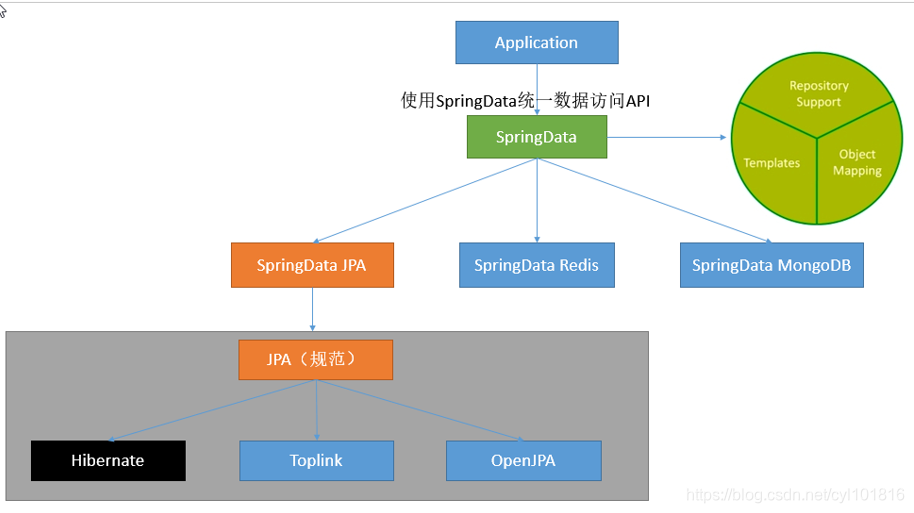
Spring Data 是 Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。Spring Data 项目的目的是为了简化构建基于 Spring 框架应用的数据访问技术,包括关系数据库、非关系数据库、Map-Reduce 框架、云数据服务等等。Spring Data具有如下的特点:
-
SpringData 项目支持 NoSQL 存储:
MongoDB (文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库) -
SpringData 项目所支持的关系数据存储技术:
JDBC
JPA -
Spring Data Jpa 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成!
-
框架怎么可能代替开发者实现业务逻辑呢?比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
JPA是Java Persistence API的简称,中文名Java持久层API,是JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
- JPA 是 Hibernate 的一个抽象(就像JDBC和JDBC驱动的关系);
- JPA 是规范:JPA 本质上就是一种 ORM 规范,不是ORM 框架,这是因为 JPA 并未提供 ORM 实现,它只是制订了一些规范,提供了一些编程的 API 接口,但具体实现则由 ORM 厂商提供实现;
- Hibernate 是实现:Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现
- 从功能上来说, JPA 是 Hibernate 功能的一个子集
JPA具有如下的特点:
- 标准化: 提供相同的 API,这保证了基于JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
- 简单易用,集成方便: JPA 的主要目标之一就是提供更加简单的编程模型,在 JPA 框架下创建实体和创建 Java 类一样简单,只需要使用 javax.persistence.Entity 进行注解;JPA 的框架和接口也都非常简单。
- 可媲美JDBC的查询能力: JPA的查询语言是面向对象的,JPA定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
- 支持面向对象的高级特性: JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,最大限度的使用面向对象的模型
二、基本操作CRUD
在实现CRUD的操作之前,当然是需要搭建Spring Data Jpa环境,即创建一个新的项目,选择合适的模板即可:

项目创建完成之后打开pom文件,与之前所创建的项目不同的当然就是为我们导入了相关的依赖包,
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>之后我们需要在application.properties文件中进行配置数据源配置:
server.port=80
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/scoot?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=root
#display sqp in console
spring.jpa.show-sql=true创建实体类Dept,
@Entity//告诉SB这是一个实体类,在启动SB的时候会加载这个类
@Table(name = "dept")//Dept类对应的表
@Getter//lombok使用
@Setter//lombok使用
public class Dept {
@Id//说明下面的deptno是主键
//GenerationType.IDENTITY代表使用数据库底层自动增长的数字作为主键
//oracle数据库没有自动增长属性,而是使用Seuence序列生成
//@SequenceGenerator()生成Oracle主键值
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "deptno")//deptno属性对应与deptno字段
private Integer deptno;
//@Column(name = "dname")
private String dname;
@Column(name = "loc")
private String location;
}JpaRepository是Spring Boot为我们提供的简化类,默认提供了增删改查方法,我们只需要定义接口就可以了,在SB启动的时候会自动帮我们生成具体的实现类,来实现CRUD方法,编写主要的业务逻辑类即可进行CRUD的操作,
@Controller
@RequestMapping("/dept")
public class DeptController {
@Resource
private DeptRepository deptRepository = null;
@GetMapping("/{id}")
@ResponseBody
//将路径中符合要求的部分注入到对应的参数中
//这种方式被称为“路径变量”
public Dept findByID(@PathVariable("id") Integer id) {
//Optional是实体类的包装类,用于判断对象是否存在
Optional<Dept> op = deptRepository.findById(id);
//op.isPresent();如果传入的id有对应的数据返回true,否则返回false
Dept dept = null;
if (op.isPresent() == true) {
dept = op.get();//获取到对应的实体类
}
return dept;
}
@GetMapping("/create")
@ResponseBody
public Dept create() {
Dept d = new Dept();
d.setDname("dfdff");
d.setLocation("New York");
deptRepository.save(d);
return d;
}
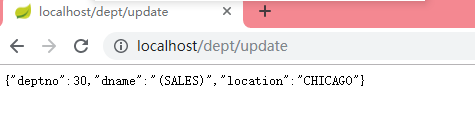
@GetMapping("/update")
@ResponseBody
public Dept update() {
Dept d = deptRepository.findById(30).get();
d.setDname("(" + d.getDname() + ")");
deptRepository.save(d);
return d;
}
@GetMapping("/delete")
@ResponseBody
public Dept delete() {
Dept d = deptRepository.findById(40).get();
deptRepository.save(d);
return d;
}
}下面以update()方法进行测试,启动进行测试,因为在之前的配置文件中设置了将sql语句打印在控制台,如下图:

三、Jpa数据查询
Spring Data Jpa有很多的方法的命名规则,我们在写数据查询的方法时可以按照此命名规则来写,
Spring Data Jpa方法命名规则:https://blog.csdn.net/cyl101816/article/details/100524566
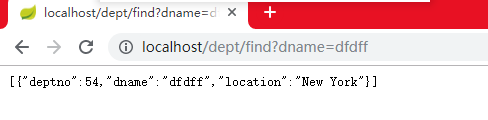
//selelct * from dept where dname = ?
public List<Dept> findByDname(String dname);业务逻辑:
@GetMapping("/find")
@ResponseBody
public List<Dept> findDepts(String dname){
List<Dept> list = deptRepository.findByDname(dname);
return list;
}查询结果:
实际上呢,这样的方法编写在我们实际的开发过程中并不是很适用的,很难满足我们实际的需求,我们需要使用更加灵活的方法去编写,JPQL java persistence query language 持久化查询语言,它是一种类sql语言,从SQL转换为JPQL只需要注意一下的几点:
- 大多数的情况下将*替换为别名
- 表名改为类名
- 字段名改为属性名
如此我们便可以替换上面的方法:
//select * from dept d where d.dname = ? order by deptno desc
//:dn是命名参数,其本质就是一个占位符,命名参数的格式为:参数名
@Query("select d from Dept d where d.dname = :dn order by deptno desc")
public List<Dept> findDepts(@Param("dn")String dname);四、对象关系映射
在上面的学习中已经完成了单一表数据的CRUD操作,如何在多张表中进行相应的操作,很显然就需要用到对象关系映射了,在此还是以本地数据库中的数据进行学习,创建实体类,逻辑控制类以及相应的接口,在一对多的情况下,通常是在多的一方进行映射的。
//dept与Emp的关系是1对多的关系
@ManyToOne//在多的一方使用ManyToOne多对一
@JoinColumn(name = "deptno")//JoinColumn指定关联的一方的关联字段,通常是主键
//只要获取dept的时候,会自动查询select * from dept where deptno = ...
private Dept dept;在业务逻辑类中进行业务逻辑书写,即可进行相关的CRUD操作。
public class EmpController {
@Autowired
private EmptRepository emptRepository;
@Autowired
private DeptRepository deptRepository;
@GetMapping("/{id}")
public Emp findById(@PathVariable("id")Integer id){
return emptRepository.findById(id).get();
}
@GetMapping("/create")
public Emp Create(){
Emp emp = new Emp();
emp.setComm(0f);
emp.setEname("laoqi");
emp.setHiredate(new Date());
emp.setJob("Teacher");
emp.setMgr(null);
emp.setSal(0f);
Dept dept = deptRepository.findById(20).get();
emp.setDept(dept);
emptRepository.save(emp);
return emp;
}
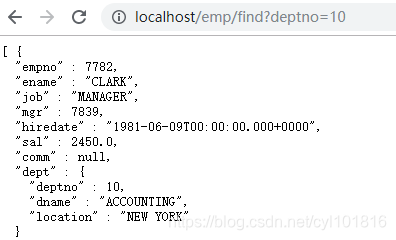
@GetMapping("/find")
public List<Emp> find(Integer deptno){
return emptRepository.findEmps(deptno);
}
}测试结果:
控制台:

对象关系映射中呢,通常是在多的一方进行映射的,如果在“一”的那一方进行映射,数据的获取效率会非常差,而且极大多数的情况下会进入到死循环中。
五、连接池与Druid
连接池是创建和管理一个连接的缓冲池的技术,这些连接准备好被任何需要它们的线程使用。
SB对连接池的支持:
- 目前Spring Boot中默认支持的连接池有dbcp,dbcp2, tomcat, hikari三种连接池。
- 数据库连接可以使用DataSource池进行自动配置。
- 由于Tomcat数据源连接池的性能和并发,在tomcat可用时,我们总是优先使用它。
- 如果HikariCP可用,我们将使用它。
- 如果Commons DBCP可用,我们将使用它,但在生产环境不推荐使用它。
- 最后,如果Commons DBCP2可用,我们将使用它。
尽管SB中有默认的三种连接池,但使用起来并不是最好用的。话不多说,并不是针对谁,在座的都是垃圾,个人还是支持阿里开发的连接池Druid。Druid是Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能。
https://github.com/alibaba/druid
因为SB默认是对Drudi不支持的,需要添加它的依赖:
<!-- Druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.9</version>
</dependency>然后在入口类SpringBootApplication中进行手动初始化:
@SpringBootApplication
public class SpringdatajpaApplication {
@Bean //手动初始化DruidDataSource对象
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druid(){
DruidDataSource ds = new DruidDataSource();
return ds;
}
public static void main(String[] args) {
SpringApplication.run(SpringdatajpaApplication.class, args);
}
}初始化结束后还需要进行相关的配置,打开application.properties文件:
#数据库类型为mysql
spring.datasource.dbType=mysql
#启动时初始化5个连接
spring.datasource.initialSize=5
#最小空闲连接5个
spring.datasource.minIdle=5
#最大连接数量20
spring.datasource.maxActive=20
#获取连接等待时间60秒,超出报错
spring.datasource.maxWait=60000
#每60秒执行一次连接回收器
spring.datasource.timeBetweenEvictionRunsMillis=60000
#5分钟内没有任何操作的空闲连接会被回收
spring.datasource.minEvictableIdleTimeMillis=300000
#验证连接有效性的SQL
spring.datasource.validationQuery=select 'x'
#空闲时校验,建议开启
spring.datasource.testWhileIdle=true
#使用中是否校验有效性,推荐关闭
spring.datasource.testOnBorrow=false
#归还连接时校验有效性,推荐关闭
spring.datasource.testOnReturn=false
spring.datasource.poolPreparedStatements=false
#设置过滤器,stat用于接收状态,wall用于防止SQL注入,logback则说明使用logback日志输出
spring.datasource.filters=stat,wall,logback
#统计所有数据源状态
spring.datasource.useGlobalDataSourceStat=true
#sql合并统计,与设置慢SQL时间为500毫秒
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500数据连接池初始化后,我们需要创建一个 用于显示后台界面的Servlet,还需要添加监听,这是其他的连接池所不具备的。
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@SpringBootApplication
public class SpringdatajpaApplication {
@Bean //手动初始化DruidDataSource 对象
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druid(){
DruidDataSource ds = new DruidDataSource();
return ds;
}
//注册后台界面Servlet bean , 用于显示后台界面
@Bean
public ServletRegistrationBean statViewServlet(){
//创建StatViewServlet,绑定到/druid/路径下
//开启后,访问localhost/druid就可以看到druid管理后台
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet() , "/druid/*");
Map<String ,String > param = new HashMap<String,String>();
param.put("loginUsername" , "admin");
param.put("loginPassword" , "123456");
param.put("allow" , "");//哪些IP允许访问后台“”代表所有地址
param.put("deny" , "33.31.51.88");//不允许这个IP访问
bean.setInitParameters(param);
return bean;
}
//用于监听获取应用的数据 , Filter用于收集数据, Servlet用于展现数据
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter()); //设置过滤器
bean.addUrlPatterns("/*");
Map<String,String> param = new HashMap<String,String>();
//排除静态资源
param.put("exclusions" , "*.png,*.woff,*.js,*.css,/druid/*");
bean.setInitParameters(param);
return bean;
}
public static void main(String[] args) {
SpringApplication.run(SpringdatajpaApplication.class, args);
}
}创建完成后登陆后台显示页面:
那么如图所示呢,数据源,SQL监控,防火墙等里面都有相应的数据供你查看。
六、事物配置Transaction
在EmpController中开启事物。在默认情况下,数据库的事物作用范围是在JpaRepository的CRUD方法上的。
@RestController //@Controller 使用@RestController的时候默认所有方法都返回JSON字符串,而不是跳转页面,我们也不用在方法上写@ResponseBody
@RequestMapping("/emp")
//默认该类的所有方法都开启事务
@Transactional(rollbackFor = Exception.class)
public class EmpController {
@Autowired
private EmptRepository empRepository;
@Autowired
private DeptRepository deptRepository;
@GetMapping("/{id}")
public Emp findById(@PathVariable("id") Integer id){
return empRepository.findById(id).get();
}
@GetMapping("/create")
public Emp create(){
Emp emp = new Emp();
emp.setComm(0f);
emp.setEname("laoqi");
emp.setHiredate(new Date());
emp.setJob("Teacher");
emp.setMgr(null);
emp.setSal(0f);
Dept d = deptRepository.findById(20).get();
emp.setDept(d);
empRepository.save(emp);
return emp;
}
@GetMapping("/find")
@Transactional(propagation = Propagation.NOT_SUPPORTED , readOnly = true)//不开启事务的方法
public List<Emp> find(Integer deptno){
return empRepository.findEmps(deptno);
}
@GetMapping("/imp")
//在默认情况下,数据库的事物作用范围是在JpaRepository的CRUD方法上,
//save方法一旦执行成功马上提交
//要保证数据的完整性,那就需要将事务提高至imp方法上
//在imp方法上开启事务,是需要增加@Transactional
//针对于这种使用注解的事务形式,也有一个名词叫做"声明式事务" , ParseException
//一般情况下,事务注解要写在最核心的Service上,而不是Controller
@Transactional(rollbackFor = Exception.class)//开启事务,imp方法运行成功提交。运行失败抛出RuntimeException及其子类的时候回滚
public void imp(){
for(int i = 0 ; i< 10 ; i++){
Emp emp = new Emp();
if(i == 3){
throw new RuntimeException("我出错啦");
}
emp.setComm(0f);
emp.setEname("laoqi" + i);
emp.setHiredate(new Date());
emp.setJob("Teacher");
emp.setMgr(null);
emp.setSal(i*10f);
Dept d = deptRepository.findById(20).get();
emp.setDept(d);
//saveAndFlush立即执行
empRepository.saveAndFlush(emp);
}
}
}