1.1 Master和Node
Master
K8S集群中的控制节点,负责整个集群的管理和控制,可以做成高可用,防止一台Master不可用。 其中有一些关键的组件:API Server,Controller Manager,Scheduler等
Node
Node会被Master分配一些工作,当某个Node不可用时,会将工作负载转移到其他Node节点上。
Node上有一些关键的进程:kubelet,kube-proxy,docker
1.2 kubeadm
1.2.1kubeadm init


过程分析:
1.进行一系列检查[init之前的检查],以确定这台机器可以部署kubernetes
pre-flight check:
(1)kubeadm版本与要安装的kubernetes版本的检查
(2)kubernetes安装的系统需求检查[centos版本、cgroup、docker等]
(3)用户、主机、端口、swap等
(4)拉取创建集群需要的镜像--这个在搭建之前就提前拉取了
2.生成kubernetes对外提供服务所需要的各种证书可对应目录,也就是生成私钥和数字证书
/etc/kubernetes/pki/* 下

(1)自建ca,生成ca.key和ca.crt
(2)apiserver的私钥与公钥证书
(3)apiserver访问kubelet使用的客户端私钥与证书
(4)sa.key和sa.pub
(5)etcd相关私钥和数字证书
3.为其他组件生成访问kube-ApiServer所需的配置文件xxx.conf (/etc/kubernetes下)
#集群的节点有了$HOME/.kube/config就可以使用kubectl和K8s集群打交道了,这个文件就是来自于上面的admin.config
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
master节点初始化后执行的这些步骤就是为了让master节点可以通过kubectl和k8s集群交互
其他节点如果想要通过kubectl和k8s交互,也需要这个文件将master的admin.conf文件上传到想通过Kubectl命令和k8s交互的worker节点
同样保存到$HOME/.kube/config目录下并授权即可![]()

4.为master生成静态Pod配置文件,这些组件会被master节点上的kubelet监听到,并且创建对应资源
/etc/kubernetes/manifests/目录下 
5.为集群生成一个bootstrap token,设定当前node为master,master节点将不承担工作负载
6.将ca.crt等 Master节点的重要信息,通过ConfigMap的方式保存在etcd中,供后续部署node节点使用
7.安装默认插件,kubernetes默认安装kube-proxy和CoreDNS插件,dns插件安装会出于pending状态,需要等网络插件安装完成,比如calico
1.2.2 join
kubeadm join 192.168.56.51:6443 --token 36j96r.o6pj47eh4rir3y2m \
--discovery-token-ca-cert-hash sha256:37e61162ccc36c63c38bb8c7619331898d12bbad51aba766bdf6eeaf5111eb62

1.join前检查
2.discovery-token-ca-cert-hash 用于验证master身份
3.token用于master验证node
如果没有及时保存最后的join信息,或者24小时之后过期了,这时候可以重新生成
[root@m ~]# kubeadm token create
855f8b.ee4vjcbjmgfcs3zq
[root@m ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
37e61162ccc36c63c38bb8c7619331898d12bbad51aba766bdf6eeaf5111eb62
#最后得到的新的join命令是这样的,token更新,但是sha不变
kubeadm join 192.168.56.51:6443 --token 855f8b.ee4vjcbjmgfcs3zq \
--discovery-token-ca-cert-hash sha256:37e61162ccc36c63c38bb8c7619331898d12bbad51aba766bdf6eeaf5111eb62
除了重新生成token,我们还可以通过命令获取到当前在使用的token
#在master上节点上,我们可以查看对应的token的值
kubectl get secret -n kube-system | grep bootstrap-token
bootstrap-token-855f8b bootstrap.kubernetes.io/token 6 3m36s
#得到token的值
kubectl get secret/bootstrap-token-855f8b -n kube-system -o yaml
#对token的值进行解码
echo NHRzZHp0Y2RidDRmd2U5dw==|base64 -d ---> ee4vjcbjmgfcs3zq
#最终token的值 和我们在上面生成的Token值一致
855f8b.ee4vjcbjmgfcs3zq
1.3核心组件
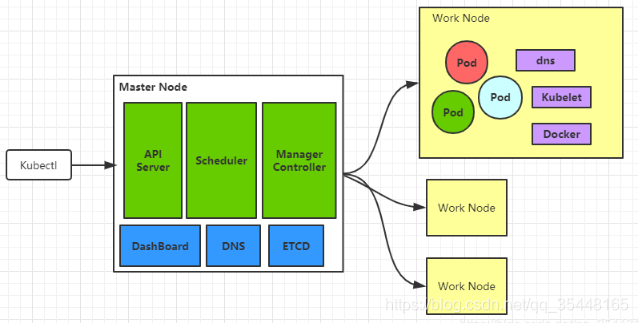
简单说下k8s的核心组件:
1.kubectl
操作集群的客户端,主要任务就是和集群打交道
2.kube-apiserver
整个集群的中枢纽带,安全和权限校验也由它负责
3.kube-scheduler
单纯地调度pod,按照特定的调度算法和策略,将待调度Pod绑定到集群中某个适合的Node,并写入绑定信息,由对应节点的kubelet服务创建pod
4.kube-controller-manager
负责集群中Node、Pod副本、服务的endpoint、命名空间、Service Account、资源配合等管理 会划分成不同类型的controller,每个controller都是一个死循环,在循环中controller通过apiserver监视自 己控制资源的状态,一旦状态发生变化就会努力改变状态,直到变成期望状态(对于一个多副本RS,停止一个pod之后会创建新的pod就是由controller manager管理控制的)
5.kubelet
集群中的每个节点上都会启动一个kubelet服务进程,用于处理master节点下发到本节点的任务,管理pod和container。每个kubelet会向apiserver注册本节点的信息,并向master节点上报本节点资源使用的情况
6.kube-proxy
在k8s集群中,每个Node上都会运行一个kube-proxy(daemonset),它是Service的透明代理兼负载均衡器,核心功能是将某个Service的访问请求转发到后端的多个Pod实例上
7.DNS
负责域名解析
8.dashboard
监控面板,能够监测整个集群的状态
9.etcd
整个集群的配置中心,所有集群的状态数据,对象数据都存储在etcd中。
kubeadm引导启动的K8s集群,默认只启动一个etcd节点
1.4 API Server
https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-apiserver/
APIServer提供了K8S各类资源对象的操作,是集群内各个功能模块之间数据交互和通信的中心枢纽,是整个系统的数据总线和数据中心。通常我们通过kubectl与APIServer进行交互。
APIServer通过kube-apiserver的进程提供服务,运行在master节点上
我们平时一般通过kubectl来和apiserver进行交互,但其底层kubectl与APIServer之间是通过REST API进行调用的
1.4.1 REST API
The Kubernetes API server validates and configures data for the api objects which include pods, services, replicationcontrollers, and others. The API Server services REST operations and provides the frontend to the cluster’s shared state through which all other components interact.
默认情况,Kubernetes API Server提供两个端口:
1.本地端口
- 该端口用于接收HTTP请求;
- 该端口默认值为8080,可以通过API Server的启动参数“--insecure-port”的值来修改默认值;
- 默认的IP地址为“localhost”,可以通过启动参数“--insecure-bind-address”的值来修改该IP地址;
- 非认证或授权的HTTP请求通过该端口访问API Server。
2.Secure Port
- 该端口默认值为6443,可通过启动参数“--secure-port”的值来修改默认值;
- 默认IP地址为非本地(Non-Localhost)网络端口,通过启动参数“--bind-address”设置;
- 该端口用于接收HTTPS请求;
- 用于基于Tocken文件或客户端证书及HTTP Base的认证;
- 用于基于策略的授权;
- 默认不启动HTTPS安全访问控制。
对于k8s集群的访问操作,都是通过api server的rest api来实现的,就像请求后台接口一样(需要先开放api-server yaml文件里的insecure-port,将其修改成8080端口)

#访问端口测试后发现,结果和使用kubectl执行命令一样
[root@m ~]# curl localhost:8080
[root@m ~]# curl localhost:8080/api
[root@m ~]# curl localhost:8080/api/v1
[root@m ~]# curl localhost:8080/api/v1/pods
[root@m ~]# curl localhost:8080/api/v1/pods/services
通过api-server创建资源等都需要权限校验,需要完成认证,授权,准入等验证后才可以操作资源,具体流程如下
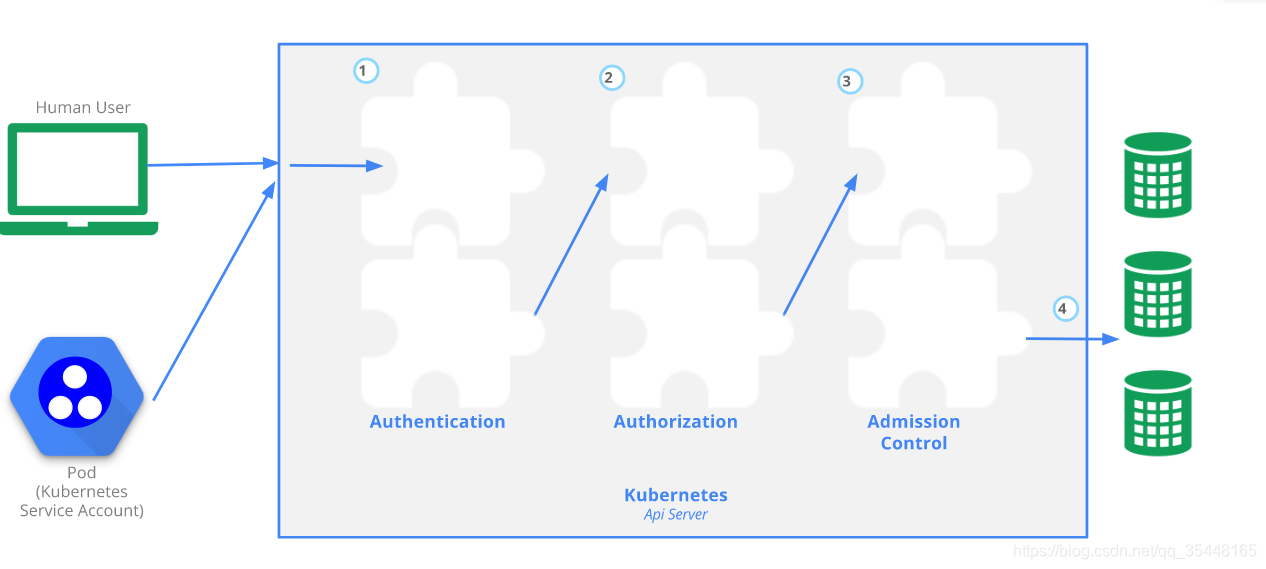
1.4.2 API Server认证(Authentication)
Authentication verifies who you are.就是如何识别客户端的身份
K8s集群提供了多种识别客户端身份的方式:
认证的第一个维度
- HTTPS证书认证 基于CA根证书签名的双向数字证书认证方式
- HTTP Token认证 通过一个Token来识别合法用户
- HTTP Base认证 通过用户名+密码的方式认证
认证的第二个维度
系统组件想要和apiserver进行认证,一般使用ServiceAccount
创建ServiceAccount一般会创建一个secret,这个secret会被自动加入到创建的Pod中(如果该Pod没有创建ServiceAccount,会使用集群默认的ServceAccount)
1.4.3 API Server授权(Authorization)
Authorization verifies what you are authorized to do.
授权就是授予不同用户不同的访问权限,APIServer 目前支持以下几种授权策略:
- Webhook:基于HTTP回调机制通过外部REST服务检查确认用户授权的访问控制
- ABAC:基于属性的访问控制,表示基于配置的授权规则去匹配用户请求,判断是否有权限。Beta 版本
- RBAC:基于角色的访问控制,允许管理员通过 api 动态配置授权策略。Beta 版本
常用的是基于RBAC授权模式,之前很多yaml都是基于该方式进行授权
使用Role,RoleBinding ; ClusterRole,ClusterRoleBinding 资源来实现RBAC权限控制
二者之间的区别在于ClusterRole定义的是和整个集群交互的权限
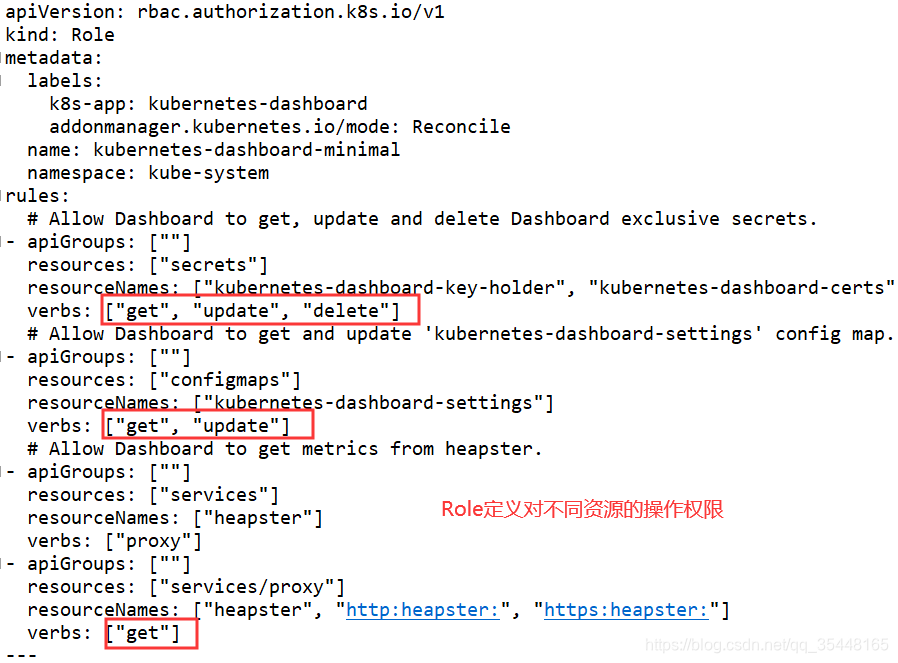
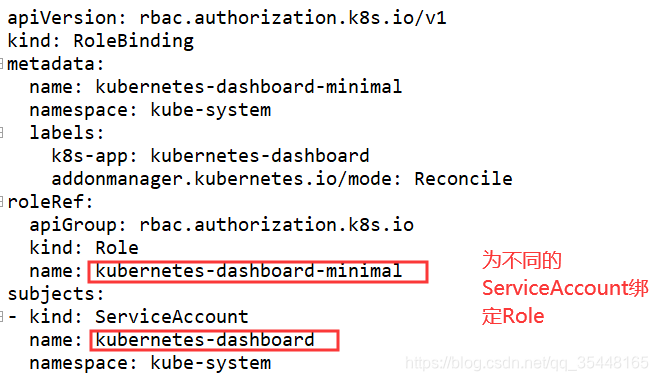
1.4.4 Admission Control(准入控制)
通过了前面的认证和授权之后,还需要经过准入控制处理,通过之后apiserver 才会处理这个请求。相当于最后的一组拦截器
常用的准入控制器主要有:
- AlwaysAdmit:允许所有请求
- AlwaysDeny:拒绝所有请求
- AlwaysPullImages:在启动容器之前总是去下载镜像
- ServiceAccount:将 secret 信息挂载到 pod 中,比如 service account token,registry key 等
...
1.5 Scheduler
In Kubernetes, scheduling refers to making sure that Pods are matched to Nodes so that Kubelet can run them.
通过调度算法,为待调度Pod列表的每个Pod,从Node列表中选择一个最合适的Node。 然后,目标节点上的kubelet通过API Server监听到Kubernetes Scheduler产生的Pod绑定事件,获取对应的 Pod清单,下载Image镜像,并启动容器。
架构图如下:
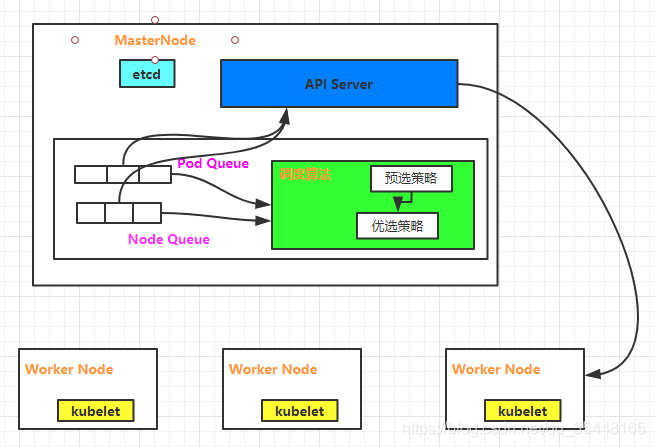
(1)预选调度策略:遍历所有目标Node,刷选出符合Pod要求的候选节点
(2)优选调度策略:在(1)的基础上,采用优选策略算法计算出每个候选节点的积分,积分最高者胜出
简单来说就是先找到可用的,再找到最好的
1.5.1预选策略
PodFitsHostPorts: Checks if a Node has free ports (the network protocol kind) for the Pod ports the Pod is requesting.
PodFitsHost: Checks if a Pod specifies a specific Node by its hostname.
PodFitsResources: Checks if the Node has free resources (eg, CPU and Memory) to meet the requirement of the Pod.......
1.5.2 优选策略
SelectorSpreadPriority: Spreads Pods across hosts, considering Pods that belong to the same Service, StatefulSet or ReplicaSet.
InterPodAffinityPriority: Computes a sum by iterating through the elements of weightedPodAffinityTerm and adding “weight” to the sum if the corresponding PodAffinityTerm is satisfied for that node; the node(s) with the highest sum are the most preferred.......
