kubernetes核心组件之scheduler详解
1、kube-schedule简介
scheduler是kubernetes的调度器,主要任务是把定义的pod分配到集群的节点上,其在调度时需要考虑一下问题:
- 公平:如何保证每个节点都能被分配资源;
- 资源高效利用:集群所有资源最大化被使用;
- 效率:调度的性能要好,能够尽快的对大批量的pod完成调度工作;
- 灵活:允许用户根据自己的需求控制调度的逻辑;
1.1 kubernetes scheduler 基本原理
kubernetes scheduler 作为一个单独的进程部署在 master 节点上,它会 watch kube-apiserver 进程去发现 PodSpec.NodeName 为空的 Pod,然后根据指定的算法将 Pod 调度到合适的 Node 上,这一过程也叫绑定(Bind)。scheduler 的输入是需要被调度的 Pod 和 Node 的信息,输出是经过调度算法筛选出条件最优的 Node,并将该 Pod 绑定到这个 Node 上。Scheduler结构图如下所示:
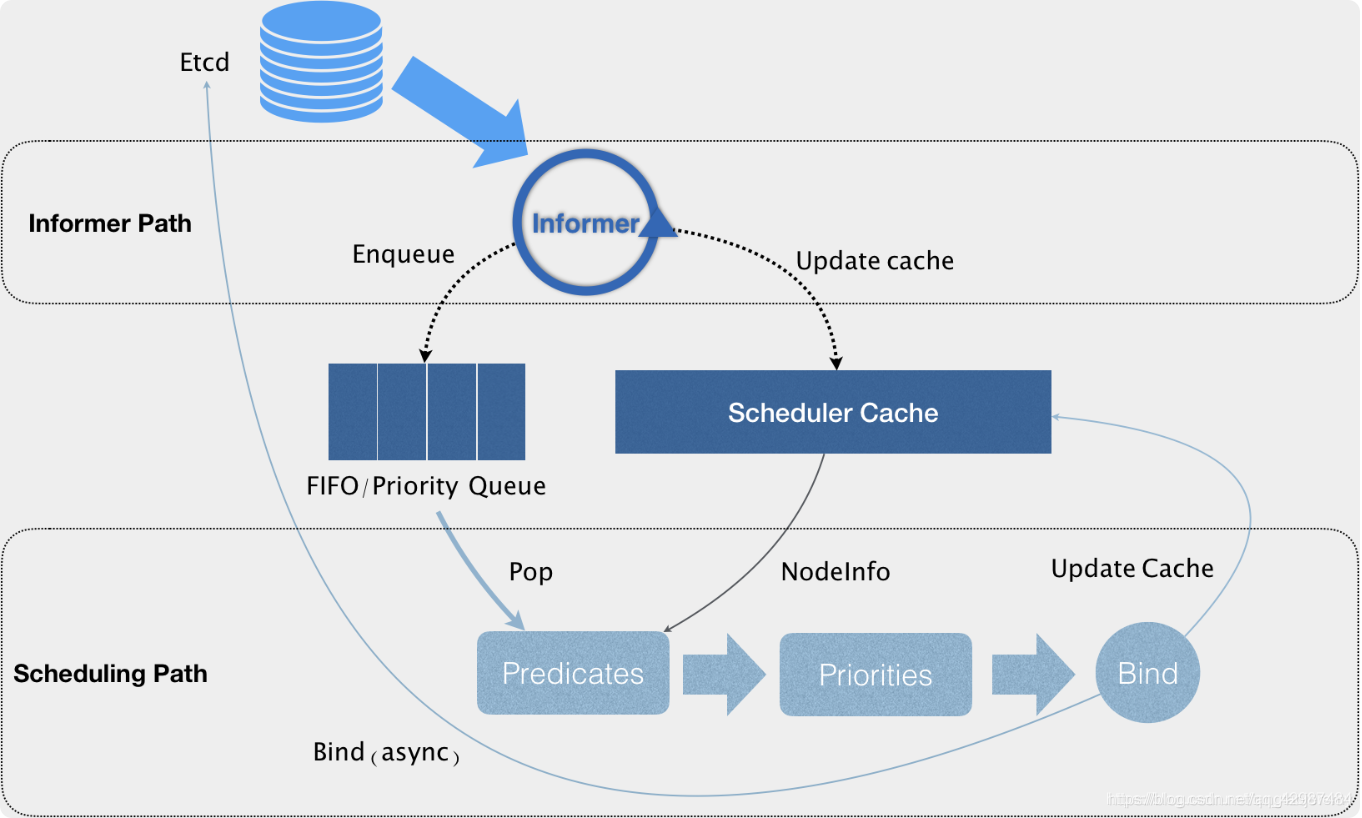
通过上图我们可以看到,调度器实际上主要是由两个控制循环来完成对pod,service等的调度的。
- Informer Path
第一个循环Informer Path中,调度器通过一系列的informer来对pod,node,service等信息进行list and watch。当对应资源(比如pod)有改变时,informer会收到来自api server的变化通知,然后informer会将资源的变动信息更新到调度器缓存中用于后续调度算法的判定依据(这里使用cache的好处就是避免了对api server的大量重复的请求操作,特别是后面的调度算法判定阶段,从而提升调度效率)。
如果有新增的资源,比如有个新的pod,那么informer会将其添加到调度队列中。这里的调度队列是一个优先级的队列,它在保证FIFO的基本功能的同时,还能满足调度器的一些特殊操作,比如基于优先级的抢占操作。 - Scheduling Path
在Scheduling Path中,调度器会从调度队列里不断取出需要调度的资源,然后通过Predicates算法对Scheduler Cache中的Nodes进行过滤,拿到合适的Node列表。然后根据Priorities算法对第一步的Node列表进行打分,选出得分最高的Node。
经过Priorities后,修改资源的nodeName字段为选出的Node,并更新Scheduler Cache中pod和node的信息,然后启动一个异步的线程去请求api server去修改持久化的pod信息。这样做的好处是提高了调度器的调度效率。如果异步线程失败了也无所谓,cache中的信息会随着后续的更新而恢复正常,调度失败的资源会在后续进行重新调度。当然这种基于乐观绑定的设计,就需要kubelet在实际运行资源的时候再次通过基本的调度算法进行确认看当前pod是否能够在当前node运行。同时为了进一步提升调度的效率,调度器对Predicates和Priorities过程都是启动多个线程来并发地对多个资源进行判定,同时在Priorities的阶段以MapReduce的方式来进行打分。整个过程只有在资源出队和更新cache的时候会加锁,从而保证了调度器的执行效率。
1.1.1 scheduler 调度流程
请求及Scheduler调度步骤:
- 预选:根据配置的Predicates Policies(默认为DefaultProvider中定义的default predicates policies集合)过滤掉那些不满足这些Policies的的Nodes,剩下的Nodes就作为优选的输入;
- 优选:根据配置的Priorities Policies(默认为DefaultProvider中定义的default priorities policies集合)给预选后的Nodes进行打分排名;
- 选定:根据Priorities得分最高的Node即作为最适合的Node,该Pod就Bind到这个Node;


Scheduler 调度部分流程讲解如下:
- 首先用户通过 Kubernetes 客户端 Kubectl 提交创建 Pod 的 Yaml 的文件,向Kubernetes 系统发起创建 Pod 的资源请求;
- 命令行工具 Kubectl 向 Kubernetes 集群即 APIServer 用 的方式发送“POST”请求,即创建 Pod 的请求;
- APIServer 接收到请求后把创建 Pod 的信息存储到 Etcd 中;
- 从集群运行那一刻起,资源调度系统 Scheduler 采用 watch 机制就会定时去监控 APIServer获取 Pod 的信息,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度;
- 而这一个创建Pod对象,在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点。当最佳节点多于1个时,则进行随机选择;
Priorities算法实现:
对每一个 Node, priority functions 会计算出一个 0-10 之间的数字,表示 Pod 放到该 Node 的合适程度,其中 10 表示非常合适,0 表示不合适,priority functions 集合中的每一个函数都有一个权重 (weight),最终的值为 weight 和 priority functions 的乘积,而一个节点的 weight 就是所有 priority functions 结果的加和。
例如,有两个 priority functions: priorityFunc1 和 priorityFunc2,对应的 weight 分别为 weight1 和 weight2,那么 NodeA 的最终得分是:

例如有三个node,其调度流程如下图所示:

1.2 scheduler 调度策略
scheduler 调度策略主要分为两部分Predicates(预选策略)和Priorites(优选策略)。
- 预选策略,Predicates是强制性规则,遍历所有的Node节点,按照具体的预选策略筛选出符合要求的Node列表,如没有Node符合Predicates策略规则,那该Pod就会被挂起,直到有Node能够满足;
- 优选策略,在第一步筛选的基础上,按照优选策略为待选Node打分排序,获取最优者。
一般情况下,使用kube-scheduler的默认调度就能满足大部分需求。kubernetes的调度器是以插件化的形式实现的,方便用户对调度的定制与二次开发。因此用户也可以自定义预选和优选策略。
1.2.1 Predicates(预选策略)
Predicates其实就相当于一个的filter chain,对当前所有的node list进行过滤,最后得到符合调度条件的node list。
随着版本的演进Kubernetes支持的Predicates策略逐渐丰富,v1.0版本仅支持4个策略,v1.7支持15个策略。目前可用的Predicates策略有:
- 一般策略
这一组 filter是最基础的filter,主要判断对应的node是否满足pod的运行条件。
| 策略 | 描述 |
|---|---|
| PodFitsResources | 用于判断当前node的资源是否满足pod的request的资源条件 |
| PodFitsHost | 用于判断当前node的名字是否满足pod所指定的nodeName |
| PodFitsHostPorts | Pod对象拥有spec.hostPort属性时,用于判断当前node可用的端口是否满足pod所要求的端口占用 |
| PodMatchNodeSelector | 用于判断当前node是否匹配pod所定义的nodeSelector或者nodeAffinity |
PS: 此外还有个PodFitsPorts策略(计划停用),由PodFitsHostPorts替代
- Volume相关策略
| 策略 | 描述 |
|---|---|
| NoDiskConflict | 用于判断多个pod所声明的volume是否有冲突,默认没有启用 |
| MaxPDVolumeCountPredicate | 用于判断某种volume是否已经超过所指定的数目 |
| VolumeBindingPredicate | 用于检查pod所定义的volume的nodeAffinity是否与node的标签所匹配 |
| NoVolumeZoneConflict | 检查给定的zone限制前提下,检查如果在此主机上部署Pod是否存在卷冲突 |
| NoVolumeNodeConflict | 检查给定的Node限制前提下,检查如果在此主机上部署Pod是否存在卷冲突 |
| MaxEBSVolumeCount | 确保已挂载的EBS存储卷不超过设置的最大值,默认39 |
| MaxGCEPDVolumeCount | 确保已挂载的GCE存储卷不超过设置的最大值,默认16 |
| MaxAzureDiskVolumeCount | 确保已挂载的Azure存储卷不超过设置的最大值,默认16 |
| CheckVolumeBinding | 检查节点上已绑定和未绑定的PVC是否满足需求 |
- Node相关策略
| 策略 | 描述 |
|---|---|
| MatchNodeSelector | Pod对象拥有spec.nodeSelector属性时,检查Node节点的label定义是否满足Pod的NodeSelector属性需求 |
| HostName | 如果Pod对象拥有spec.hostname属性,则检查节点名称是不是Pod指定的NodeName |
| PodToleratesNodeTaints | Pod对象拥有spec.tolerations属性时,仅关注NoSchedule和NoExecute两个效用标识的污点 |
| PodToleratesNodeNoExecuteTaints | Pod对象拥有spec.tolerations属性时,,是否能接纳节点的NoExecute类型污点,默认没有启用 |
| CheckNodeLabelPresence | 仅检查节点上指定的所有标签的存在性,默认没有启用 |
| CheckServiceAffinity | 将相同Service的Pod对象放置在同一个或同一类节点上以提高效率,默认没有启用 |
| NodeMemoryPressurePredicate | 检查当前node的内存是否充足,只有充足的时候才会调度到该node |
| CheckNodeMemoryPressure | 检查节点内存压力,如果压力过大,那就不会将pod调度至此 |
| CheckNodeDiskPressure | 检查节点磁盘资源压力,如果压力过大,那就不会将pod调度至此 |
| GeneralPredicates | 检查pod与主机上kubernetes相关组件是否匹配 |
| CheckNodeCondition | 检查是否可以在节点报告磁盘、网络不可用或未准备好时将Pod调度其上 |
- Pod相关策略
| 策略 | 描述 |
|---|---|
| PodAffinityPredicate | 用于检查pod和该node上的pod是否和affinity以及anti-affinity规则匹配 |
| MatchInterPodAffinity | 检查节点是否满足Pod对象亲和性或反亲和性条件 |
而针对于这么多规则,调度器在面对一个待调度的pod的时候会同时启动很多个线程来并发地计算所有node是否满足所有的条件,最后将满足条件的node list 返回。当然对于条件计算是有一定顺序的,通常跟node相关的规则会先计算,这样就可以避免一些没有必要的规则校验,比如在一个内存严重不足的node上面计算pod的affinity是没有意义的。
1.2.2 Priorites(优选策略)
当调度器通过Predicates拿到可调度的node list之后,我们则需要通过进一步地对比得到最适合调度的node。
kubernetes用一组优先级函数处理每一个待选的主机。每一个优先级函数会返回一个0-10的分数,分数越高表示主机越“好”,同时每一个函数也会对应一个表示权重的值。最终主机的得分用以下公式计算得出:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
同样,Priorites策略也在随着版本演进而丰富,v1.0版本仅支持3个策略,v1.7支持10个策略,每项策略都有对应权重,最终根据权重计算节点总分。目前可用的Priorites策略有:
| 策略 | 描述 |
|---|---|
| SelectorSpreadPriority | 对于属于同一个service、replication controller的Pod,尽量分散在不同的主机上。如果指定了区域,则会尽量把Pod分散在不同区域的不同主机上。调度一个Pod的时候,先查找Pod对于的service或者replication controller,然后查找service或replication controller中已存在的Pod,主机上运行的已存在的Pod越少,主机的打分越高。 |
| LeastRequestedPriority | 如果新的pod要分配给一个节点,这个节点的优先级就由节点空闲的那部分与总容量的比值(即(总容量-节点上pod的容量总和-新pod的容量)/总容量)来决定。CPU和memory权重相当,比值最大的节点的得分最高。需要注意的是,这个优先级函数起到了按照资源消耗来跨节点分配pods的作用。计算公式如下:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2 |
| BalancedResourceAllocation | 尽量选择在部署Pod后各项资源更均衡的机器。BalancedResourceAllocation不能单独使用,而且必须和LeastRequestedPriority同时使用,它分别计算主机上的cpu和memory的比重,主机的分值由cpu比重和memory比重的“距离”决定。计算公式如下:10 – abs(totalCpu/cpuNodeCapacity-totalMemory/memoryNodeCapacity)*10 |
| NodeAffinityPriority | 节点亲和性选择策略。Node Selectors(调度时将pod限定在指定节点上),支持多种操作符(In, NotIn, Exists, DoesNotExist, Gt, Lt),而不限于对节点labels的精确匹配。另外,Kubernetes支持两种类型的选择器,一种是“hard(requiredDuringSchedulingIgnoredDuringExecution)”选择器,它保证所选的主机必须满足所有Pod对主机的规则要求。这种选择器更像是之前的nodeselector,在nodeselector的基础上增加了更合适的表现语法。另一种是“soft(preferresDuringSchedulingIgnoredDuringExecution)”选择器,它作为对调度器的提示,调度器会尽量但不保证满足NodeSelector的所有要求。 |
| InterPodAffinityPriority | pod亲和性选择策略,类似NodeAffinityPriority,提供两种选择器支持。有两个子策略podAffinity和podAntiAffinity |
| NodePreferAvoidPodsPriority(权重1W) | 判断alpha.kubernetes.io/preferAvoidPods属性,设置权重为10000,覆盖其他策略 |
| TaintTolerationPriority | 使用Pod中tolerationList与Node节点Taint进行匹配,配对成功的项越多,则得分越低。 |
| ImageLocalityPriority | 根据主机上是否已具备Pod运行的环境来打分,得分计算:不存在所需镜像,返回0分,存在镜像,镜像越大得分越高。默认没有启用 |
| EqualPriority | EqualPriority是一个优先级函数,它给予所有节点相等的权重(优先级) |
| ServiceSpreadingPriority | 按Service和Replicaset归属计算Node上分布最少的同类Pod数量,得分计算:数量越少得分越高(作用于SelectorSpreadPriority相同,已经被SelectorSpreadPriority替换) |
| MostRequestedPriority | 在ClusterAutoscalerProvider中,替换LeastRequestedPriority,给使用多资源的节点,更高的优先级。计算公式为:(cpu(10 * sum(requested) / capacity) + memory(10 * sum(requested) / capacity)) / 2动态伸缩集群环境比较适用,会优先调度pod到使用率最高的主机节点,这样在伸缩集群时,就会腾出空闲机器,从而进行停机处理。 默认没有启用 |
1.3 scheduler 的优先级与抢占机制
Kubernetes scheduler 里的一个重要机制,即:优先级(Priority )和抢占(Preemption)机制。从 v1.8 开始,kube-scheduler 支持定义 Pod 的优先级,从而保证高优先级的 Pod 优先调度。v1.8 -v1.10默认不开启,从 v1.11 开始默认开启。
- 优先级(Priority ):Pod对象的重要程度,会影响节点上Pod的调度顺序和驱逐次序;
- 抢占(Preemption)机制:一个Pod对象无法被调度时,调度器会尝试抢占(驱逐)较低优先级的Pod对象,以便可以调度当前Pod;
这里所讲的优先级(Priority )与调度优选策略中的优先级(Priorities)不同,前面所讲的优先级指的是节点优先级,而我们这里所说的优先级 pod priority 指的是 Pod 的优先级,高优先级的 Pod 会优先被调度,或者在资源不足低情况牺牲低优先级的 Pod,以便于重要的 Pod 能够得到资源部署。
在 Kubernetes 里,优先级和抢占机制是在 Kubernetes 1.8 及其以后的版本才逐步可用的。
注: 抢占不遵循 PodDisruptionBudget;
1.3.1 背景
对于普通的pod,在调度失败之后,其调度任务会被pending,直到该pod被更新或者集群的状态发生变化,调度器才会对这个 Pod 进行重新调度。
但在有时候,我们希望的是这样一个场景。当一个高优先级的 Pod 调度失败后,该 Pod 并不会被“搁置”,而是会“挤走”某个 Node 上的一些低优先级的 Pod 。这样就可以保证这个高优先级 Pod 的调度成功。这个特性,其实也是一直以来就存在于 Borg 以及 Mesos 等项目里的一个基本功能。
1.3.2 作用
优先级和抢占机制,解决的是 Pod 调度失败时该怎么办的问题。当 Pod 无法被调度时,scheduler 会尝试抢占(驱逐)低优先级的 Pod,使得这些挂起的 pod 可以被调度。
1.3.3 怎么样使用优先级和抢占
-
启用优先级和抢占功能:
在 v1.8-v1.10 版本中的开启方法为(从 v1.11 开始默认开启):apiserver 配置: --feature-gates=PodPriority=true --runtime-config=scheduling.k8s.io/v1alpha1=true kube-scheduler 配置: --feature-gates=PodPriority=true如果需要关闭优先级和抢占,则可把 PodPriority 这个命令行标识从启动参数中移除,或者将它的值设置为false,然后再重启 API server 和 scheduler。功能关闭后,原来的 Pod 会保留它们的优先级字段,但是优先级字段的内容会被忽略,抢占不会生效,在新的 pod 创建时,您也不能设置 PriorityClassName。
-
创建优先级类别(PriorityClass):
创建一个不受命名空间约束的PriorityClass对象,它定义了优先级类名跟优先级整数值的映射;
yaml格式如下:apiVersion: v1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false description: "This priority class should be used for XYZ service pods only."注意:PriorityClass是非namespace隔离的,是global的。因此metadata下面是不能设置namespace field的。
-
使用优先级和抢占功能:
在创建PriorityClass 之后,您在创建 Pod 时就能在模板文件中指定需要使用的 PriorityClass 的名称。优先级准入控制器通过 priorityClassName 字段查找优先级数值并且填入 Pod 中。如果没有找到相应的 PriorityClass,Pod 将会被拒绝创建。
yaml格式如下:apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: containers: - name: nginx image: nginx imagePullPolicy: IfNotPresent priorityClassName: high-priority
1.3.4 PriorityClass
PriorityClass 是一个不受命名空间约束的对象,它定义了优先级类名跟优先级整数值的映射。它的名称通过 PriorityClass 对象 metadata 中的 name 字段指定。值在必选的 value 字段中指定。值越大,优先级越高。
PriorityClass 对象的值可以是小于或者等于 10 亿的 32 位任意整数值。更大的数值被保留给那些通常不应该取代或者驱逐的关键的系统级 Pod 使用。集群管理员应该为它们想要的每个此类映射创建一个 PriorityClass 对象。
PriorityClass 还有两个可选的字段:globalDefault 和 description。globalDefault 表示 PriorityClass 的值应该给那些没有设置 PriorityClassName 的 Pod 使用。整个系统只能存在一个 globalDefault 设置为 true 的 PriorityClass。如果没有任何 globalDefault 为 true 的 PriorityClass 存在,那么,那些没有设置 PriorityClassName 的 Pod 的优先级将为 0。
description 字段的值可以是任意的字符串。它向所有集群用户描述应该在什么时候使用这个 PriorityClass。
注1:如果您升级已经存在的集群环境,并且启用了该功能,那么,那些已经存在系统里面的 Pod 的优先级将会设置为 0。
注2:此外,将一个 PriorityClass 的 globalDefault 设置为 true,不会改变系统中已经存在的 Pod 的优先级。也就是说,PriorityClass 的值只能用于在 PriorityClass 添加之后创建的那些 Pod 当中。
注3:如果您删除一个 PriorityClass,那些使用了该 PriorityClass 的 Pod 将会保持不变,但是,该 PriorityClass 的名称不能在新创建的 Pod 里面使用。
PriorityClass 示例:
piVersion: v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
1.3.5 Pod priority
有了一个或者多个 PriorityClass 之后,您在创建 Pod 时就能在模板文件中指定需要使用的 PriorityClass 的名称。优先级准入控制器通过 priorityClassName 字段查找优先级数值并且填入 Pod 中。如果没有找到相应的 PriorityClass,Pod 将会被拒绝创建。
下面的 YAML 是一个使用了前面创建的 PriorityClass 对 Pod 进行配置的示例。优先级准入控制器会检测配置文件,并将该 Pod 的优先级解析为 1000000。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
1.3.6 抢占机制
Pod 生成后,会进入一个队列等待调度。scheduler 从队列中选择一个 Pod,然后尝试将其调度到某个节点上。如果没有任何节点能够满足 Pod 指定的所有要求,对于这个挂起的 Pod,抢占逻辑就会被触发。当前假设我们把挂起的 Pod 称之为 P。抢占逻辑会尝试查找一个节点,在该节点上移除一个或多个比 P 优先级低的 Pod 后, P 能够调度到这个节点上。如果节点找到了,部分优先级低的 Pod 就会从该节点删除。Pod 消失后,P 就能被调度到这个节点上了。
- 抢占算法(genericScheduler.Preempt)
意义:
选择一个最合适的node用于抢占;
概念:
- preemptor:发起抢占的pod称为preemptor(抢占者)。
- victim:如果preemptor在某个node上发起抢占,则该node上被删除的pod称为victim(牺牲者)。
- nominate:如果preemptor确定要在一个node上发起抢占,则preemptor先被“提名”。
- nomianted node:preemptor发起抢占所在的node称为“提名node”。
流程:
- 判断pod是否有资格执行抢占(podEligibleToPreemptOthers):如果pod.status.nominatedNodeName被设置了,并且nominated node上存在正在终止的pod且优先级更低,说明抢占行为正在进行中,那么preemptor(抢占者)不应该再执行抢占,则这次抢占失败。
- 选出可以调度的潜在的node(nodesWherePreemptionMightHelp):针对所有node,如果node (a) 没有predicate failed,或者(b) 有某种类型的predicate failed但仍然可以抢占,则该node是一个潜在的node。
- 针对潜在node,选择victim pod(selectNodesForPreemption):以node为粒度,16个goroutine并发处理,对每个node处理流程如下(这是一个模拟过程,node上的pod被“删除”和“释放”的操作都是在该node的副本上执行的):
(a) . 将当前node上的比preemptor(抢占者)优先级低的pod按优先级从高到低排序;同时也将这些低优先级pod从当前node上删除,这些pod就是候选的victim(牺牲者)。
(b). 检查preemptor(抢占者)是否可以调度到当前node上,如果不能,则当前node不适合抢占,直接返回。
(c). 根据victim(牺牲者)的PDB是否被违反,将victim(牺牲者)划分为两组。每组中的pod顺序依然是按优先级从高到低。
(d). 依次释放“PDB被违反的victim(牺牲者)”和“PDB没有被违反的victim(牺牲者)”,每组的释放顺序仍然是按优先级从高到低。每释放一个victim(牺牲者)就判断preemptor(抢占者)能否调度到当前node上,如果能调度,则这个victim(牺牲者)就可以真正释放;如果不能调度,则这个victim(牺牲者)就必须被真正删除,它们是真正的victim(牺牲者)。
总体来说,这是一个“抓大放小”的过程:先从node上删除一批“候选victim(牺牲者)”,再依次把victim(牺牲者)释放回node上,一边释放一边判断preemptor(抢占者)是否依然能调度到node上,直到获取到一个最小的“不可释放的victim(牺牲者)集合”。
至此,所有可调度的node及每个node对应的 (a) victim, 和(b) “PDB违反数量” 就收集到了。每个node对应的victim列表,仍然是按优先级从高到低,列表中第1个victim的优先级最高,这一点后面会用到。
-
用extenders做一次处理,将node与victim再作一次筛选(processPreemptionWithExtenders)。
-
挑选一个最合适的node用于抢占,这个node就是nominated node(pickOneNodeForPreemption):依次检查以下规则,如果某个规则的条件满足则返回那个node,后面的规则不再检查。如果满足规则(b)©(d)(e)条件的node有多个,则认为未找到最合适的node,那么继续检查下一个规则。
(a) 没有victim的node:有任意一个这样的node存在即可。
(b)“PDB违反数量”最少的node。
(c)“最高优先级”最小的node:针对每个node,求它的所有victim的最高的优先级,取“最高优先级”最小的node。
(d)“优先级之和”最小的node:针对每个node,求它的所有victim的优先级之和,取该和最小的node。
(e)“victim数量”最少的node。
(f) 第一个node。
- 获取nominated node上的比preemptor的优先级更低的nominated pod,即“已经被提名的pod”(getLowerPriorityNominatedPods):从schedulingQueue里获取。这些nominated pod原本是要在这个node上发起抢占的,但是由于preemptor比它们优先级更高,所以它们只能让preemptor先抢占。针对这些nominated pod的后续操作就是清除nominated状态。
最后,算法返回:
- nominated node
- nominated node上的victim
- nominated node上的对应的需要被清除“提名”状态的pod
- 判断pod是否可调度到一个node上(podFitsOnNode)
执行完抢占算法之后,preemptor(抢占者)进入调度队列,将在下一个调度周期重新调度。但调度器并不保证preemptor(抢占者)一定会被调度到nominated node上,而是按正常的调度流程执行。在判断一个待调度pod是否能调度到某个node上时,会考虑该node上是否已经存在“nominated pod”,如果存在,将影响待调度pod的调度结果,具体如下:
执行两次predicates算法检查,对应的场景分别是:
场景1:
node上有“nominated pod”。在这些nominated pod中,把比待调度pod的优先级更高或相等的pod加到node上,运行一遍predicates算法。
这一步的意义在于,由于nominated pod的加入,可能失败的predicates是:
(a). 与resource有关的predicates;
(b). pod anti-affinity的predicates;
如果node上有“nominated pod”并且检查成功了,则还要进行第2次检查。
场景2:
node上没有“nominated pod”。这一步的意义在于,调度器并不保证nominated pod一定会调度到该node上,所以在没有nominated pod存在时,当前待调度的pod是有可能调度失败的,因为可能违反pod affinity predicates。
这两次检查的结果可能是:
- 场景1存在且检查失败 => 返回失败
- 场景1不存在,场景2检查失败 => 返回失败
- 场景1存在且检查成功,场景2检查失败 => 返回失败
- 场景1不存在,场景2检查成功 => 返回成功
- 场景1存在且检查成功,场景2检查成功 =>返回成功
1.3.7 跨节点抢占
假定节点 N 启用了抢占功能,以便我们能够把挂起的 Pod P 调度到节点 N 上。只有其它节点的 Pod 被抢占时,P 才有可能被调度到节点 N 上面。下面是一个示例:
- Pod P 正在考虑节点 N;
- Pod Q 正运行在跟节点 N 同区的另外一个节点上;
- Pod P 跟 Pod Q 之间有反亲和性;
- 在这个区域内没有跟 Pod P 具备反亲和性的其它 Pod;
- 为了将 Pod P 调度到节点 N 上,Pod Q 需要被抢占掉,但是 scheduler 不能执行跨节点的抢占。因此,节点 N 将被视为不可调度节点。
如果将 Pod Q 从它的节点移除,反亲和性随之消失,那么 Pod P 就有可能被调度到节点 N 上。
2、kube-schedule常用启动参数
Usage: kube-scheduler [flags]
| 参数 | 描述 |
|---|---|
| --add-dir-header | 如果为 true,则将文件目录添加到标题中 |
| --address string | 监听主机IP地址,默认为0.0.0.0监听主机所有主机接口(弃用: 要监听 --port 端口的 IP 地址(对于所有 IPv4 接口设置为 0.0.0.0,对于所有 IPv6 接口设置为 ::)。 请参阅 --bind-address) |
| --algorithm-provider string | 弃用:设置调度算法,ClusterAutoscalerProvider | DefaultProvider,默认为DefaultProvider |
| --alsologtostderr | 设置true则日志输出到stderr,也输出到日志文件 |
| --authentication-kubeconfig string | 指向“核心”kubernetes服务器的kubeconfig文件,具有足够的权限创建tokenaccessreviews. authentic.k8s.io。这是可选的。如果为空,则认为所有令牌请求都是匿名的,在集群中不查找客户端CA。 |
| --authentication-skip-lookup | 如果为 false,则 authentication-kubeconfig 将用于从集群中查找缺少的身份验证配置。 |
| --authentication-token-webhook-cache-ttl duration | 缓存来自 Webhook 令牌身份验证器的响应的持续时间,默认: 10s |
| --authentication-tolerate-lookup-failure | 如果为 true,则无法从集群中查找缺少的身份验证配置是致命的。请注意,这可能导致身份验证将所有请求视为匿名。默认: true |
| --authorization-always-allow-paths stringSlice | 默认: [/healthz]。在授权过程中跳过的 HTTP 路径列表,即在不联系 ‘core’ kubernetes 服务器的情况下被授权的 HTTP 路径。 |
| --authorization-kubeconfig string | 指向具有足够权限以创建 subjectaccessreviews.authorization.k8s.io 的 ‘core’ kubernetes 服务器的 kubeconfig 文件。这是可选的。如果为空,则禁止所有未经授权跳过的请求。 |
| --authorization-webhook-cache-authorized-ttl duration | 缓存来自 Webhook 授权者的 ‘authorized’ 响应的持续时间。默认: 10s |
| --authorization-webhook-cache-unauthorized-ttl duration | 缓存来自 Webhook 授权者的 ‘unauthorized’ 响应的持续时间。默认: 10s |
| --azure-container-registry-config string | 包含 Azure 容器仓库配置信息的文件的路径。 |
| --bind-address ip | 默认: 0.0.0.0。侦听 --secure-port 端口的 IP 地址。集群的其余部分以及 CLI/ Web 客户端必须可以访问关联的接口。如果为空,将使用所有接口(所有 IPv4 接口使用 0.0.0.0,所有 IPv6 接口使用 ::)。 |
| --cert-dir string | TLS 证书所在的目录。如果提供了–tls-cert-file 和 --tls private-key-file,则将忽略此参数。 |
| --client-ca-file string | 如果已设置,由 client-ca-file 中的授权机构签名的客户端证书的任何请求都将使用与客户端证书的 CommonName 对应的身份进行身份验证。 |
| --config string | 配置文件的路径 |
| --contention-profiling | 弃用: 如果启用了性能分析,则启用锁竞争分析 |
| --feature-gates mapStringBool | 一组 key=value 对,描述了 alpha/experimental 特征开关 |
| --hard-pod-affinity-symmetric-weight int32 | 弃用: RequiredDuringScheduling 亲和力不是对称的,但是存在与每个 RequiredDuringScheduling 关联性规则相对应的隐式 PreferredDuringScheduling 关联性规则 --hard-pod-affinity-symmetric-weight 代表隐式 PreferredDuringScheduling 关联性规则的权重。权重必须在 0-100 范围内。此选项已移至策略配置文件。 |
| -h, --help | kube-scheduler 帮助命令 |
| --http2-max-streams-per-connection int | 服务器为客户端提供的 HTTP/2 连接最大限制。零表示使用 golang 的默认值。 |
| --kube-api-burst int32 | 弃用: 发送到kube-apiserver每秒请求量 (default 100) |
| --kube-api-content-type string | 弃用: 发送到kube-apiserver请求内容类型(默认 “application/vnd.kubernetes.protobuf”) |
| --kube-api-qps float32 | 弃用: 与kube-apiserver通信的qps(default 50) |
| --kubeconfig string | 弃用: kubeconfig配置文件路径,该文件包括master认证以及master信息 |
| --leader-elect | 多个master情况设置为true保证高可用,进行leader选举。默认: true |
| --leader-elect-lease-duration duration | 当leader-elect设置为true生效,选举过程中非leader候选等待选举的时间间隔(默认15s) |
| --leader-elect-renew-deadline duration | leader选举过程中在停止leading,再次renew时间间隔,小于或者等于leader-elect-lease-duration duration,也是leader-elect设置为true生效(默认10s) |
| --leader-elect-resource-lock endpoints | 领导者选举期间用于锁定的资源对象的类型,支持的选项是 endpoints (默认) 和configmaps |
| --leader-elect-resource-namespace string | 在领导者选举期间用于锁定的资源对象的命名空间。默认kube-system |
| --leader-elect-retry-period duration | 当leader-elect设置为true生效,获取leader或者重新选举的等待间隔(默认 2s) |
| --lock-object-name string | 弃用:定义lock对象名字(默认"kube-scheduler") |
| --lock-object-namespace string | 弃用: 定义lock对象的namespace(默认"kube-system") |
| --log-backtrace-at traceLocation | 记录日志到file:行号时打印一次stack trace(默认0) |
| --log-dir string | 如果为非空,则在此目录中写入日志文件 |
| --log-file string | 如果为非空,请使用此日志文件 |
| --log-file-max-size uint | 定义日志文件可以增长到的最大值。单位为兆字节。如果值为0,则最大文件大小为无限制。默认1800 |
| 参数 | 描述 |
| 参数 | 描述 |
| --log-flush-frequency duration | 两次日志刷新之间的最大秒数(默认5s) |
| --logtostderr | 写log到stderr(默认 true) |
| --master string | Kubernetes API 服务器的地址(覆盖 kubeconfig 中的任何值) |
| --policy-config-file string | 弃用:具有调度程序策略配置的文件。如果未提供 policy ConfigMap 或 --use-legacy-policy-config = true,则使用此文件 |
| --policy-configmap string | 弃用: 包含调度程序策略配置的 ConfigMap 对象的名称。如果 --use-legacy-policy-config = false,则它必须在调度程序初始化之前存在于系统命名空间中。必须将配置作为键为 ‘policy.cfg’ 的 ‘Data’ 映射中元素的值提供 |
| --policy-configmap-namespace string | 弃用: 策略 ConfigMap 所在的命名空间。如果未提供或为空,则将使用 kube-system 命名空间。默认: “kube-system” |
| --port int | 弃用: 没有认证鉴权的不安全端口(默认10251) |
| --profiling | 弃用: 开启性能分析,通过host:port/debug/pprof/查看 |
| --requestheader-allowed-names stringSlice | 客户端证书通用名称列表允许在 --requestheader-username-headers 指定的头部中提供用户名。如果为空,则允许任何由权威机构 --requestheader-client-ca-file 验证的客户端证书。 |
| --requestheader-client-ca-file string | 在信任 --requestheader-username-headers 指定的头部中的用户名之前用于验证传入请求上的客户端证书的根证书包。警告:通常不依赖于传入请求已经完成的授权。 |
| --requestheader-extra-headers-prefix stringSlice | 默认: [x-remote-extra-]。要检查请求头部前缀列表。建议使用 X-Remote-Extra- |
| --requestheader-group-headers stringSlice | 用于检查组的请求头部列表。建议使用 X-Remote-Group。默认: [x-remote-group] |
| --requestheader-username-headers stringSlice | 用于检查用户名的请求头部列表。 X-Remote-User 很常见。默认: [x-remote-user] |
| --scheduler-name string | 弃用: 调度器名,由于哪些pod被调度器进行处理,根据pod的spec.schedulerName(默认"default-scheduler") |
| --secure-port int | 通过身份验证和授权为 HTTPS 服务的端口。如果为 0,则根本不提供 HTTPS。默认: 10259 |
| --skip-headers | 如果为 true,请在日志消息中避免头部前缀 |
| --skip-log-headers | 如果为true,则在打开日志文件时避免头部 |
| --stderrthreshold severity | 达到或超过此阈值的日志转到 stderr( 默认: 2) |
| --tls-cert-file string | 包含默认的 HTTPS x509 证书的文件。(CA证书(如果有)在服务器证书之后并置)。如果启用了 HTTPS 服务,并且未提供 --tls-cert-file 和 --tls-private-key-file,则会为公共地址生成一个自签名证书和密钥,并将其保存到 --cert-dir 指定的目录中。 |
| --tls-cipher-suites stringSlice | 服务器的密码套件列表,以逗号分隔。如果省略,将使用默认的 Go 密码套件。 |
| --tls-min-version string | 支持的最低 TLS 版本。可能的值:VersionTLS10, VersionTLS11, VersionTLS12, VersionTLS13 |
| --tls-private-key-file string | 包含与 --tls-cert-file 匹配的默认 x509 私钥的文件。 |
| --tls-sni-cert-key namedCertKey | 默认: []。一对 x509 证书和私钥文件路径,可选地后缀为完全限定域名的域模式列表,并可能带有前缀的通配符段。如果未提供域模式,则获取证书名称。非通配符匹配胜过通配符匹配,显式域模式胜过获取名称。 对于多个密钥/证书对,请多次使用 --tls-sni-cert-key。例如: “example.crt,example.key” 或者 “foo.crt,foo.key:*.foo.com,foo.com”。 |
| --use-legacy-policy-config | 弃用: 设置为 true 时,调度程序将忽略策略 ConfigMap 并使用策略配置文件 |
| -v, --v Level | 日志级别详细程度的数字 |
| --version version[=true] | 打印版本信息并退出 |
| --vmodule moduleSpec | 以逗号分隔的 pattern = N 设置列表,用于文件过滤的日志记录 |
| --write-config-to string | 如果已设置,请将配置值写入此文件并退出。 |
3、kube-schedule安装部署
注意:以下kube-schedule安装部署是在k8s的etcd、apiserver组件已部署后的前提下部署验证的;否则单独部署的话,服务启动成功后,服务日志信息会提示dial tcp 127.0.0.1:8080: connect: connection refused等连接拒绝之类的信息,这个是因为kube-schedule是通过访问apiserver获取信息数据的,所以必须先部署好apserver;
3.1 二进制方式安装部署
- 下载地址:https://github.com/kubernetes/kubernetes (包含了k8s所必须的组件,如kube-apiserver、kubelet、kube-scheduler、kube-controller-manager等等)
- 在windows下进入https://github.com/kubernetes/kubernetes后,点击如CHANGELOG-1.16.md文件查看对应的版本(1.16版本)和下载的文件;
- 选择Server Binaries的kubernetes-server-linux-amd64.tar.gz下载
- 在windows下载后通过lrzsz工具执行rz上传到linux上(linux上无法直接通过wget https://dl.k8s.io/v1.16.4/kubernetes.tar.gz下载);
- 解压后生成kubernetes目录,把/kubernetes/service/bin/下的kube-scheduler复制到/opt/kubernetes/bin下;
-
创建schduler配置文件kube-scheduler
cat > /opt/kubernetes/cfg/kube-scheduler <<EOF KUBE_SCHEDULER_OPTS="--logtostderr=true \ --v=4 \ --master=127.0.0.1:8080 \ --leader-elect" EOF 参数说明: * --logtostderr 写log到stderr而不到日志文件 * --v 日志等级 * --master 连接本地apiserver * --leader-elect 当该组件启动多个时,自动选举(HA) -
systemd管理schduler,创建kube-scheduler服务文件
cat > /usr/lib/systemd/system/kube-scheduler.service <<EOF [Unit] Description=Kubernetes Scheduler Documentation=https://github.com/kubernetes/kubernetes [Service] EnvironmentFile=-/opt/kubernetes/cfg/kube-scheduler ExecStart=/opt/kubernetes/bin/kube-scheduler $KUBE_SCHEDULER_OPTS Restart=on-failure [Install] WantedBy=multi-user.target EOF -
启动kube-scheduler服务
systemctl daemon-reload systemctl enable kube-scheduler systemctl start kube-scheduler -
验证kube-scheduler服务是否启动成功
systemctl status kube-scheduler 若失败可通过查看服务日志定位问题: journalctl _PID=<PID>|vim - 执行命令查看scheduler组件是否健康正常 kubectl get cs scheduler -o yaml
3.2 镜像方式安装部署
-
下载kube-scheduler镜像
可在docker hub官网上搜索kube-scheduler合适的镜像下载,如我选择gcrio/kube-scheduler-amd64镜像,执行docker pull gcrio/kube-scheduler-amd64:v1.9.1-beta.0进行下载;
下载后执行docker tag docker.io/gcrio/kube-scheduler-amd64:v1.9.1-beta.0 kube-scheduler:latest生成kube-scheduler:latest镜像 -
配置kube-scheduler镜像启动参数
KUBE_SCHEDULER_OPTS="--logtostderr=true \ --v=4 \ --master=127.0.0.1:8080 \ --leader-elect" 可通过执行echo $KUBE_SCHEDULER_OPTS查看是否配置成功 -
启动kube-scheduler镜像启动
docker run -d --net='host' --name kube-scheduler kube-scheduler:lates kube-scheduler $KUBE_SCHEDULER_OPTS
注意01:若容器内需要通过
localhost或127.0.0.1直接访问宿主机的localhost,则容器运行的网络模式需要设置为host模式,如--net='host'。这样容器内的localhost和宿主机的localhost就是同一个了。
注意02:若容器启动时命令报错,则可能是容器的kube-scheduler命令可能不一样,可在所下载的镜像上查看,如我所下载的镜像查看如下:
注意03:执行docker run运行容器若报错:/usr/bin/docker-current: Error response from daemon: shim error: docker-runc not installed on system.
解决办法01:
cd /usr/libexec/docker/
sudo ln -s docker-runc-current docker-runc
解决办法02:
vi /etc/docker/daemon.json
添加如下内容:
{
“log-level”:“warn”,
“runtimes”: {
“docker-runc”: {
“path”: “/usr/libexec/docker/docker-runc-current”
}
},
“add-runtime”: “docker-runc=/usr/libexec/docker/docker-runc-current”,
“default-runtime”: “docker-runc”
}
保存退出,执行如下动作:
systemctl daemon-reload
systemctl start docker
注意04:若执行docker run命令启动容器报错exec: “docker-proxy”: executable file not found in $PATH;
解决办法:
查看下 docker-proxy 的位置:cat /usr/lib/systemd/system/docker.service | grep prox
创建一条软连接到 /usr/bin/ 下ln -s /usr/libexec/docker/docker-proxy-current /usr/bin/docker-proxy

-
验证kube-scheduler组件是否健康
kube-scheduler容器成功启动后,可通过执行命令查看scheduler组件是否健康正常:kubectl get cs scheduler -o yaml若scheduler组件不健康,则可通过
docker logs kube-scheduler查看kube-scheduler服务日志是否有报错信息来定位问题。
本文仅是个人学习时的整理收藏,以便回顾所用,内容均来源其它处。
[参考文档]https://www.cnblogs.com/peitianwang/p/11579793.html
[参考文档]https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-scheduler/
