每个人似乎都对胶囊网络(CapsNet)这种新的神经网络架构的出现很兴奋,我也不例外,忍不住用胶囊网络来建立一个路侧交通标志的识别系统,这篇文章就是对这一过程的介绍,当然,也包括胶囊网络的一些基本概念阐述。
项目使用TensorFlow开发,是基于Sara Sabour,Nicholas Frosst和Geoffrey E. Hinton的论文《 胶囊间动态路由 》,代码保存在github。如果你迫不及待想要试试Tensorflow等机器学习框架,可以访问汇智网的Python机器学习在线环境。
卷积神经网络有什么问题?
卷积神经网络(CNN)的问题部分源于其对图像感知的泛化能力,例如一个训练好的图像识别网络可能会对同一图像的旋转版本识别错误,这就是为什么在训练时经常使用数据增强和平均/最大池(Average / Max Pooling)。 池化通过随机选择下一层的神经元子集建立一个新的层。 这可以有效降低上层的计算需求,而且也使得网络减小对特征出现的原始位置的依赖性。 这一简化的依据在于:我们假设特征出现的确切位置对目标识别而言影响不大。
和CNN一样,上层的胶囊可以覆盖更大的图像区域,但是与最大化池不同,我们不会丢弃该区域内目标物体的准确位置信息。
这使得模型对图像中的细微变化可以保持不变的输出。 另一方面,模型有可能忽视图像发生的位移变化。不变意味着无论检测到的字符的顺序和位置是否改变,网络的输出总是相同的。 因此该模型能够理解图像中的特征的旋转和位移,并产生适当的输出。 这对于使用池化来说是不可能的。 这就是启发我们发明这个新架构的原因。
胶囊网络
胶囊网络赋予了模型理解图像中所发生变化的能力,从而可以更好地概括所感知的内容。 要了解这个架构如何运作,重要的是掌握胶囊的概念。
胶囊是一组神经元,其激活向量表示某种特定类型的实体(如对象或对象部分)的实例化参数。
我们习惯从深度角度来谈论深度学习,而胶囊网络则引入了嵌套的概念,嵌套为深度引入了一个新的维度。 不是采用添加层的方法来增加网络的深度,相反,胶囊网络是在另一个层中添加(多个)新的图层。 这有点抽象, 但是当你仔细观察时,就会发现情况并不是那么复杂。 在论文中,这一方法的核心分为两部分: 基础胶囊和数字胶囊 。 在我们的案例中,后一部分将被重命名为交通标志胶囊 。
胶囊和基础胶囊
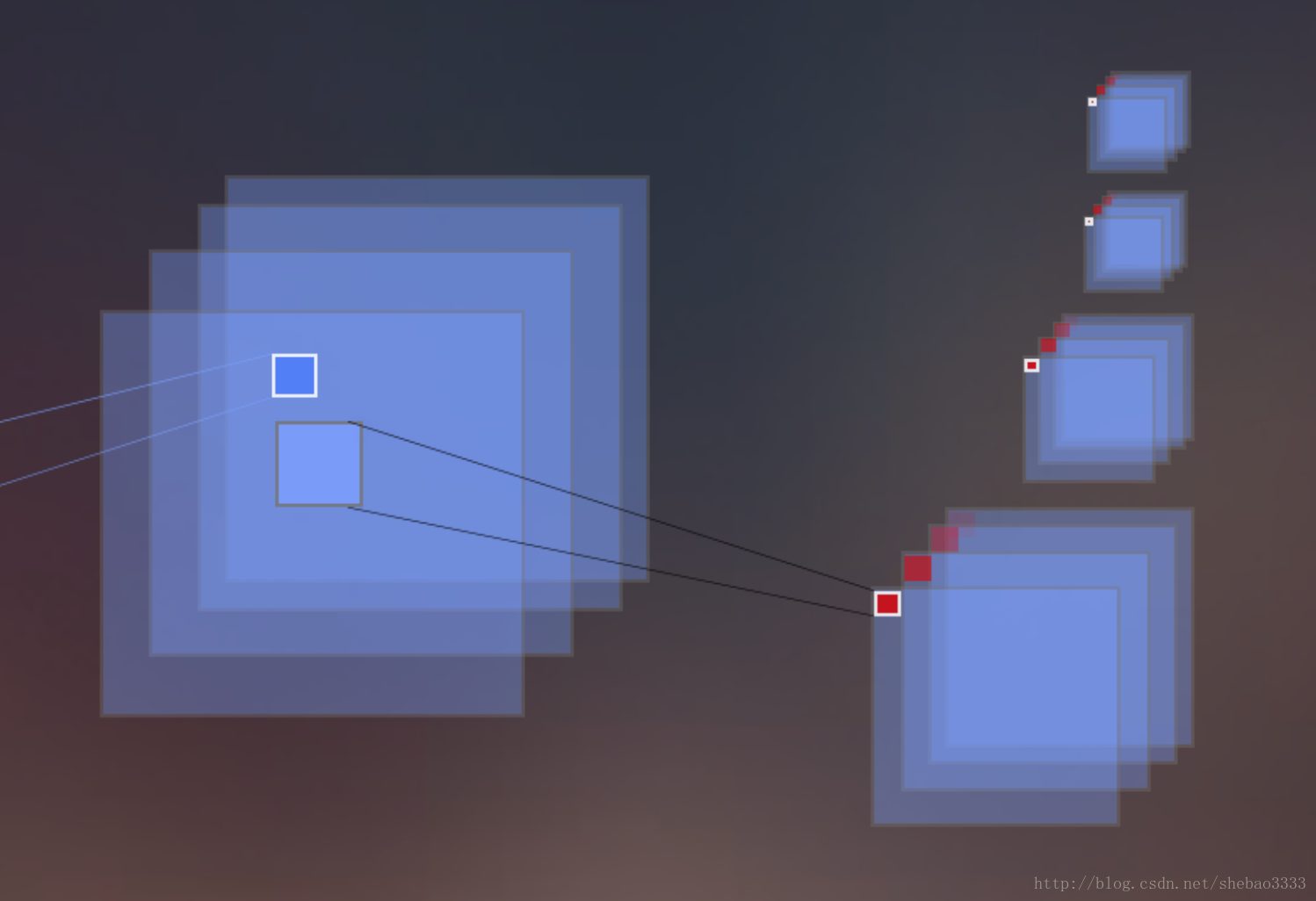
这一层基于经典的卷积计算,创建一个新的由N * C滤波器组成的卷积层。 N表示滤波器的数量,C表示每个胶囊的尺寸。 因此会创建出具有(T,T)大小的N * C个新图像。 在上图中,每个胶囊的值在新创建的图像中以红色显示。 Tensorflow代码如下:
conv = tf.contrib.layers.conv2d(input_layer, N * C, kernel, stride, padding="VALID")
# Shape: (?, T, T, N * C)现在创建好了卷积操作,我们可以重排这些卷积以便创建胶囊操作:
capsules = tf.reshape(conv, shape=(-1, T*T*N, C, 1))
# Shape: (?, T*T*N, C, 1)
# conv[0][0][0][:C] <=> capsules[0]然后我们得到T * T * N个大小为C的胶囊(在这个项目中是1152个胶囊)。 需要指出的是,卷积的第一个C值(见代码中的注释)等于第一个胶囊的值,正如上面代码所示。 最后,原论文中给出了一个新的非线性函数,可以单独应用于每个胶囊。 这个新函数被称为挤压 (Squashing),看起来像这样:
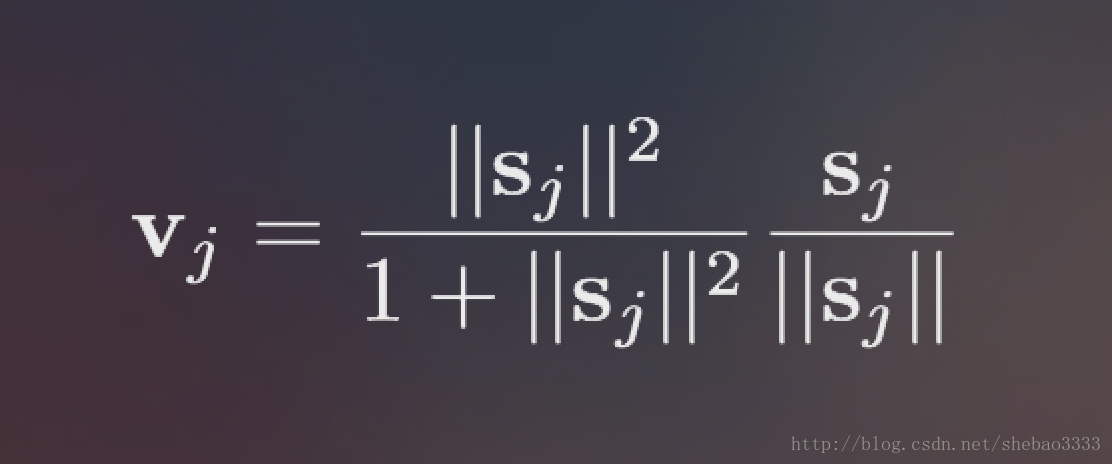
因此,我们使用非线性Squashing函数来确保将短矢量的长度压缩到接近零,而长矢量的长度压缩到略低于1
交通标志胶囊

在本项目中,这个层由43个胶囊组成,每个胶囊代表一种特定的交通标志。 为了确定模型的预测结果,我们可以选择具有最大长度的胶囊。 但在此之前,需要在前一层的1152个胶囊之间进行转换。 这将通过路由的方法完成。 该方法的作用是选中前一层的哪些胶囊与输出层胶囊进行关联。 换句话说,对于每个胶囊,会有一个新的神经网络进行判断:“嘿,这个胶囊对这个类的判别有价值吗?”
使用迭代的路由处理过程,每个活动胶囊将在上面的层中选择一个胶囊,作为它在树中的父节点。
在路由中,对特征的选择不再是像池化那样随意。 在这篇文章中,我不会详细介绍路由所使用的确切公式,论文中有这些公式的描述。 本项目的实现代码在我的github 。 我还在继续改进以使算法更具可扩展性。 对于交通标志胶囊和路由,我在实现中尽量遵循了论文中的数学公式。
图像重建
这种方法有助于引导网络将胶囊向量视为实际的物体,允许在重建之前对每个图像进行编码。 这在正则化方面也得到了很好的结果。
我们使用额外的重建损失来鼓励数字胶囊对输入数字的实例化参数进行编码。
这部分实现代码也包含在项目的github中,代码中的图像重建实现,使用了卷积和最近邻算法来放大图像。 事实上,我不能只是创建一堆简单的层,因为要重建的图像包含3个输出通道。 尽管在MNIST数据中这个实现表现得相当好,但我对其在大规模解决方案中的有效性还存有一些怀疑,不过这只是我的个人观点。
因此,模型最终的损失是基于两种可选的损失:
- 边际损失:基于模型的实际预测。 这是最高标准的胶囊。
- 重建损失:基于图像之间平方差的解码器损失的平均值。
模型架构
由于我处理的数据集与原论文不同,所以模型架构也做了一些调整。
第一个卷积使用256个滤波器、大小为9的核(VALID填充)、RELU激活,dropout取值0.7。
基础胶囊层包含16个滤波器、大小为5的核、16个胶囊。最终获得256个(10,10)大小的滤波器。 即1600个16值胶囊。 最后一层(交通标志胶囊)由大小为32的43个胶囊(43个类)组成。
上述结构的构建代码如下:
def _build_main_network(self, images, conv_2_dropout):
"""
This method is used to create the two convolutions and the CapsNet on the top
**input:
*images: Image PLaceholder
*conv_2_dropout: Dropout value placeholder
**return: **
*Caps1: Output of first Capsule layer
*Caps2: Output of second Capsule layer
"""
# First BLock:
# Layer 1: Convolution.
shape = (self.h.conv_1_size, self.h.conv_1_size, 3, self.h.conv_1_nb)
conv1 = self._create_conv(self.tf_images, shape, relu=True, max_pooling=False, padding='VALID')
# Layer 2: Convolution.
shape = (self.h.conv_2_size, self.h.conv_2_size, self.h.conv_1_nb, self.h.conv_2_nb)
conv2 = self._create_conv(conv1, shape, relu=True, max_pooling=False, padding='VALID')
conv2 = tf.nn.dropout(conv2, keep_prob=conv_2_dropout)
# Create the first capsules layer
caps1 = conv_caps_layer(
input_layer=conv2,
capsules_size=self.h.caps_1_vec_len,
nb_filters=self.h.caps_1_nb_filter,
kernel=self.h.caps_1_size)
# Create the second capsules layer used to predict the output
caps2 = fully_connected_caps_layer(
input_layer=caps1,
capsules_size=self.h.caps_2_vec_len,
nb_capsules=self.NB_LABELS,
iterations=self.h.routing_steps)
return caps1, caps2训练
训练时我使用了Keras的ImageDataGenerator以便进行数据增强。
结果(准确度):
- 训练:99%
- 验证:98%
- 测试:97%
这个结果没能达到经典的卷积神经网络的最佳效果。 但是,考虑到我大部分时间都是在实现胶囊网络,而不是花在超参数调整和图像处理方面,因此对我来说,97%算是初次尝试的好成绩。 我现在还在努力提高这个指标。
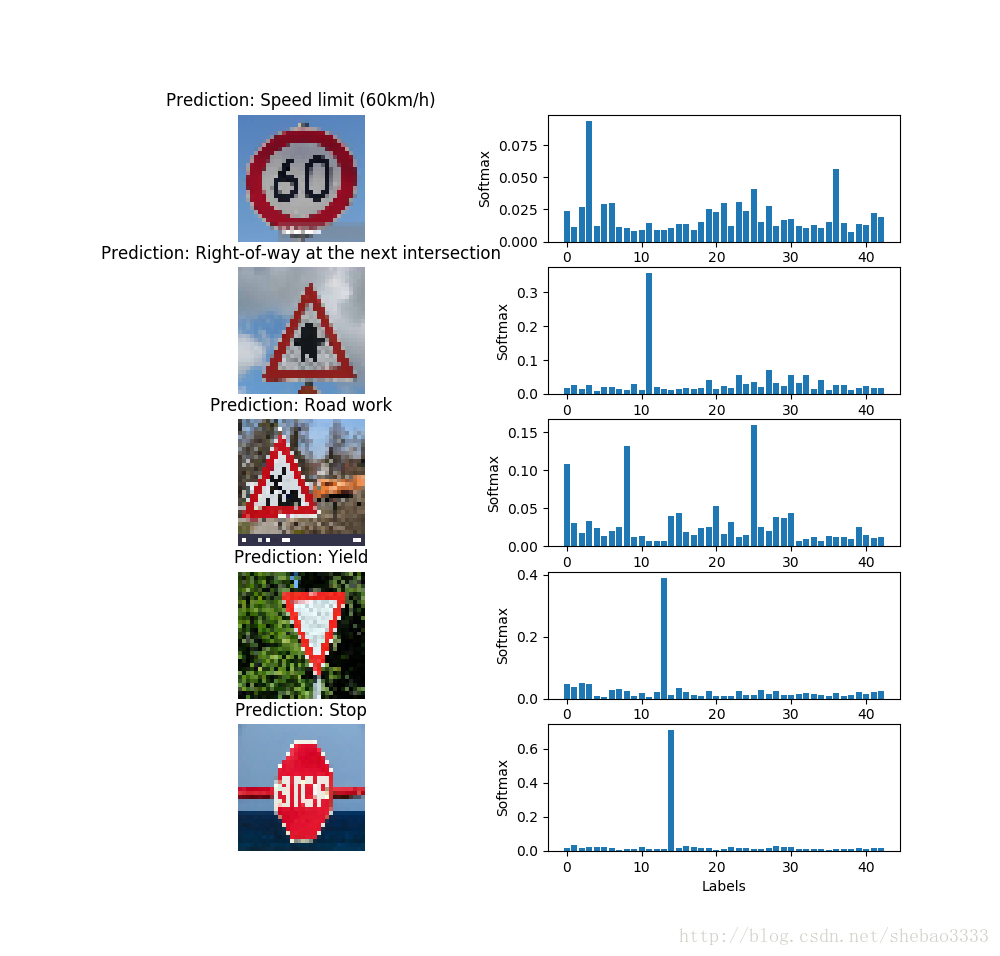
分类示例
如果你喜欢这篇文章,请关注我的头条号:新缸中之脑!
原文:Understand and apply CapsNet on Traffic sign classification