16.1 性能调优理论
16.1.1 基础概念
资源(resource):物理服务器的功能组件,一些软件资源也可以被衡量,比如线程池、进程数等。系统的运行,需要各种资源,对于资源列表的确定,我们可凭借对系统的了解来确定,也可以通过绘制系统的功能块图的方式来确定要衡量的资源。
常见的物理资源如下所示。
- CPU、CPU核数(core)、硬件线程(hardware thread)、虚拟线程(virtual thread)
- 内存
- 网络接口
- 存储设备
- 存储或网络的控制器
- 内部高速互联
负载(load):有多少任务正在施加给系统,也就是系统地输入,要被处理的请求。对于数据库说,负载就包括了客户端发送过来的命令和查询。
负载如果超过了设计能力,往往会导致性能问题,应用程序可能会因为软件应用的配置或系统架构导致性能降低,比如,如果一个应用程序是单线程的,那么无疑它会受制于单线程架构,因为只能利用一个核,后续的请求都必须排队,不能利用其他的核。但性能下降也可能仅仅是因为负载太多了。负载太多将导致排队和高延时,比如,一个多线程应用程序,你会发现所有的CPU都是忙碌的,都在处理任务,这个时候,仍然会发生排队,系统负载也会很高,这种情况很可能是施加了过高的负载。
如果在云中, 你也许可以简单地增加更多的节点来处理过高的负载, 在一般的生产应用中, 简单地增加节点有时解决不了问题, 你需要进行调优和架构迭代。
负载可以分为两种类型:CPU密集型(CPU-bound)和I/O密集型(I/O-bound)。
- CPU密集型指的是那些需要大量计算的应用,它们受CPU资源所限制,也有人称为计算密集型或CPU瓶颈型。
- I/O密集型指的是那些需要执行许多I/O操作的应用,例如文件服务器、数据库、交互式shell,它们期望更小的响应时间。它们受I/O子系统或网络资源所限制。
对于CPU密集型的负载,可以检查和统计那些CPU运算的代码,对于I/O密集型的负载,可以检查和统计那些执行I/O操作最多的代码。这样就可以更有针对性地进行调优。也可以使用使用系统自带的工具或应用程序自己的性能检测工具来进行统计和分析。
吞吐率,很显然,数据库支持的简单查询的吞吐率会比复杂查询的吞吐率大得多,其他应用服务器也是类似的,简单的操作执行得更快,所以对于吞吐,也需要定义我们的系统应处理何种负载。
利用率(utilization) : 利用率用于衡量提供服务的资源的忙碌程度, 它是基于某一段时间间隔内, 系统资源用于真正执行工作的时间的百分比。 即,
利用率=忙的时间/总计时间
利用率可以是基于时间的, 比如CPU的利用率: 某颗CPU的利用率或整体系统的CPU利用率。 比如对于磁盘的利用率, 我们可以使用iostat命令检查%util。
利用率也可以是基于容量的, 它可以表示我们的磁盘、 内存或网络的使用程度, 比如90%的磁盘空间被使用, 80%的内存被使用, 80%的网络带宽被使用等。
可以用高速公路收费站的例子来进行类比。
利用率表现为当前有多少收费亭正在忙于服务。 利用率100%, 就表示所有的收费亭都正在处理收费, 你找不到空闲的收费亭, 因此你必须排队。 那么在高峰时刻, 可能许多时候都是100%的利用率, 但如果给出全天的利用率数据, 也许只有40%, 那么如果只关注全天的这个利用率数据就会掩盖一些问题。
往往利用率的高位会导致资源饱和。 利用率100%往往意味着系统有瓶颈, 可以检查资源饱和度和系统性能加以确定。 该资源不能提供服务的程度被标识为它的饱和度, 后文有资源饱和度的详细解释。
如果是检测的粒度比较大, 那么很可能就会掩盖了偶尔的100%的峰值, 一些资源, 如磁盘, 在60%的利用率的时候, 性能就开始变差了。
响应时间(response time) : 也叫延迟, 指操作执行所需要的耗时。 它包括了等待时间和执行时间, 优化执行时间相对简单, 优化等待时间则复杂多了, 因为要考虑到各种其他任务的影响, 以及资源的竞争使用。 对于一个数据库查询, 响应时间就包括了从客户端发布查询命令到数据库处理查询, 以及传输结果给客户端的所有时间。 延迟可以在不同的环节进行衡量, 比如访问站点的装载时间, 包括DNS延迟、 TCP连接延迟和TCP数据传输时间。 延迟也可以在更高的级别进行理解, 包括数据传输时间和其他时间, 比如从用户点击链接到网页内容传输, 并在用户的电脑屏幕上渲染完毕。 延迟是以时间做量度来衡量的, 可以很方便地进行比较, 其他的一些指标则不那么容易衡量和比较, 比如IOPS, 你可以将其转化为延迟来进行比较。
一般情况下, 我们衡量性能主要是通过响应时间, 而不是使用了多少资源, 优化本质上是在一定的负载下, 尽可能地减少响应时间, 而不是减少资源的占用,比如降低CPU的使用。 资源的消耗只是一个现象, 而不是我们优化的目标。
如果我们能够记录MySQL在各个环节所消耗的时间, 那么我们就可以有针对性地进行调优, 如果我们可以将任务细分为一些子任务, 那么我们就可以通过消除子任务、 减少子任务的执行次数或让子任务执行得更有效率等多种手段来优化MySQL。
伸缩性(scalability) : 对于伸缩性, 有两个层面的意思。 一是, 在资源的利用率不断增加的情况下, 响应时间和资源利用率之间的关系, 当资源利用率升高时,响应时间仍然能够保持稳定, 那么我们就说它的伸缩性好, 但是如果资源利用率一旦升高, 响应时间就开始劣化, 那么我们就认为其伸缩性不佳。 二是, 伸缩性还有一层意义, 表征系统不断扩展的能力, 系统通过不断地增加节点或资源, 处理不断增长的负载, 同时依然能够保持合理的响应时间。
吞吐率(throughput) : 处理任务的速率。 对于网络传输, 吞吐率一般是指每秒传输的字节数, 对于数据库来说, 指的是每秒查询数(QPS) 或每秒事务数
并发(concurrency) : 指的是系统能够并行执行多个操作的能力。 如果数据库能够充分利用CPU的多核能力, 那么往往意味着它有更高的并发处理能力。
容量(capacity) : 容量指的是系统可以提供的处理负荷的能力。 我们在日常运维中有一项很重要的工作就是容量规划, 即确保随着负荷的增长, 我们的系统仍然能够处理负荷, 确保服务良好和稳定。 容量也指我们的资源使用极限, 比如我们的磁盘空间占用, 在磁盘空间到达一定的阈值后, 我们可能还要考虑扩容。
饱和(saturation) : 由于负荷过大, 超过了某项资源的服务能力称为饱和。 饱和度可以用等待队列的长度来加以衡量, 或者用在队列里的等待时间加以衡量。 超过承载能力的工作往往处于等待队列之中或被返回错误, 比如CPU饱和度可用平均运行队列(runq-sz) 来衡量, 比如可以使用iostat命令输出的avgqu-sz指标衡量磁盘饱和度。 比如内存饱和度可以用交换分区的一些指标来衡量。
资源利用率高时, 可能会出现饱和, 图16-1是一个资源利用率、 负载、 饱和之间关系的说明图, 在资源利用率超过100%后, 任务不能马上被处理, 需要排队,饱和度就开始随着负载的增加线性增长。 饱和将导致性能问题, 因为新的请求需要排队, 需要时间进行等待。 饱和并不一定要在利用率100%的时候才会发生, 它取决于资源操作的并行度。
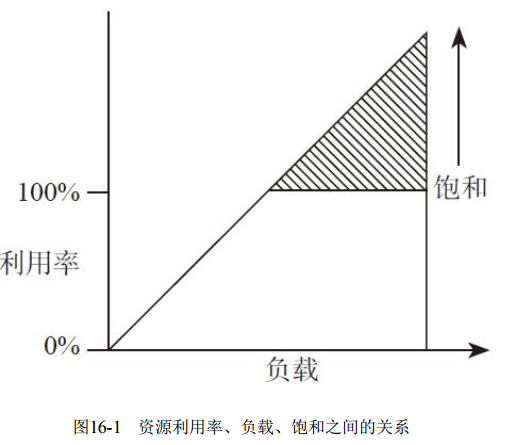
饱和不一定能被发现, 生产环境监控系统、 监控脚本时存在一个容易犯的错误, 那就是采样的粒度太粗, 比如每隔几分钟进行采样, 可能就会发现不了问题,但问题却会发生在短时间的几十秒内。 突然的利用率的高峰也很容易导致资源饱和, 出现性能问题。
一般来说, 随着负荷的上升, 吞吐率也将上升, 吞吐曲线开始时会一直是线性的, 我们的系统响应时间在开
始的一个阶段会保持稳定, 但是到达某个点后, 性能就会开始变差, 响应时间变得更长, 以后随着负荷的继续增加, 此时我们的吞吐率将不能再继续增长, 甚至还会下降, 而响应时间也可能会变得不可接受。 有一种例外情况是, 应用服务器返回错误状态码, 比如Web服务器返回503错误, 由于基本上不消耗资源, 难以到达极限, 所以返回错误码的吞吐曲线会保持线性。
对于性能的看法其实比较主观, 一个性能指标是好还是坏, 可能取决于研发人员和终端用户的期望值。 所以, 如果我们要判断是否应该进行调优, 那么我们需要对这些指标进行量化, 当我们量化了指标, 确定了性能目标时, 这样的性能调优才更科学, 才更容易被理解和沟通一致。
以下将简要叙述三个基础理论: 阿姆达尔定律、 通用扩展定律和排队论。
16.1.2 阿姆达尔定律
阿姆达尔定律(Amdahl’s law) 是计算机科学界的一项经验法则, 因IBM公司的计算机架构师吉恩·阿姆达尔而得名。 吉恩·阿姆达尔在1967年发表的论文中提出了这个重要定律。
阿姆达尔定律主要用于发现当系统的部分组件得到改进, 整体系统可能得到的最大改进。 它经常用于并行计算领域, 用来预测应用多个处理器时理论上的最大加速比。 在性能调优领域, 我们利用此定律有助于我们解决或缓解性能瓶颈问题。
阿姆达尔定律的模型阐释了我们在现实生产中串行资源争用时候的现象。 图16-2分别展示了线性扩展(linear scaling) 和按阿姆达尔定律扩展的加速比(speedup) 。 图16-2中的曲线是符合阿姆达尔定律的加速比曲线。 在一个系统中, 不可避免地会有一些资源必须要串行访问, 这就限制了我们的加速比, 即使我们增加了并发数(横轴) , 但取得的效果并不理想, 难以获得线性扩展的能力(图16-2中的直线) 。
以下介绍中, 系统、 算法、 程序都可以看作是优化的对象, 笔者在此不会加以区分, 它们都有串行的部分和可以并行的部分。
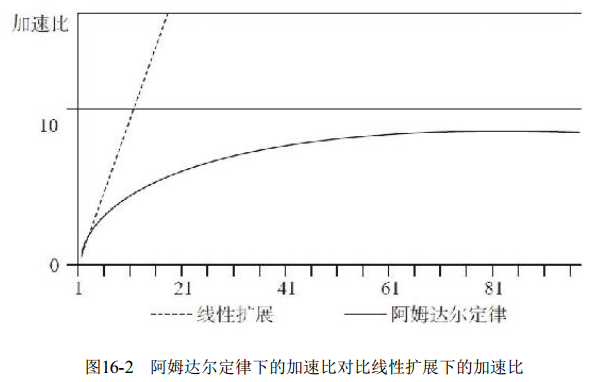
在并行计算中, 使用多个处理器的程序的加速比受限制于程序串行部分的执行时间。 例如, 如果一个程序使用一个CPU核执行需要20个小时, 其中的部分代码只能串行, 需要执行1个小时, 其他19小时的代码执行可以并行, 那么, 如果不考虑有多少CPU可用来并行执行程序, 最小的执行时间也不会少于1个小时(串行工作的部分) , 因此加速比被限制为最多20倍(20/1) 。
加速比越高, 证明优化效果越明显。
阿姆达尔定律可以用如下公式表示:
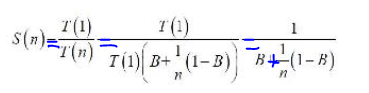
其中,
S(n): 固定负载下, 理论上的加速比。
B: 串行工作部分所占比例, 取值范围为0~1。
n: 并行线程数、 并行处理节点个数。
以上公式具体说明如下。
加速比=没有改进前的算法耗时T(1)/改进后的算法耗时T(n)。
我们假定算法没有改进之前, 执行总时间是1(假定为1个单元) 。 那么改进后的算法, 其时间应该是串行工作部分的耗时(B) 加上并行部分的耗时(1-B)/n, 由于并行部分可以在多个CPU核上执行, 所以并行部分实际的执行时间是(1-B)/n
根据这个公式, 如果并行线程数(我们可以理解为CPU处理器数量) 趋于无穷, 那么加速比将与系统的串行工作部分的比例成反比, 如果系统中有50%的代码需要串行执行, 那么系统的最大加速比为2。 也就是说, 为了提高系统的速度, 仅增加CPU处理器的数量不一定能起到有效的作用, 需要提高系统内可并行化的模块比重, 在此基础上合理增加并行处理器的数量, 才能以最小的投入得到最大的加速比。
下面对阿姆达尔定律做进一步说明。 阿姆达尔这个模型定义了固定负载下, 某个算法的并行实现相对串行实现的加速比。 例如, 某个算法有12%的操作是可以并行执行的, 而剩下的88%的操作不能并行, 那么阿姆达尔定律声明, 最大加速比是1/(1-0.12) =1.136。 如上公式中的n趋向于无穷大, 那么加速比S=1/B=1/(1-0.12) 。
再例如, 对于某个算法, 可以并行的比例是P, 这部分并行的代码能够加速S倍(S可以理解成CPU核的个数, 即新代码的执行时间为原来执行时间的1/S) 。 如果此算法有30%的代码可以被并行加速, 即P等于0.3, 这部分代码可以被加速2倍, 即S等于2。 那么, 使用阿姆达尔定律计算其整个算法的加速比如下。
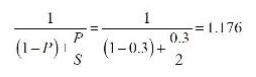
以上公式和前一个公式是类似的, 只是前一个公式的分母是用串行比例B来表示的。
再例如, 某项任务, 我们可以分解为4个步骤, P1、 P2、 P3、 P4, 执行耗时占总耗时百分比分别是11%、 18%、 23%和48%。 我们对它进行优化, P1不能优化, P2可以加速5倍, P3可以加速20倍, P4可以加速1.6倍。 那么改进后的执行时间计算如下。
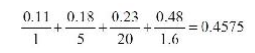
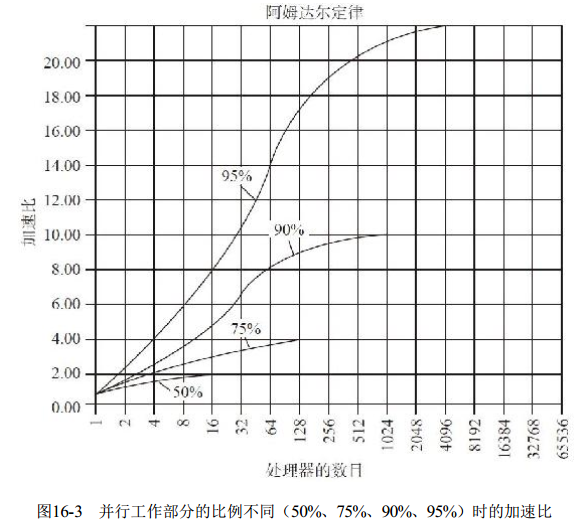
图16-3演示了并行工作部分的比例不同时的加速比曲线, 我们可以观察到, 加速比受限制于串行工作部分的比例, 当95%的代码都可以进行并行优化时, 理论上的最大加速比会更高, 但最高不会超过20倍。
阿姆达尔定律也用于指导CPU的可扩展设计。 CPU的发展有两个方向, 更快的CPU或更多的核。 目前看来发展的重心偏向了CPU的核数, 随着技术的不断发展, CPU的核数在不断地增加, 目前我们的数据库服务器配置四核、 六核都已经比较常见了, 但有时我们会发现虽然拥有更多的核, 当我们同时运行几个程序时,只有少数几个线程处于工作中, 其他的并未做什么工作。 实践当中, 并行运行多个线程往往并不能显著地提升性能, 程序往往并不能有效地利用多核。 在多核处理器中加速比是衡量并行程序性能的一个重要参数, 能否有效降低串行计算部分的比例和降低交互开销决定了能否充分发挥多核的性能, 其中的关键在于: 合理划分任务、 减少核间通信。
16.1.3 通用扩展定律
可扩展性指的是, 我们通过不断地增加节点来满足不断增长的负载需求, 这样的一种能力。 可是, 很多人提到了可扩展性, 却没有给它一个清晰的定义和量化标准。 实际上, 系统可扩展性是可以被量化的, 如果你不能量化可扩展性, 你就不能确保它能够满足需要。 USL(universal scalability law, 通用扩展定律) 就提供了一种方式, 让我们可以量化系统的可扩展性。
USL, 即通用扩展定律, 由尼尔·巩特尔博士提出, 相对比阿姆达尔定律, USL增加了一个参数β表示“一致性延迟”(coherency delay) 。 图16-4是它的模型图, 纵轴表示容量, 横轴表示并发数。

USL可以用如下公式进行定义。

其中,
C(N): 容量。
0≤α,β<1。
α: Contention, 争用的程度, 由于等待或排队等待共享资源, 将导致不能线性扩展。
β: Coherency, 一致性延迟的程度, 由于节点之间需要交互以使数据保持一致, 因此会带来延迟。 为了维持数据的一致性, 将导致系统性能恶化, 即随着N的上升, 系统吞吐率反而会下降。 当这个值为0时, 我们可以将其看作是阿姆达尔定律。
N: Concurrency, 并发数, 理想情况下是线性扩展的。 如果是衡量软件的可扩展性, 那么N可以是客户端/用户并发数, 在固定的硬件配置下(CPU数不变) , 不断增加客户端/用户, 以获取性能吞吐模型, 我们的压力测试软件, 如LoadRunner、 sysbench即为此类。 如果是衡量硬件的可扩展性, 那么N可以是CPU的个数, 我们不断增加CPU的个数, 同时保持每颗CPU上的负载不变, 即如果每颗CPU施加100个用户的负载, 每增加一颗CPU, 就增加100个用户, 那么一台32个CPU的机器, 需要3200个用户的并发负载。
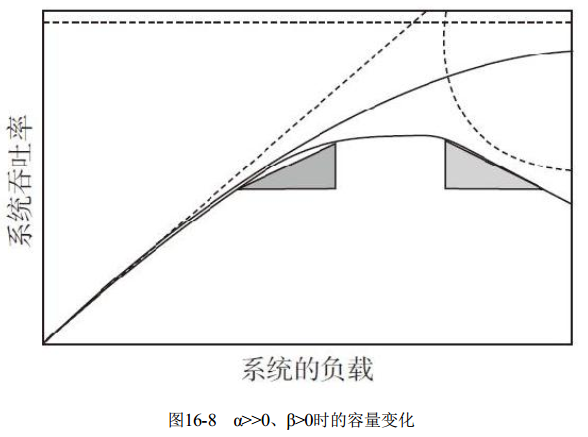
下面我们来看看图16-5到图16-8所示的4个图, 对应在不同负载下容量(吞吐能力) 的变化。
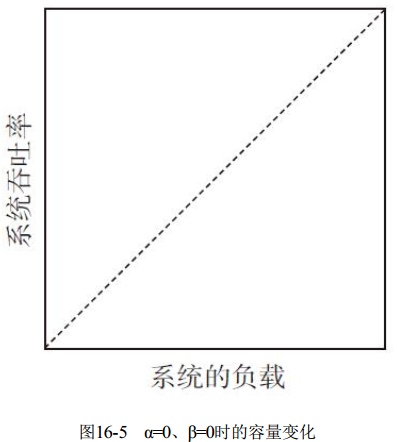
图16-5中, α=0、 β=0, 此时, 随着负载的升高, 系统吞吐是线性上升的, 即我们所说的线性扩展, 这是很理想化的一种情况, 每份投入必然会获得等值回报,但很难无限进行下去, 性能模型的前面部分可能会表现为线性扩展。
图16-6中, α>0、 β=0, 此时对于共享资源的争用将导致性能曲线不再线性增长。

图16-7中, α>>0、 β=0。 此时共享资源的争用大大增加, 我们将看到一种“收益递减”的现象, 即我们的持续投入资源(比如金钱) 变大, 但是所取得的收益都越来越小。
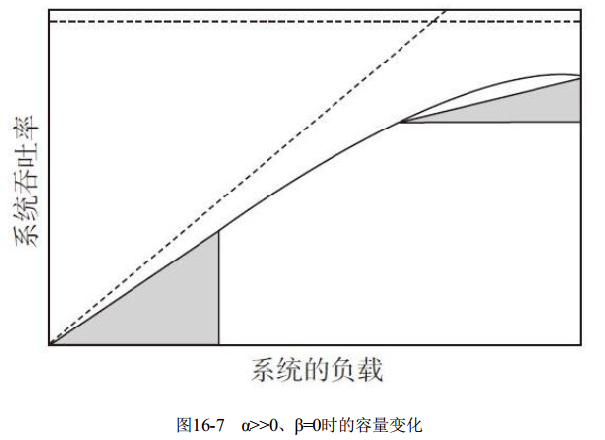
图16-8中, α>>0、 β>0。 此时β参数开始影响我们的性能曲线, 我们除了共享资源的争用, 还需要应对系统内各个节点的通信、 同步状态的开销。 此时性能曲线将会变差, 回报趋向于负值。
USL应用很广, 如压力测试工具结果分析, 对磁盘阵列、 SAN和多核处理器及某些类型的网络I/O建模, 分析内存颠簸、 高速缓存未命中导致的延时等场景。 由于它的应用范围很广, 所以也称之为通用扩展定律。
USL一些具体的应用场景如下。
(1) 模拟压力测试
以下例子, 如图16-9所示, 将不断增加虚拟用户(横轴表示的Virtual users) , 记录其吞吐率(纵轴表示的Throughput) , 然后通过绘制的图形得到性能吞吐的模型

(2) 检测错误的测量结果
有时我们进行测试, 会发现我们的测量输出结果不符合模型, 这时我们需要审视下, 是否我们的测量方式存在问题或受到了其他因素的干扰? 需要找出是什么原因导致的非预期的行为。
(3) 性能推断
如果扩展性很差, 我们可以通过公式和图得知是α(对共享资源的争用) 还是β(一致性延迟) 应该承担更大的责任。
(4) 性能诊断
USL公式虽然简单易用, 但普通人也许无法从中找到解决问题的思路和方法。 因为所有的信息都被浓缩为2个参数α和β。 然而, 应用程序开发者和系统架构师可能依据这些信息, 就能轻易地找到问题症结所在。
(5) 对生产环境收集的性能数据进行分析
对生产环境的性能数据(图形) 进行分析, 可以让我们确定合适的工作负载(比如并发线程数、 CPU个数) 。
(6) “扩展区”(scalability zone) 概念的应用
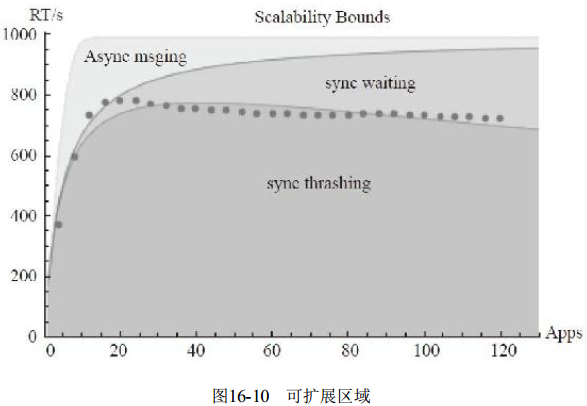
我们看下图16-10, 我们绘制不同场景下的性能曲线, 这些曲线定义了可扩展区域Async msging、 Sync waiting、 Sync thrashing。 程序的性能点图跨越了多个区域。 在超过15个并发的时候, 性能曲线进入另外一个区域Sync waiting, 扩展性变差, 这是因为“同步排队”(synchronous queueing) 的影响所导致的。
16.1.4 排队论
(1) 排队论的历史
排队论(queueing theory) 起源于20世纪初的电话通话。 Agner Krarup Erlang, 一个在丹麦哥本哈根电话交换局工作的工程师, 通过研究人们打电话的方式, 发明了人们需要等待多久的公式, 厄朗发表了一篇著名的文章“自动电话交换中的概率理论的几个问题的解决”。 随着以后的发展, 排队论成为数学中一门重要的学科, 20世纪50年代初, 大卫·坎达(David G.Kendall) 对排队论做了系统的研究, 使排队论得到了进一步的发展。
(2) 定义
排队论也称为随机服务系统理论、 排队理论, 是数学运筹学的分支学科。 它是研究服务系统中排队现象随机规律的学科。 排队论广泛应用于电信、 交通工程、计算机网络、 生产、 运输、 库存等各项资源共享的随机服务系统和工厂、 商店、 办公室、 医院等的设计。
排队是我们每个人都很熟悉的现象。 因为为了得到某种服务必须排队。 有一类排队是有形的, 例如在售票处等待买票的排队, 加油站前汽车等待加油的排队等; 还有一类排队是无形的, 例如电话交换机接到的电话呼叫信号的排队, 等待计算机中心处理机处理的信息的排队等。 为了叙述的方便, 排队者无论是人、 物或信息, 以后都统称为“顾客”。 服务者无论是人或事物, 例如一台电子计算机也可以是排队系统中的服务者, 以后都统称为“服务台”。
排队现象是我们不希望出现的现象, 因为人在排队至少意味着是在浪费时间; 物的排队则说明了物资的积压。 但是排队现象却无法完全消失, 这是一种随机现象。 顾客到达间隔时间的随机性和为顾客服务时间的随机性是排队现象产生的主要原因。 如果上述的两个时间都是固定的, 那么我们就可以通过妥善安排来完全消除排队现象。
排队论是研究排队系统在不同的条件下(最主要的是顾客到达的随机规律和服务时间的随机规律) 产生的排队现象的随机规律性。 也就是要建立反映这种随机性的数学模型。 研究的最终目的是为了运用这些规律, 对实际的排队系统的设计与运行做出最优的决策。
(3) 排队论的一般模型
图16-11是排队论的一般模型图
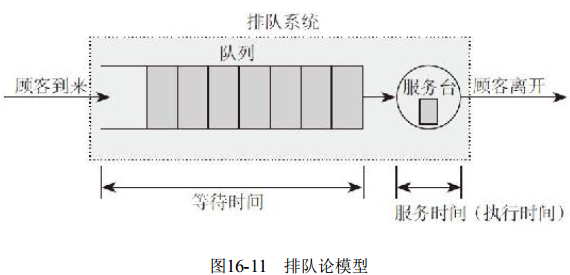
其中, 服务台用于服务队列中的顾客, 可以多个服务台并发工作。
图16-11中的排队系统, 各个顾客从顾客源出发, 随机地来到服务机构, 按一定的排队规则等待服务, 直到按一定的服务规则接受服务后离开排队系统。
对于一个服务系统来说, 如果服务机构过小, 以致不能满足要求服务的众多顾客的需要, 那么就会产生拥挤现象而使服务质量降低。 因此, 顾客总是希望服务机构越大越好, 但是, 如果服务机构过大, 人力和物力方面的开支就会相应地增加, 从而就会造成浪费, 因此研究排队模型的目的就是要在顾客需要和服务机构的规模之间进行权衡和决策, 使其达到合理的平衡。
(4) 理论归纳
在计算机领域, 许多软硬件组件都可以模型化为排队系统。 我们可以使用排队理论分析排队现象, 分析队列的长度、 等待时间、 利用率等指标。
排队理论基于许多数学和统计理论, 比如概率理论、 随机过程理论、 Erlang-C公式(Erlangs C formula) 、 李特尔法则。
以下简单介绍排队认的一些理论。 详细的内容可参考Neil J.Gunther的图书《The Practical Performance Analyst》 。
李特尔法则(Little’s law)
李特尔法则(Little's law)
李特尔法则可以用如下公式来表示。
L=λW
这个公式定义了一个系统中的平均访问请求数=平均到达速率×平均服务时间
比如, 我们有一个系统, 平均到达速率是10000次请求/s, 每个请求需要花费0.05s来处理, 即平均服务时间为0.05s, 那么根据李特尔法则, 服务器在任何时刻都将承担10000×0.05=500个请求的业务处理。 如果过了一段时间, 由于客户端流量的上升, 并发的访问速率达到了20000次请求/s, 这种情况下, 我们该如何改进系统的性能呢? 根据李特尔法则, 我们有如下两种方案。
1) 提高服务器的并发处理能力, 即20000×0.5=1000。
2) 减少服务器的平均服务时间, 即W=L/λ=500/20000=0.025s。
排队论表示法
我们可以用肯德尔表示法(Kendall’s notation) 来对排队系统进行分类, 肯德尔表示法可使用如下的简化形式:
A/S/m
其中,
A: 到达的规则, 即到达的时间间隔的分布, 可能是随机的、 确定型的或泊松分布等其他分布方式。
S: 服务规则, 即指服务时间的分布, 可能是固定的或指数的等其他分布方式。
m: 服务台个数, 一个或多个。表示顾客到达的间隔时间和服务时间的分布常用的约定符号分别如下。
M: 指数分布, 在概率论和统计学中, 指数分布(Exponential Distribution) 是一种连续概率分布。 指数分布可以用来表示独立随机事件发生的时间间隔, 比如旅客进机场的时间间隔、 中文维基百科新条目出现的时间间隔, 等等。
D: 确定型(Deterministic) 。
G: 一般(General) 服务时间的分布。
一些常见的排队系统模型具体如下。
·M/M/1: 表示顾客相继到达的间隔时间为指数分布、 服务时间为指数分布、 单服务台。
·M/M/c: 表示顾客相继到达的间隔时间为指数分布、 服务时间为指数分布、 多服务台。
·M/G/1: 表示顾客相继到达的间隔时间为指数分布、 服务时间为一般服务时间分布、 单服务台。
·M/D/1: 表示顾客相继到达的间隔时间为指数分布、 服务时间为确定型时间分布、 单服务台。 比如我们的旋转磁盘可用此模型进行分析。
16.2 诊断工具
我们需要熟悉Linux下常用的诊断性能的工具, 确切地说, 我们需要在平时不使用这些命令的时候, 就能够熟练应用它, 这样我们在实际诊断性能问题的时候,才可以快速使用它们, 而不是事到临头才去学某个命令应该如何使用。
我们进行性能调优的首要目的是需要找到系统的瓶颈所在。 最常见的瓶颈是内存、 I/O或CPU。 Linux提供了一系列的工具来检查系统和查找瓶颈。 一些工具揭示了系统的总体健康状态, 一些工具则提供了特定的系统组件信息。 使用这些工具将是一个好的起点, 有助于我们确定性能调优的方向。
现实中, 真正出现性能问题时, 往往会有许多现象发生, 发现一个现象并不难, 难的是定位问题的根源, 是什么因素的影响最大。 当你具备了知识, 能够熟练使用各种工具, 了解数据库、 操作系统、 硬件等各种组件的机制, 通过检查各种工具和命令输出的数据, 你对找到问题的根源所在将会越来越有经验。
使用工具要避免只使用自己熟悉的工具, 因为工具在不断地进化中, 所以, 如果有了更好的工具, 那么花一些学习成本也是值得的。
对于性能的优化, 我们往往有许多种工具可以选择, 这也会造成一些困扰, 因为不同工具的功能有重叠, 甚至大部分都有重复, 这样不仅浪费了资源, 也让用户的学习成本变得更高, 因为可能你要熟悉许多工具而不只是一种。
16.2.1 OS诊断工具
sar、 vmstat、 iostat都是工具包sysstat(the systemmonitoring tool) 里的命令, 如果你的系统中没有这些命令, 那么你需要安装sysstat包。
本节对sar会做比较详细的介绍, 因为其他命令收集的信息与它类似, 因此本节将不对其他命令做详细说明, 仅仅列出一些需要关注的要点
1.sar
sar(systemactivity reporter, 系统活动情况报告) 命令是系统维护的重要工具, 主要用于帮助我们掌握系统资源的使用情况, 可以从多方面对系统的活动进行报告, 报告内容包括: 文件的读写情况、 系统调用的使用情况、 磁盘I/O、 CPU效率、 内存使用状况、 进程活动及与IPC有关的活动等。
sar通过cron定时调用执行以收集和记录信息, 默认情况下, Linux每10分钟运行一次sar命令来收集信息, 如果你认为时间跨度太长, 不容易发现性能问题, 你也可以更改调度任务的间隔, 修改/etc/cron.d/sysstat即可。
cat sysstat # run system activity accounting tool every 10 minutes */10 * * * * root /usr/lib64/sa/sa1 1 1然后重启 crond 生效
/etc/init.d/crond restartsar 命令的常用格式如下。
sar [ options... ] [ <interval> [ <count> ] ]
sar如果不加参数, 则默认是读取历史统计信息, 你可以指定interval和count对当前的系统活动进行统计。 其中参数的具体说明如下。 interval为 采样间隔, count为采样次数, 默认值是1。 options为命令行选项, sar命令常用的选项分别如下。 ·-A: 所有报告的总和。 ·-u: 输出CPU使用情况的统计信息。 ·-v: 输出inode、 文件和其他内核表的统计信息。 ·-d: 输出每一个块设备的活动信息, 一般添加选项-p以显示易读的设备名。 ·-r: 输出内存和交换空间的统计信息。 ·-b: 显示I/O和传送速率的统计信息。 ·-c: 输出进程的统计信息, 每秒创建的进程数。 ·-R: 输出内存页面的统计信息。 ·-y: 终端设备的活动情况。 ·-w: 输出系统交换活动的信息, 即每秒上下文切换次数。( 1 ) CPU 资源监控
例如, 每 10s 采样一次, 连续采样 3 次, 观察 CPU 的使用情况, 并将采样结果以二进制的形式存入当前目录下的文件 test 中, 需要键入如下命令:
sar -u -o test 10 3
输出项说明如下。 ·CPU: all表示统计信息为所有CPU的平均值。 我们可以使用sar-P n查看某颗CPU。 ·%user: 显示在用户级别运行和使用CPU总时间的百分比。 ·%nice: 显示在用户级别, 用于nice操作, 所占用CPU总时间的百分比。 ·%system: 在核心级别(kernel) 运行所占用CPU总时间的百分比。 ·%iowait: 显示用于等待I/O操作所占用CPU总时间的百分比。 ·%idle: 显示CPU空闲时间所占用CPU总时间的百分比。 1) 若%iowait的值过高, 则表示硬盘存在I/O瓶颈。 2) 若%idle的值很高但系统响应很慢时, 有可能是CPU正在等待分配内存, 此时应加大内存容量。 3) 若%idle的值持续低于10, 则系统的CPU处理能力相对较低, 表明系统中最需要解决的资源是CPU。( 2 ) 查看网络的统计
语法是sar-n KEYWORD。 KEYWORD常用的值及说明具体如下。 ·DEV: 显示网络设备统计, 如eth0、 eth1等。 ·EDEV: 显示为网络设备错误统计。 ·NFS: 显示NFS客户端活动统计。 ·ALL: 显示所有统计信息。如下命令可查看网络设备的吞吐, 数据每秒更新一次, 总共更新 5 次。
[root@localhost ~]# sar -n DEV 1 5
输出项说明。 ·第一字段: 时间。 ·IFACE: 设备名。 ·rxpck/s: 每秒收到的包。 ·txpck/s: 每秒传输的包。 ·rxbyt/s: 每秒收到的所有包的体积。 ·txbyt/s: 每秒传输的所有包的体积。 ·rxcmp/s: 每秒收到的数据切割压缩的包的总数。 ·txcmp/s: 每秒传输的数据切割压缩的包的总数。 ·rxmcst/s: 每秒收到的多点传送的包。 可以使用grep命令对输出进行过滤, 命令如下。
sar -n DEV 2 5|grep eth1 如果想知道网络设备错误报告, 也就是用来查看设备故障的。 应该用EDEV命令; 比如下面的例子。 sar -n EDEV 2 5( 3 ) 内存分页监控
例如, 每 10s 采样一次, 连续采样 3 次, 监控内存分页, 命令及输出结果如下。
[root@localhost ~]# sar -B 10 3 Linux 2.6.32-696.el6.x86_64 (localhost.localdomain) 2018年04月19日 _x86_64_ (1 CPU) 06时35分50秒 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff 06时36分00秒 0.00 0.00 3.60 0.00 11.61 0.00 0.00 0.00 0.00 06时36分10秒 0.00 0.40 3.91 0.00 11.62 0.00 0.00 0.00 0.00 06时36分20秒 0.00 0.00 3.10 0.00 11.70 0.00 0.00 0.00 0.00 平均时间: 0.00 0.13 3.54 0.00 11.64 0.00 0.00 0.00 0.00
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB) pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB) fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor) majflt/s:每秒钟产生的主缺页数. pgfree/s:每秒被放入空闲队列中的页个数 pgscank/s:每秒被kswapd扫描的页个数 pgscand/s:每秒直接被扫描的页个数 pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数 %vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比( 4 ) I/O 和传送速率监控
例如, 每 10s 采样一次, 连续采样 3 次, 需要键入如下命令。
sar -b 10 3
输出项说明如下。 ·tps: 每秒钟物理设备的I/O传输总量。 ·rtps: 每秒钟从物理设备读入的数据总量。 ·wtps: 每秒钟向物理设备写入的数据总量。 ·bread/s: 每秒钟从物理设备读入的数据量, 单位为块/s。 ·bwrtn/s: 每秒钟向物理设备写入的数据量, 单位为块/s。( 5 ) 进程队列长度和平均负载状态监控
例如, 每 10s 采样一次, 连续采样 3 次, 监控进程队列长度和平均负载状态, 命令如下。
sar -q 10 3
输出项说明如下。 ·runq-sz: 运行队列的长度(等待运行的进程数) 。 ·plist-sz: 进程列表中进程(processes) 和线程(threads) 的数量。 ·ldavg-1: 最后1分钟的系统平均负载(systemload average) 。 ·ldavg-5: 过去5分钟的系统平均负载。 ·ldavg-15: 过去15分钟的系统平均负载。( 6 ) 系统交换活动信息监控
例如, 每 10s 采样一次, 连续采样 3 次, 监控系统交换活动信息, 命令如下。
sar -W 10 3
输出项说明如下。 ·pswpin/s: 每秒系统换入的交换页面(swap page) 数量。 ·pswpout/s: 每秒系统换出的交换页面数量。( 7 ) 设备使用情况监控
例如, 每 10s 采样一次, 连续采样 3 次, 报告设备使用情况, 需要键入如下命令。
# sar -d 10 3 -p
其中, 参数-p可以打印出sda、 hdc等易读的磁盘设备名称, 如果不使用参数-p, 设备节点则有可能是dev8-0、 dev22-0这样的形式。 输出项说明如下。 ·tps: 每秒从物理磁盘I/O的次数。 多个逻辑请求会被合并为一个I/O磁盘请求, 一次传输的大小是不确定的。 ·rd_sec/s: 每秒读扇区的次数。 ·wr_sec/s: 每秒写扇区的次数。 ·avgrq-sz: 发送到设备的请求的平均大小, 单位为扇区。 ·avgqu-sz: 磁盘请求队列的平均长度。 ·await: 从请求磁盘操作到系统完成处理, 每次请求的平均消耗时间, 包括请求队列的等待时间, 单位是毫秒。 ·svctm: 系统处理每次请求的平均时间, 不包括在请求队列中消耗的时间。 ·%util: I/O请求占CPU的百分比, 比率越大, 说明越饱和。 1) avgqu-sz的值较低时, 设备的利用率较高。 2) 当%util的值接近100%时, 表示设备带宽已经占满。( 8 ) 查看历史统计信息
有时我们希望能够看到历史性能统计信息, 可以进入目录 /var/log/sa , 使用 sar–f saXX 命令查看历史数据, 例如,
sar -f sa22默认将显示整天的数据。 我们可以加上 -s 选项指定特定时间段的数据, 例如,
sar -q -f sa13 -s 14:00:00 | head -n 10以上命令将只显示 13 日 14 点之后的 load 的统计数据, 且只显示最前面的 10 条记录。
( 9 ) 输出 inode、 文件和其他内核表的统计信息
sar -v 10 3
输出项说明如下。 ·dentunusd: 目录高速缓存中未被使用的条目数量。 ·file-nr: 文件句柄(file handle) 的使用数量。 ·inode-nr: 索引节点句柄(inode handle) 的使用数量。 要想判断系统的瓶颈问题, 有时需要将几个sar命令选项结合起来。 ·怀疑CPU存在瓶颈, 可用sar-u和sar-q等来查看。 ·怀疑内存存在瓶颈, 可用sar-B、 sar-r和sar-W等来查看。 ·怀疑I/O存在瓶颈, 可用sar-b、 sar-u和sar-d等来查看。