MySQL面试题
列举几种数据库存储引擎,并说一说InnoDB和MyISAM的区别
存储引擎:MyISAM、InnoDB、HEAP、BOB、ARCHIVE、CSV等。
MyISAM是非事务的存储引擎,适合用于频繁查询的应用。表锁,不会出现死锁。适合小并发。
Innodb是支持事务的存储引擎,适合于插入和更新操作比较多的应用。设计合理的话是行锁(最大区别就在锁的级别上),适合大并发。
| 存储引擎 | MyISAM | InnoDB |
| 事务处理 | 不支持 | 支持 |
| 数据行锁定 | 不支持,只有表锁定 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 表空间大小 | 相对小 | 相对大 |
| 全文索引 | 支持 | 不支持 |
| COUNT问题 | 无 | 执行COUNT(*)查询时,速度慢 |
谈谈数据库的隔离级别
Read Uncommitted(未提交读):在Read Uncommitted级别,事务的修改,即使没有提交,对其他事务也是可见的。事务可以读取其它事务未提交的数据,这也被称为脏读(Dirty Read)。这个级别会导致很多问题,从性能上说,Read Uncommitted不会比其他级别好太多,但缺乏其他级别的很多好处。除非真的有非常必要的理由,在实际应用中一般很少使用。
Read Committed(已提交读):大多数数据库的默认隔离级别都是Read Committed(但MySQL 不是)。Read Committed满足隔离性的简单定义:一个事务开始时,只能看见已经提交的事务所作的修改。换句话说,一个事务从开始直到提交之前,所作的任何修改对其它事务是不可见的。这个级别有时候也叫做不可重复读(Nonrepeatable Read),同一条数据可能有两个事务先后进行过操作,存在先后两次读取到的数据不一致(中间存在另一个事务提交的数据)的情况。执行两次同样的查询,得到的结果不一致。
Repeatable Read(可重复读,MySQL默认隔离级别):Repeatable Read解决了不可重复读的问题。该级别保证了在同一个事务中多次读取同样的记录的结果是一致的。但是理论上,可重复读隔离级别还是无法解决另外一个幻读问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另一个事务又在这个范围内插入了新记录,当之前的事务再次读取该范围的记录,会产生幻行。也就是说可重复读只会在修改事务有效,比如一个事务先后读取同一个范围的记录,而在这中间另一个事务对某一条记录做了修改,当前事务两次读取到的结果是一样的,但是如果是新增数据就会产生幻读的现象。为了解决在可重复读级别下发生的幻读的问题,MySQL的InnoDB和XtraDB存储引擎通过多版本并发控制机制(MVCC)解决了幻读的问题。
Serializable(可串化读):Serializable是最高的隔离级别。它通过强制事务串行执行,避免幻读问题。简单来说Serializable会在读取的每一行上加锁,所以可能导致大量的超时和锁竞争问题。实际开发中也很少用到这个隔离级别,只有在非常需要保证数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。
说出一条SQL语句的关键字执行顺序
顺序:
- FROM
- ON
- JOIN
- WHERE
- GROUP BY (开始使用SELECT中的别名,后面的语句中都可以使用)
- ROLLUP, CUBE, AVG, SUM ...
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP, LIMIT
解析:
- FORM:对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
- ON:对虚表VT1进行ON筛选,只有那些符合<join-condition>的行才会被记录在虚表VT2中。
- JOIN:如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3。from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
- WHERE:对虚拟表VT3进行WHERE条件过滤。只有符合<where-condition>的记录才会被插入到虚拟表VT4中。
- GROUP BY:根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
- ROLLUP | CUBE:对表VT5进行cube或者rollup操作,产生表VT6.
- HAVING:对虚拟表VT6应用having过滤,只有符合<having-condition>的记录才会被 插入到虚拟表VT7中。
- SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
- DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
- ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
- TOP | LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回。
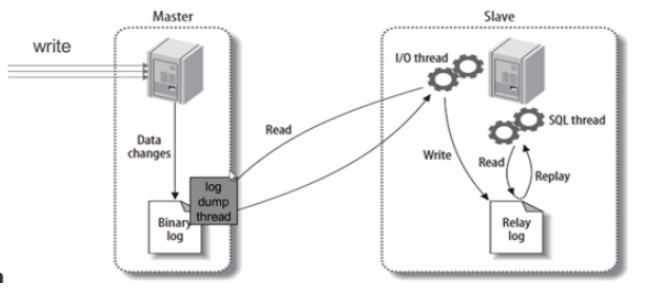
简单说一下MySQL主从同步
为什么需要主从同步:
1. 假如网站使用单机数据库,一旦MySQL宕机,整个网站将无法访问。引入MySQL从库,意图保证网站数据库不宕机或者宕机之后能够快速恢复。
2. Master负责写操作的负载,Slave分摊读操作负载,这样一来的可以大大提高读取的效率。在一般的互联网应用中,经调查发现读/写的比例大概在 10:1左右 ,也就是说大量的数据操作是读操作,这也就是为什么我们会有多个Slave的原因。分离读和写是因为,写操作涉及到锁的问题,不管是行锁、表锁还是块锁,都是降低系统执行效率的事情。读写分离可以有效提高读的效率,保证系统的高可用性。
主从同步:
1.主从同步主要有三种形式:statement、row、mixed
- statement: 会将对数据库操作的sql语句写到binlog中。
- row: 会将每一条数据的变化写道binlog中。
- mixed: statement与row的混合。Mysql决定何时用statement, 何时用row。
2.过程:
MySQL主从同步是异步复制的过程,整个同步需要开启3线程
- Master上开启bin-log日志(记录数据库增加、删除、修改、更新操作)。
- Slave开启I/O线程来请求Master服务器,请求指定bin-log中position点之后的内容。Master端I/O线程响应请求,将bin-log中position之后内容返给salve。Slave将收到的内容存入relay-log中继日志中,生成master.info(记录master ip、bin-log、position、用户名密码)。
- Slave端实时监测relay-log日志有更新,将更新的内容解析成sql语句,在Salve库中执行。
注:DQL数据查询语言,DML数据操纵语言,DDL数据定义语言,DCL数据控制语言。
简述数据库设计的三个范式
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解。
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性。
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
优点:可以尽量得减少数据冗余,更新快,表体积小。
缺点:查询需要多个表进行关联,索引优化困难。
反范式:在原本已满足三范式的基础上再做调整,增加冗余字段。
优点:可以减少表关联查询,可以更好地进行索引优化。
缺点:有数据冗余以及数据异常,数据的修改需要更多的成本。