腾讯一面面试题(Fit微信国际支付)
题目来源于网络,答案为自己整理。
由于问了自己相对熟悉的东西,说了mysql,所以第一轮只问了mysql,40分钟左右:
1.mysql隔离级别有哪些?
| 隔离级别 | 不可重复读 | 脏读 | 幻读 |
|---|---|---|---|
| 读取未提交 | 是 | 是 | 是 |
| 读取已提交 | 是 | 否 | 是 |
| 可重复读 | 否 | 否 | 是 |
| 串行化 | 否 | 否 | 否 |
为什么要设计这几种隔离级别?
- 事务隔离是数据库处理的基础之一,隔离级别是在多个事务同时进行更改和执行查询时候,对结果的性能和可靠性,一致性和可重复性之间的平衡进行微调的设置。可以根据自己的具体业务需要来控制读取数据的策略。
MySQL 中隔离级别 RC 与 RR 的区别
- 资料
- 5.1 RC 与 RR 在锁方面的区别
- 1> 显然 RR 支持 gap lock(next-key lock),而RC则没有gap lock。因为MySQL的RR需要gap lock来解决幻读问题。而RC隔离级别则是允许存在不可重复读和幻读的。所以RC的并发一般要好于RR;
- 2> RC 隔离级别,通过 where 条件过滤之后,不符合条件的记录上的行锁,会释放掉(虽然这里破坏了“两阶段加锁原则”);但是RR隔离级别,即使不符合where条件的记录,也不会是否行锁和gap lock;所以从锁方面来看,RC的并发应该要好于RR;
- 5.2 RC 与 RR 在复制方面的区别(资料1,资料2)
- RC 隔离级别不支持 statement 格式的bin log,因为该格式的复制,会导致主从数据的不一致;只能使用 mixed 或者 row 格式的bin log; 这也是为什么MySQL默认使用RR隔离级别的原因。复制时,我们最好使用:binlog_format=row
- 简单而且,RC隔离级别时,事务中的每一条select语句会读取到他自己执行时已经提交了的记录,也就是每一条select都有自己的一致性读ReadView; 而RR隔离级别时,事务中的一致性读的ReadView是以第一条select语句的运行时,作为本事务的一致性读snapshot的建立时间点的。只能读取该时间点之前已经提交的数据。
- 5.4 RC 支持半一致性读,RR不支持
- RC隔离级别下的update语句,使用的是半一致性读(semi consistent);而RR隔离级别的update语句使用的是当前读;当前读会发生锁的阻塞。
- [ ]半一致性读的优点:
减少了update语句时行锁的冲突;对于不满足update更新条件的记录,可以提前放锁,减少并发冲突的概率。默认隔离级别是啥?
- 可重复读,在同一事务中,读取由第一次读取建立的快照。意味着如果再同一个事务中发出几个纯的(非锁定的)select语句,重复执行同样的查询结果相同。
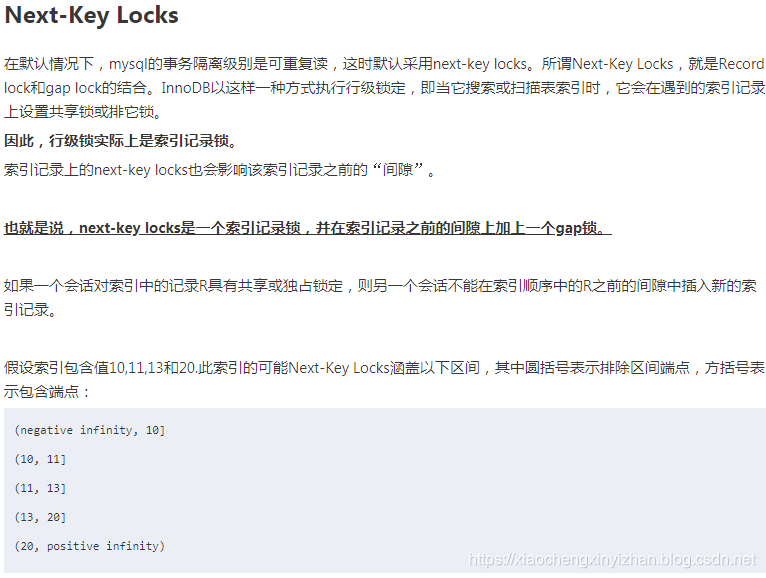
默认级别是如何避免幻读的?
MySQL InnoDB的可重复读并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是next-key locks。
- 对于具有唯一搜索条件的唯一索引,InnoDB只锁定找到索引记录,而不是锁定之前的间隔。
- 对于其他搜索条件,InnoDB锁定扫描的索引范围,使用gap lock或者next-key lock阻止其他会话的插入到范围覆盖的间隙。
有哪些级别用了mvcc?
- MVC运行在RC读取已提交和可重复读RR的隔离级别下。因为RU根本不需要,可串行化的隔离级别是通过加锁来控制的。
mvcc解决的问题:
- 为了提升系统的并发能力,读写之间不冲突的方法。读取数据时候通过一种类似快照的方式将数据保存下来,读锁和写锁不冲突了,不同的事务session会看到自己特定版本的数据,还可以用于事务的回滚。
- 不同级别的辅助实现依靠MVCC,MVCC 在mysql 中的实现依赖的是 undo log(undo log中记录的是数据表记录行的多个版本,也就是事务执行过程中的回滚段,其实就是MVCC 中的一行原始数据的多个版本镜像数据。),read view(主要用来判断当前版本数据的可见性)
这里就要看看read_view的生成机制:
1. read-commited:
函数:ha_innobase::external_lock
if (trx->isolation_level <= TRX_ISO_READ_COMMITTED
&& trx->global_read_view) {
/ At low transaction isolation levels we let
each consistent read set its own snapshot /
read_view_close_for_mysql(trx);
即:在每次语句执行的过程中,都关闭read_view, 重新在row_search_for_mysql函数中创建当前的一份read_view。
这样就可以根据当前的全局事务链表创建read_view的事务区间,实现read committed隔离级别。
2. repeatable read:
在repeatable read的隔离级别下,创建事务trx结构的时候,就生成了当前的global read view。
使用trx_assign_read_view函数创建,一直维持到事务结束,这样就实现了repeatable read隔离级别。
正是因为6中的read view 生成原则,导致在不同隔离级别()下,read committed 总是读最新一份快照数据,而repeatable read 读事务开始时的行数据版本。
如果让你来设计,你还会想到其他方式达到这个效果嘛?
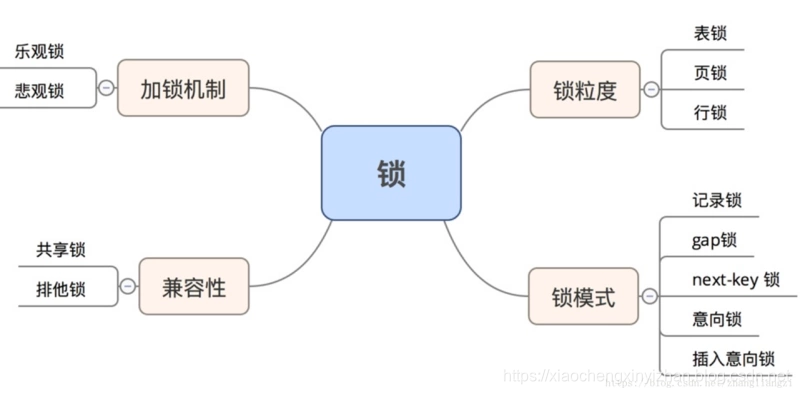
2.mysql锁有了解嘛?
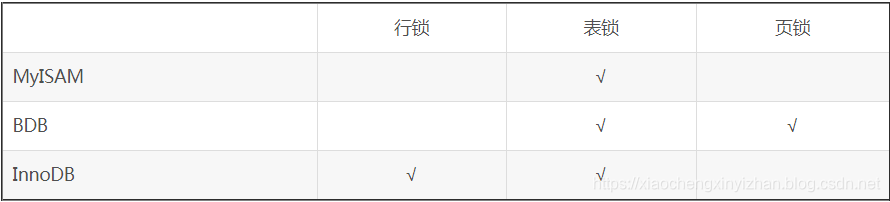
什么情况下会用到表锁,啥时会用到行锁(共享锁S和排他锁X和意向共享锁IS和意向排他锁IX),啥时候会用到页锁?
- 如果更改操作不是在索引上,则为表锁。Innodb行级锁只对Where条件为主键时有效,其他非主键时全都为表锁
- 第一种情况是:事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁来提高该事务的执行速度。
- 第二种情况是:事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定事务涉及的表,从而避免死锁、减少数据库因事务回滚带来的开销。

- 共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE。
- 排他锁(X):SELECT * FROM table_name WHERE … FOR UPDATE。
gap锁是啥?如果一张表有多条记录,被上gap锁,但是这是不可接受的,如何避免或者减小这种锁的影响面?
记录锁是啥?


3.mysql的主从复制了解嘛?
有哪些复制模式?(异步复制和半同步复制)
- 从 MySQL 5.1.12 开始,可以用以下三种模式来实现:
– 基于SQL语句的复制(statement-based replication, SBR),
– 基于行的复制(row-based replication, RBR),
– 混合模式复制(mixed-based replication, MBR)。
相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。 MBR 模式中,SBR 模式是默认的。- MySQL数据库支持单向、双向、链式级联、环状等不同业务场景的复制。在复制过程中,一台服务器充当主服务器(Master),接收来自用户的内容更新,而一个或多个其他的服务器充当从服务器(Slave),接收来自主服务器binlog文件的日志内容,解析出SQL重新更新到从服务器,使得主从服务器数据达到一致。
默认使用的哪种模式(默认为异步模式),它的原理是啥?
- 1)在Slave服务器上执行start slave命令开启主从复制开关,主从复制开始进行。
- 2)此时,Slave服务器的I/O线程会通过在Master上己经授权的复制用户权限请求连接Master服务器,并请求从指定Binlog日志文件的指定位罝(日志文件名和位置就是在配罝主从复制服务时执行change master命令指定的)之后开始发送Binlog日志内容
- 3)Master服务器接收到来自Slave服务器的I/O线程的请求后,其上负责复制的I/O线程会根据Slave服务器的I/O线程请求的信息分批读取指定Binlog日志文件指定位置之后的Binlog日志信息,然后返回给Slave端的I/O线程。返回的信息中除了Binlog日志内容外,还有在Master服务器端记录的新的Binlog文件名称以及在新的Binlog中的下一个 指定更新位置。
- 4)当Slave服务器的I/O线程获取到Master服务器上I/O线程发送的日志内容及日志文件及位置点后,会将Binlog日志内容依次写入到Slave端自身的Relay Log(即中继日志) 文件(MySQL-relay-bin.xxxxxx)的最末端,并将新的Binlog文件名和位置记录到master-info文件中,以便下一次读取Master端新Binlog日志时能够告诉Master服务器需要从新Binlog 日志的指定文件及位置开始请求新的Binlog日志内容。
- 5)Slave服务器端的SQL线程会实时地检测本地Relay Log中I/O线程新增加的日志内容,然后及时地把Relay Log文件中的内容解析成SQL语句,并在自身Slave服务器上按解析SQL语句的位置顺序执行应用这些SQL语句,并记录当前应用中继日志的文件名及位置点在relay-log.info中。
mysql5.8相对前面的版本在主从复制做了哪些改进知道嘛?
- MySQL8.0新增了binlog_transaction_dependency_tracking 参数提升复制性能:
- COMMIT_ORDER:默认设置,默认设置为MySQL5.7的默认机制
- WRITESET:它能够实现更好的并行化,并且主库开始在二进制日志中存储写入writeset信息
- WRITESET_SESSION:设置事物在从库是顺序执行的,这就消除了我们上面说的从库查看数据可能会存在和主库不同的情况。设置为这个值会虽然会降低并行复制的性能,但是相比默认设置来说,性能还是有很大提升的。
binlog是啥,都记录了啥,如何使用?
- Mysql Binlog是二进制格式的日志文件,但是不能把binlog文件等同于OS系统某目录下的具体文件,这是狭隘的。Binlog是用来记录Mysql内部对数据库的改动(只记录对数据的修改操作),主要用于数据库的主从复制以及增量恢复。
如果系统异常,需要对数据进行恢复,如何利用binlog来实现?
实现MySQL主从读写分离的方案- (1)通过程序实现读写分离(性能和效率最佳,推荐)
- (2)通过开源软件实现读写分离MySQL-proxy、Amoda、Mycat、Altas

4.mysql底层数据存储结构是啥?
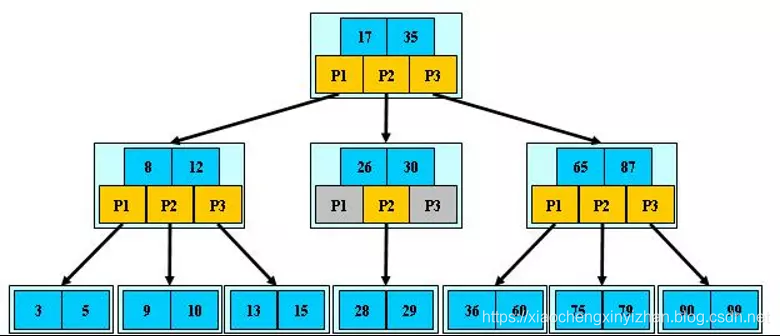
- B-Tree是一种多路搜索树,
B-树的特性- B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;


对于行数据存储有几种格式,默认的格式是啥?
- 默认行格式由innodb_default_row_format定义,其默认值为DYNAMIC。 如果未明确定义ROW_FORMAT表选项或指定了ROW_FORMAT = DEFAULT,则使用默认行格式。
说说这几种格式的主要区别?
- 有效的innodb_default_row_format选项包括DYNAMIC,COMPACT和REDUNDANT。 不支持在系统表空间中使用的COMPRESSED行格式不能定义为默认行格式。 它只能在CREATE TABLE或ALTER TABLE语句中显式指定
- DYNAMIC行格式保持在索引节点中存储整行的效率(如COMPACT和REDUNDANT格式),但DYNAMIC行格式避免了长列用大量数据字节填充B树节点的问题。 DYNAMIC格式基于如下思想:如果长数据值的一部分存储在页外,则通常最有效的是将所有值存储在页外。 使用DYNAMIC格式,较短的列可能保留在B树节点中,从而最小化任何给定行所需的溢出页数。
- COMPRESSED行格式使用类似于页面外存储的DYNAMIC行格式,表和索引数据的其他存储和性能考虑因素被压缩并使用较小的页面大小。 使用COMPRESSED行格式,KEY_BLOCK_SIZE选项控制在聚簇索引中存储多少列数据,以及在溢出页面上放置多少。
- DYNAMIC和COMPRESSED行格式都支持最多3072字节的索引键前缀。 此功能由innodb_large_prefix配置选项控制,该选项默认启用。 有关更多信息,请参阅innodb_large_prefix选项说明。
为啥需要用这种结构?
- InnoDB数据页的结构设计折中了插入,删除以及查找的效率
