想要利用Python来操作word文档可以使用docx模块.
安装: pip install python-docx
1.插入图片
from docx import Document
from docx.shared import Inches
string = '文字内容'
images = '1.jpg' # 保存在本地的图片
doc = Document() # doc对象
doc.add_paragraph(string) # 添加文字
doc.add_picture(images, width=Inches(2)) # 添加图, 设置宽度
doc.save('word文档.docx') # 保存路径
执行结果: 本地生成了一个Word文档, 打开之后.

但是有时添加图片会产生识别异常:
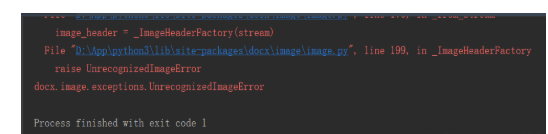
这是因为图片的格式问题, 对比一下 0.jpg 和 1.jpg的二进制数据, 添加0.jpg会异常, 1.jpg则不会.

解决的方法:
图片格式转换
from docx import Document
from docx.shared import Inches
from PIL import Image
string = '文字内容'
images = '0.jpg' # 保存在本地的图片
doc = Document()
doc.add_paragraph(string) # 添加文字
try:
doc.add_picture(images, width=Inches(2)) # 添加图, 设置宽度
except Exception:
jpg_ima = Image.open(images) # 打开图片
jpg_ima.save('0.jpg') # 保存新的图片
doc.add_picture(images, width=Inches(2)) # 添加图, 设置宽度
doc.save('word文档.docx') # 保存路径
结果就和前面一样了
2.插入表格
from docx import Document
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
import pandas as pd
def get_excel_date(filename):
#把第一行带上
dataframe=pd.read_excel(filename,header=None)
result=dataframe.values.tolist()
return result
def insert_table(file_name, excel_name, text):
document = Document()
# 因为docx读出来的都是unicode类型的,所以我们要用unicode类型的进行查找
records = get_excel_date(excel_name)
# 获得excel数据的栏数,初始化一个空的table
row = len(records)+1
col = len(records[0])
table = document.add_table(rows=row, cols=col)
table.style = 'Table Grid'
# 给table加一个表头
shading_elm_1 = parse_xml(r'<w:shd {} w:fill="D9E2F3"/>'.format(nsdecls('w')))
table.rows[0].cells[0]._tc.get_or_add_tcPr().append(shading_elm_1)
table.rows[0].cells[0].text = text
#并且合并第一栏
table_row = table.rows[0]
first = table_row.cells[0]
end = table_row.cells[-1]
first.merge(end)
# 合并结束,开始把excel里的内容添加到table里
for tr_list in range(len(records)):
# row_cells = table.add_row().cells
index = 0
for td_list in records[tr_list]:
table.rows[tr_list+1].cells[index].text = str(td_list)
index = index + 1
# 保存
document.save(file_name)
if __name__=='__main__':
insert_table('D:/111.doc', 'aaa.xlsx', "XXX")