西瓜书第二章学习笔记
其他
2020-02-05 13:32:09
阅读次数: 0
知识脉络
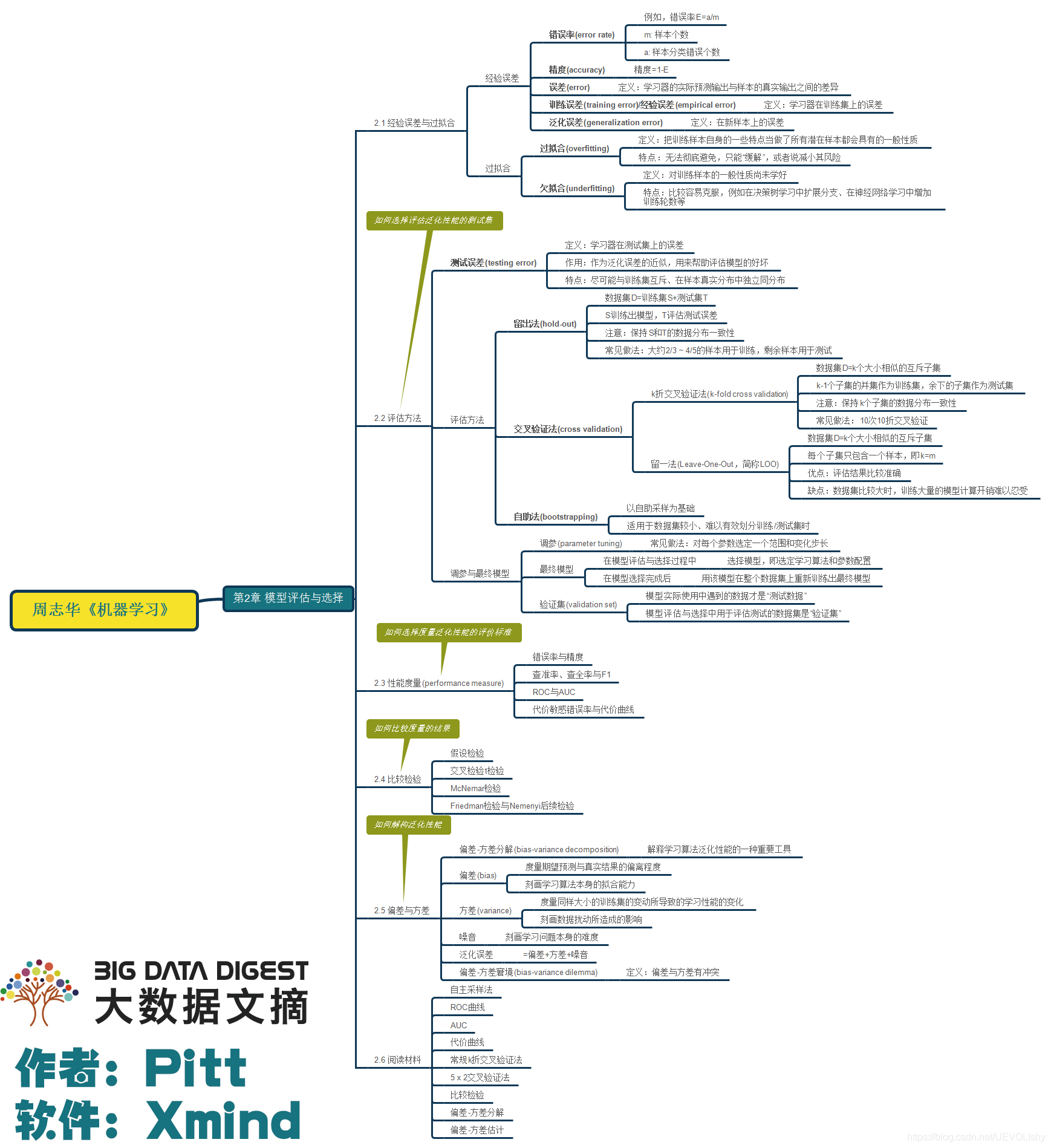
详解与补充
2.2节 评估方法
- 测试样本假设:从样本真实分布独立同分布采样而得。
- 分层采样:保留类别比例的采样方式,来保持样本类别比例类似的划分手段。
- 单次留出法往往不够稳定可靠,需要多次随机划分、重复进行实验评估后取平均值作为结果。
- 一般而言,测试集最少包含30个样例
- 留一法缺点补充:由于“没有免费午餐”,留一法不会永远比其他评估方法准确。留一法无法应用于较大的数据集
- 留出法和、k折交叉验证法缺点:因为训练集比D的规模小,引入了因训练集规模变动而导致的估计偏差。
- 自助法的优缺点:优点:自助法适用于数据集较小的情况;自助法从原始数据集产生多个训练集,很有利于集成学习。缺点:自助法改变了原始数据分布,引入估计偏差。
2.3节 性能度量
- 均方误差:回归任务常用。均等代价假设。计算欧几里得距离作为代价函数。
- 真正例、假正例、真反例、假反例:真正例TP,预测为正例且真实为正例的;假正例FP,预测为正例但真实为反例的;真反例TN,预测为反例且真实为反例的;假反例FN,预测为反例但真实为正例的。机器学习模型的假正例和假反例越少越好。
- 查准率:记号为P,是真正例在所有预测为正例(真正例+假正例)中的比率。
- 查全率:记号为R,是真正例在所有真实为正例(真正例+假反例)中的比率。
- 查准率和查全率是一对矛盾量,在假正例和假反例为一定水平的条件下,增大查准率会减小查全率,增大查全率会减小查准率。
- P-R曲线:将模型对N个样本的预测排序,分别以前n个样本为正例,后(N-n)个样本为反例,查全率R为横轴,查准率P为纵轴,n遍历从1到N,将对应P和R标在坐标系内,连成线。
- P-R曲线作用:用来衡量模型的性能。学习器的P-R曲线下围成面积越大,学习器性能越好。
- 平衡点:它是一种度量。值大小是当“P=R”时的取值。对于两个学习器,若各自P-R曲线围城面积相同,则平衡点较大的性能更优。
- Fβ度量:Fβ是基于查全率和查准率的加权调和平均,1/Fβ = (1/P + 1/R) / (1 + β^2) = (1 + β^2)PR / (β^2*P + R)。适用于类别不均衡问题,能够反映对查全率R和查准率P的不同偏好。β=1时,退化为F1度量;β>1时,更重视查全率;β<1时,更注重查准率。
- 宏查全率、宏查准率、宏F1:对于n个二分类混淆矩阵考察查全率和查准率,先分别求出n个查全率、查准率、F1,然后分别对n个查全率、查准率、F1求平均得到宏查全率、宏查准率、宏F1。
- 微查全率、微查准率、微F1:对于n个二分类混淆矩阵考察查全率和查准率,先分别求出n对真正例、假正例、真反例、假反例的平均值,然后根据平均值求查全率、查准率、F1得到微查全率、微查准率、微F1。
- ROC曲线和AUC:全称“受试者工作特征”曲线,反映测试集总体期望代价(均等代价假设)。将模型对测试集N个样本的预测排序,分别以前n个样本为正例,后(N-n)个样本为反例,假正例率FPR为横轴,真正例率TPR为纵轴,n遍历从1到N,将对应假正例率FPR和真正例率TPR标在坐标系内,连成线。最理想的模型是所有正例都排在反例之前,反映在ROC曲线上就是曲线在纵轴起始点是(0, 1)。使用ROC曲线来对比不同学习器性能就是ROC曲线下面积越大(即AUC)的学习器性能越好。AUC是ROC曲线下的面积,表征任取一对正例和反例时正例预测值大于反例的概率。
- 真正例率TPR:真正例在真实正例中的比例,等同于查全率,越大越好。TPR不关心错判为正的样例。
- 假正例率FPR:假正例在真实正例中的比例。越小越好。
- 非均等代价:对不同类型错误赋予不同权重损失所计算出来的代价。
- 代价敏感错误率:不同错误类型个数乘以对应代价,求总和后除以总样本数m。综合表现了分类器性能以及度量的偏好。
- 正概率代价:记p为样例为正的概率,则正概率代价P+cost等于正例概率p与假反代价的积除以代价总和(假正代价+假反代价)。以正例概率p作为自变量,是分类阈值变动的量化。考虑假正代价和假反代价的比值,与具体值无关。
- 归一化代价:见书上公式2.25。
- 代价曲线:以正概率代价做横轴,归一化代价为纵轴。以样例为正概率p为自变量,取ROC曲线上每一点计算FPR和FNR(FNR=1-TPR)绘制线段,所有线段的公共下界就是代价曲线,所围成的面积就是总体期望代价。总体期望代价反映了学习器在所有条件下的总代期望,越小分类性能越好。当p=0时,假正率为0,代价总体期望最小为0,不关心假反率,因为没正例。当p=1时,总体期望代价最小为0,不关心假正率,因为没有反例。
2.4节 比较检验
- 假设检验:对某个未知参数做出假设,这个未知参数通常是总体样本集的某个参数,但是我们没办法获得(比如一批灯泡的平均使用寿命)。给出显著度α,在假设的前提下,求出满足显著度和假设的置信区间,然后对比被假设参数是否在置信区间内:在,接受假设;不在。拒绝假设。
- 假设检验假设:假定测试样本是从样本总体分布中独立采样而得。
- 对泛化错误率使用假设检验:第一步:假设泛化错误率ε<=ε0,给出显著度α。第二步:求出在满足泛化错误率ε=ε0、显著度为α的条件下最大临界错误率ε_hate。第三步:判断实际测试错误率和临界错误率ε_hate关系,来看是否接受假设。
- 二项检验:适用单个学习器单次检验。假定测试样本是从样本总体分布中独立采样而得。采用假设为ε=ε0。变量二项分布。
- t检验:适用单个学习器多次重复的检验。假定测试样本是从样本总体分布中独立采样而得。采用假设为ε=ε0。变量t分布。
- k折交叉验证成对t检验:适用两个学习器性能对比检验。是t检验在k折交叉验证上的应用。假定测试样本是从样本总体分布中独立采样而得。采用假设为各学习器性能相同。变量t分布。
- 5x2交叉验证:独立采样假设不成立。做5次2折交叉验证,是k折交叉验证的变形。采用假设为各学习器性能相同。变量t分布。
- McNemar检验:适用比较两个二分类学习器的性能。采用假设为各学习器性能相同。变量χ2分布。
- Friedman检验:适用多个学习器性能检验。采用假设为各学习器性能相同。当假设被拒绝时,采用后续检验进一步区分各个算法性能,比如Nemenyi后续检验。变量F分布
- Nemenyi后续检验:适用比较多个算法性能,配合Friedman检验来进一步区分不同算法性能。采用假设为各个学习器性能相同。变量Tukey分布。
发布了39 篇原创文章 ·
获赞 22 ·
访问量 1万+
转载自blog.csdn.net/UEVOLIshy/article/details/92997940
