records 库由大名鼎鼎的 Kenneth Reitz 开发,他也是 python requsts 库的作者。records 库的口号是 SQL for the human。开发人员基本只需要关注 SQL 语句。
连接数据库
records 库基于 sqlalchemy 实现,所以连接字符串相同。比如我想基于 pymysql 连接到 mysql 数据库,则用下面的语句建立连接:
import records
db = records.Database("mysql+pymysql://root:pwd@localhost/stonetest?charset=utf8")
查询数据
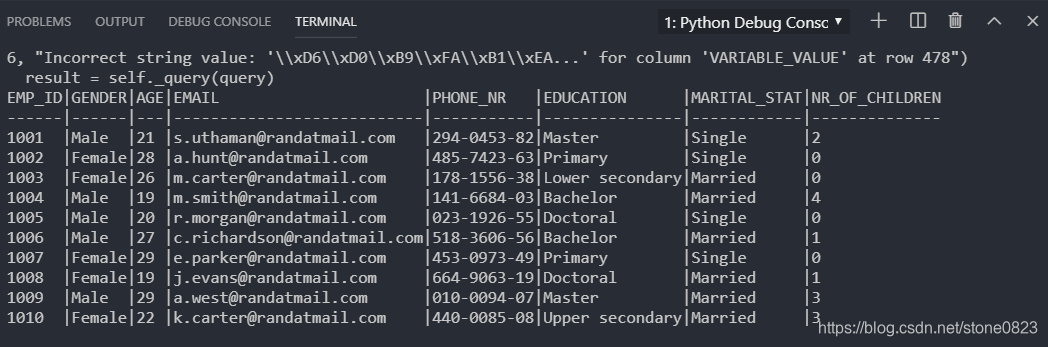
连接到数据库以后,假如我需要查询 emp_master 表的数据:
rows = db.query("SELECT * FROM emp_master LIMIT 0, 10")
print (rows.dataset)
rows.dataset 输出类似于命令窗口的数据显示:
查询参数
records 使用 dict 提供参数,SQL 语句支持 :variable_name 语法,增加了 SQL 语句的可读性,也避免了 SQL 注入等问题。
emp = {
'gender': 'Female',
'maritalstat': 'Single'
}
rows = db.query(
"SELECT * FROM emp_master WHERE GENDER=:gender AND MARITAL_STAT=:maritalstat",
**emp)
print(rows.dataset)
输出结果如下:

查询结果输出
刚才介绍了 RecordCollection.dataset 输出格式化的数据。除此之外,records 还提供了很多输出的方式。
RecordCollection.all() 方法将所有行输出为一个列表,每一行为 Record 类型的实例,示例如下。
rows = db.query("SELECT * FROM emp_master LIMIT 0, 3")
print (rows.all())
输出:
[<Record {"EMP_ID": 1001, "GENDER": "Male", "AGE": 21, "EMAIL": "[email protected]",
"PHONE_NR": "294-0453-82", "EDUCATION": "Master", "MARITAL_STAT": "Single", "NR_OF_CHILDREN": 2}>,
<Record {"EMP_ID": 1002, "GENDER": "Female", "AGE": 28, "EMAIL": "[email protected]",
"PHONE_NR": "485-7423-63", "EDUCATION": "Primary", "MARITAL_STAT": "Single", "NR_OF_CHILDREN": 0}>,
<Record {"EMP_ID": 1003, "GENDER": "Female", "AGE": 26, "EMAIL": "[email protected]",
"PHONE_NR": "178-1556-38", "EDUCATION": "Lower secondary", "MARITAL_STAT": "Married",
"NR_OF_CHILDREN": 0}>]
也可以使用遍历的方法来输出:
rows = db.query("SELECT * FROM emp_master LIMIT 0, 3")
for row in rows:
print(row.EMP_ID, row.GENDER, row.EMAIL, sep='\t')
输出结果为:
1001 Male [email protected]
1002 Female [email protected]
1003 Female [email protected]
在 all() 方法中,可传入 as_dict 参数直接输出 dict 格式:
rows = db.query("SELECT * FROM emp_master LIMIT 0, 3")
print(rows.all(as_dict=True))
输出结果为:

因为 dict 的 key 是无顺序的,如果在意字段的顺序,传入参数 as_ordereddict:
rows = db.query("SELECT * FROM emp_master LIMIT 0, 3")
print(rows.all(as_ordereddict=True))
输出结果为:

动作查询
records 认为,SQL 语句本身决定了是查询 (SELECT)、还是数据操作 (UPDATE, INSERT, DELETE)、还是 DDL (CREAT TABLE 等),所以执行 SQL 语句只需要 query 方法就可以了。比如,要创建 usertest 表,仍然使用 query 方法:
sql = """
create table usertest (
userid int primary key,
username varchar(50)
);
"""
db.query(sql)
新增单条记录也是使用 query 方法:
user = {
'userid': 1,
'username': 'Bruce'
}
db.query(
"INSERT INTO usertest (userid, username) values (:userid, :username)",
**user)
新增批量记录,可以使用 bulk_query 方法,一次执行多条语句:
users = [
{'userid': 2, 'username': 'Tom'},
{'userid': 3, 'username': 'Alex'},
{'userid': 4, 'username': 'George'}
]
db.bulk_query(
"INSERT INTO usertest (userid, username) values (:userid, :username)",
users)
records 对事务的支持
records 支持事务。示例如下:
conn = db.get_connection()
tx = conn.transaction()
try:
conn.query("INSERT INTO usertest(userid, username) values(5, 'Peggi')")
conn.query("INSERT INTO usertest(userid, username) values(4, 'Alice')")
tx.commit()
except Exception as ex:
print ("*" * 10, "Error Occured", "*" * 10)
print (str(ex))
tx.rollback()
finally:
conn.close()
因为 userid 为 4 的记录在数据表中已经存在,所以出现错误,两条记录都不会被创建。
********** Error Occured **********
(pymysql.err.IntegrityError) (1062, "Duplicate entry '4' for key 'PRIMARY'")
[SQL: INSERT INTO usertest(userid, username) values(4, 'Alice')]
(Background on this error at: http://sqlalche.me/e/gkpj)
查询结果导出
records 库的输出和导出都是利用 tablib 库的功能,能方便地导出到 json, CSV ,Excel 和 HTML 等不同格式,也是方便得不像话。
导出为 json
rows = db.query("SELECT * FROM emp_master")
with open('D:/test.json', 'w') as f:
f.write(rows.export('json'))
导出为 Excel
rows = db.query("SELECT * FROM emp_master")
with open('D:/test.xlsx', 'wb') as f:
f.write(rows.export('xlsx'))
