原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12245002.html
Basic Indexing and Slicing
One-dimensional arrays are simple; on the surface they act similarly to Python lists:

Note: As you can see, if you assign a scalar value to a slice, as in arr[5:8] = 12, the value is propagated (or broadcasted henceforth) to the entire selection. An important first distinction from Python’s built-in lists is that array slices are views on the original array. This means that the data is not copied, and any modifications to the view will be reflected in the source array. As NumPy has been designed to be able to work with very large arrays, you could imagine performance and memory problems if NumPy insisted on always copying data.
The “bare” slice [:] will assign to all values in an array:

If you want a copy of a slice of an ndarray instead of a view, you will need to explicitly copy the array—for example, arr[5:8].copy().

In a two-dimensional array, the elements at each index are no longer scalars but rather one-dimensional arrays. Thus, individual elements can be accessed recursively. But that is a bit too much work, so you can pass a comma-separated list of indices to select individual elements.
Indexing elements in a NumPy array
axis 0 is the “rows” of the array and axis 1 is the “columns” of the array.
In multidimensional arrays, if you omit later indices, the returned object will be a lower dimensional ndarray consisting of all the data along the higher dimensions. So in the 2 × 2 × 3 array arr3d:
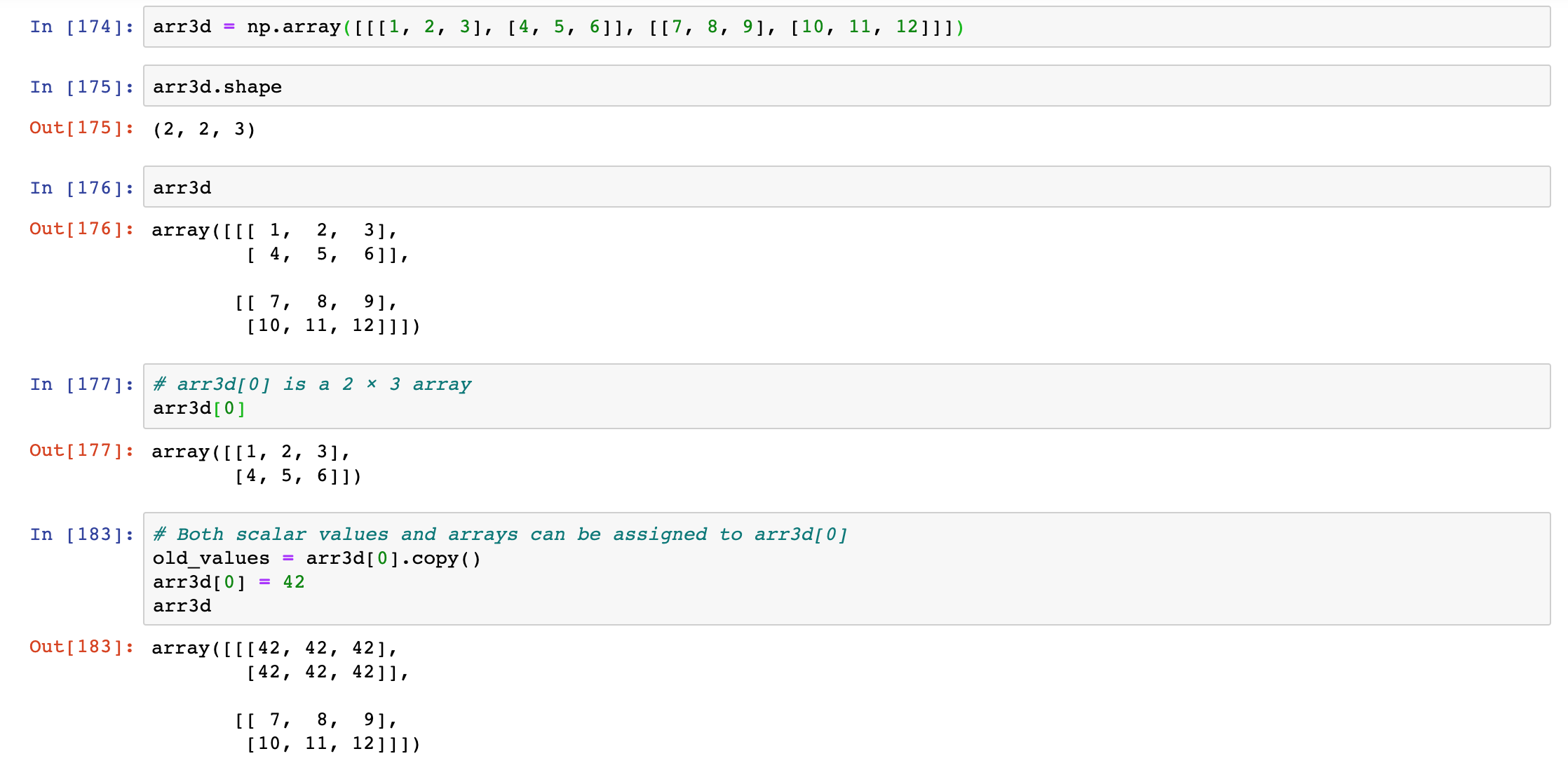
Similarly, arr3d[1, 1] gives you all of the values whose indices start with (1, 1), forming a 1-dimensional array:

Reference
Python for Data Analysis Second Edition