一、安装条件前置
实验zookeeper安装在【单机hadoop】机器上,已完成安装jdk,hadoop和ssh配置环境等。
zookeeper所依赖的虚拟机和操作系统配置
环境:ubuntu14 + apache-zookeeper-3.5.6-bin.tar + jdk1.8+ssh
虚拟机:(vmware10)
二、zookeeper安装环境设置
(1)下载


(2)上传到linux系统解压
扫描二维码关注公众号,回复:
8951466 查看本文章

tar xvf apache-zookeeper-3.5.6-bin.tar.gz
#放在统一的软件目录下
mv apache-zookeeper-3.5.6-bin ~/software/(3) 新建数据目录
cd ~/software/apache-zookeeper-3.5.6-bin
#zk的数据目录
mkdir -p zkData/data
#zk的日子目录
mkdir -p zkData/logs(4)配置zoo.cfg
cd ~/software/apache-zookeeper-3.5.6-bin/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg编辑zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 注释掉默认dataDir
# dataDir=/tmp/zookeeper
#
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#新增的配置,server.i的i是数据目录zkData/data下的myid
dataDir=/home/mk/software/apache-zookeeper-3.5.6-bin/zkData/data
dataLogDir=/home/mk/software/apache-zookeeper-3.5.6-bin/zkData/logs
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
(5)复制到hadoop02、hadoop03
scp -r /home/mk/software/apache-zookeeper-3.5.6-bin mk@hadoop02:/home/mk/software/
scp -r /home/mk/software/apache-zookeeper-3.5.6-bin mk@hadoop03:/home/mk/software/(6)配置myid
hadoop01
echo '1' > ~/software/apache-zookeeper-3.5.6-bin/zkData/data/myidhadoop02
echo '2' > ~/software/apache-zookeeper-3.5.6-bin/zkData/data/myidhadoop03
echo '3' > ~/software/apache-zookeeper-3.5.6-bin/zkData/data/myid三、启动Zookeeper
(1)启动
zookeeper没有集群启动需要每个机器各自启动
hadoop01、hadoop02、hadoop03都执行启动指令
~/software/apache-zookeeper-3.5.6-bin/bin/zkServer.sh start

(2)检查启动状态
~/software/apache-zookeeper-3.5.6-bin/bin/zkServer.sh status
hadoop01

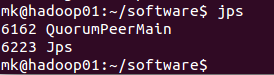
hadoop02

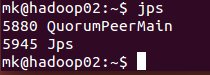
hadoop03


(3)创建节点
haddoop01登录zk
~/software/apache-zookeeper-3.5.6-bin/bin/zkCli.sh
ls /
create /test
ls /
delete /test


hadoop02登录zk
~/software/apache-zookeeper-3.5.6-bin/bin/zkCli.sh
ls /
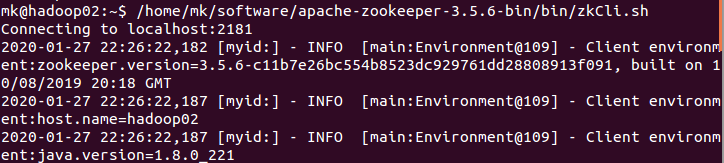

hadoop03登录zk
~/software/apache-zookeeper-3.5.6-bin/bin/zkCli.sh
ls /


(4)关闭
~/software/apache-zookeeper-3.5.6-bin/binzkServer.sh stop



