安装环境:
硬件资源:两个笔记本电脑
系统:centos 7
hadoop版本:hadoop2.7.3
zookeeper版本:3.4.12
hbase版本:2.0.0
截至到我博客发布,hadoop和hbase的版本结合,hadoop最新可以使用hbase的是2.7.*这个版本。
安装hadoop:
jdk安装略过。
ssh安装略过。(注意设置双向免密码登陆)
官方安装文档:
安装成功标志:运行下面命令没有错误
hadoop fs -ls /我的简单配置文件:
1、hadoop-env.sh 添加一行
export JAVA_HOME=/usr/java/jdk1.8.0_1022、core-site.xml添加配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://masterhost:9000/</value>
</property>3、hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/zengqiang/tmp/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/zengqiang/tmp/hadoop/dfs/namesecondary</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/zengqiang/tmp/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.hosts</name>
<value>/opt/hadoop/hadoop-2.7.6/hadoop/etc/hadoop/dfs-hosts</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>4、mapred-site.xml 这个需要从mapred-site.xml.template文件中copy
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>5、yarn-site.xml 添加
<!--
配置resourceManager信息
-->
<property>
<name>yarn.resourcemanager.address</name>
<value>masterhost:8032</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>masterhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>masterhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>masterhost:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>masterhost:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>masterhost:8088</value>
</property>
<!--
配置resourceManager信息结束
-->
<!--
配置nodemanager信息开始
-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/zengqiang/tmp/hadoop/yarn/nodemanager/log/</value>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>2592000</value>
</property>
<!--
配置nodemanager信息结束
-->
<!-- Site specific YARN configuration properties -->6、最后设置主机名称:
sudo vim /etc/hosts
我的设置:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.102 masterhost
192.168.0.100 datahost
7、设置workers(告诉hadoop有那个主机)
vim etc/hadoop/workers
masterhost
datahost
8、设置环境变量sudo vim /etc/profile
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.6/hadoop
export PATH中添加:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
sudo source /etc/profile运行start-all.sh = start-dfs.sh + start-yarn.sh
停止stop-all.sh = stop-dfs.sh + stop-yarn.sh
运行命令jps验证进程
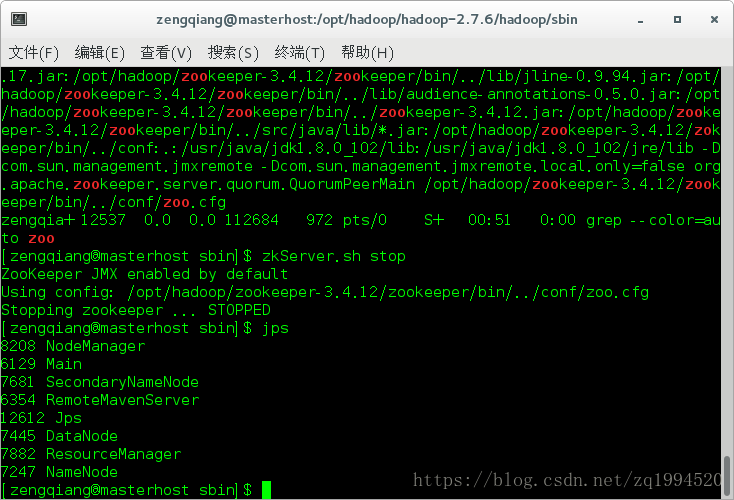
其中dataNode、Resourceanager、Namenode、SecondaryNameNode、NodeManager是主节点jps
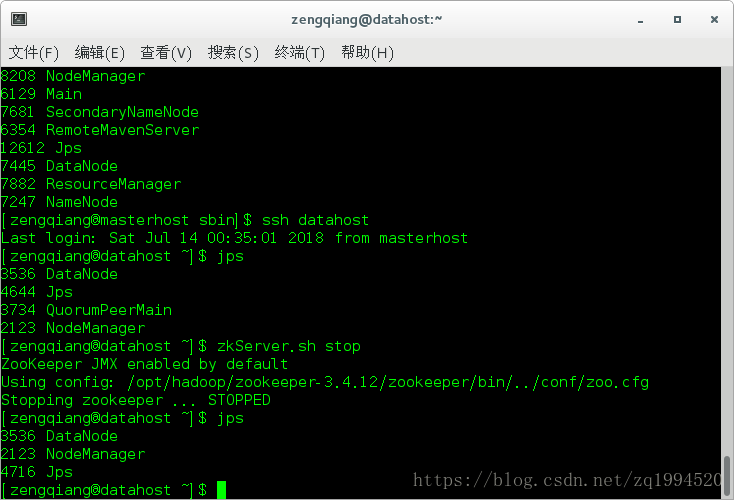
DataNode、NodeManager是数据节点的基础节点
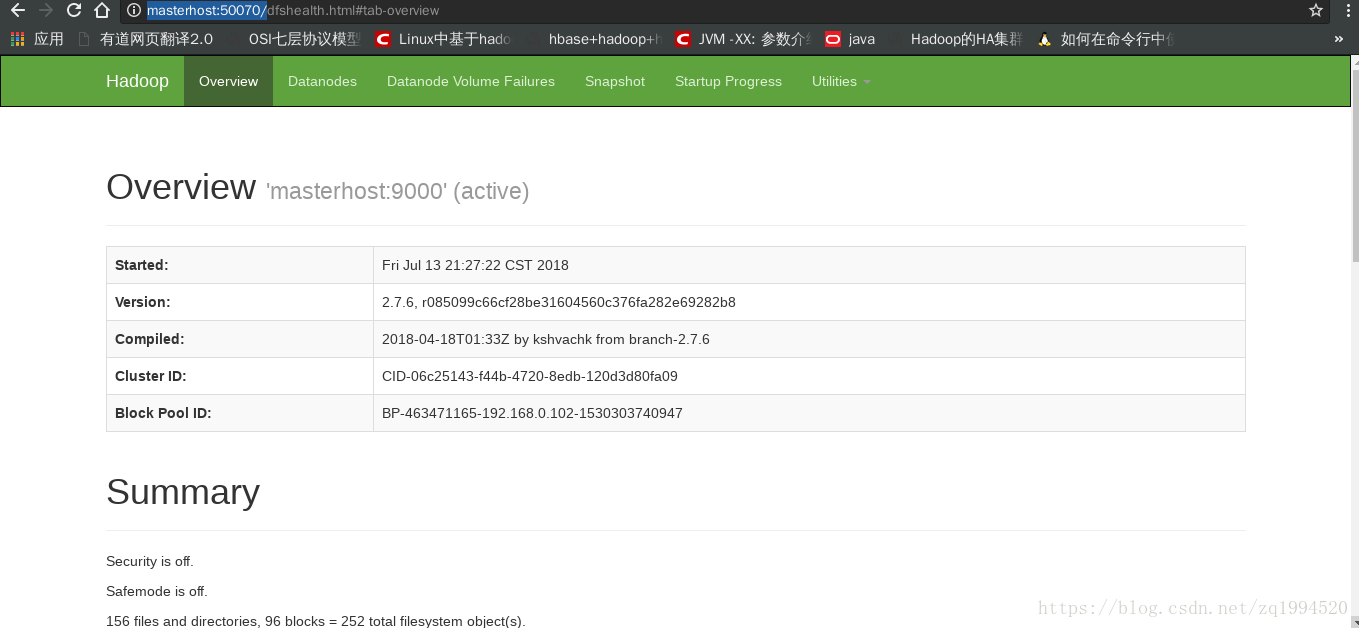
访问地址http://masterhost:50070/
如图:
安装zookeeper:
server.2=datahost:2888:3888
dataDir=/home/zengqiang/tmp/zookeeper/data #按照自己喜好配置路径
# the port at which the clients will connect
clientPort=2181
dataLogDir=/home/zengqiang/tmp/zookeeper/log #按照自己喜好配置路径
2、在配置的dataDir路径里面新建myid(每个服务的内容不一样)
我的masterhost 1
datahost 2
注意后面不要有空格或者其他空白字符。
3、添加环境变量:
export ZOOKEEPER_HOME=/opt/hadoop/zookeeper-3.4.12/zookeeper
export PATH中添加 :$ZOOKEEPER_HOME/bin
使用sudo source /etc/profile
运行:
zkServer.sh start
停止:
zkServer.sh stop
运行命令:jps
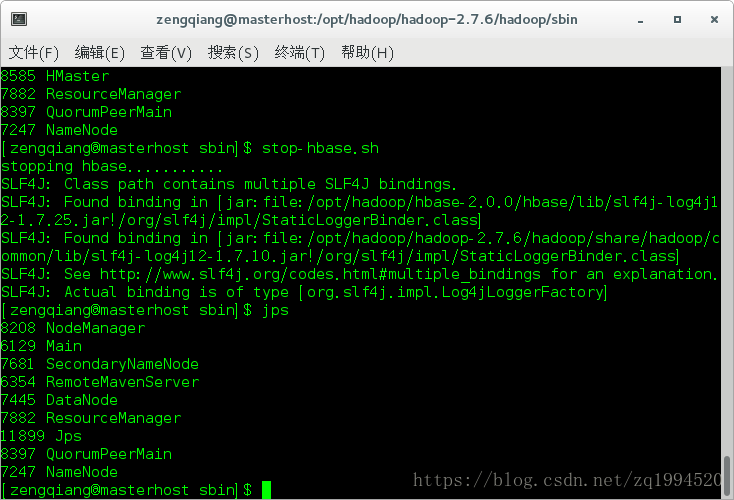
QuoumPeerMain是该服务名称
安装hbase:
1、hbase-site.xml添加
<property>
<name>hbase.rootdir</name>
<value>hdfs://masterhost:9000/user/zengqiang/hbase</value>
<!-- hadoop的hdfs访问地址,其中/user/zengqiang/hbase这个路径是通过hadoop fs -mk hbase 这个命令创建的 -->
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zengqiang/tmp/hbase/zookeeperData</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/zengqiang/tmp/hbase/tmpData</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name><property>
<name>hbase.rootdir</name>
<value>hdfs://masterhost:9000/user/zengqiang/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zengqiang/tmp/hbase/zookeeperData</value> <!-- zookeeper的数据路径,一般和原来的配置相同 -- >
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/zengqiang/tmp/hbase/tmpData</value><!-- hbase的数据保存路径,可以自己设置 -->
</property>
<property>
<name>hbase.zookeeper.quorum</name><value>masterhost,datahost</value> <!-- zookeeper相关的服务器地址 -->
</property>2、根据配置文件创建文件夹
我的有
/home/zengqiang/tmp/hbase/tmpData3、添加环境变量
export HBASE_HOME=/opt/hadoop/hbase-2.0.0/hbaseexport PATH中添加 :$HBASE_HOME/bin
最后source /etc/profile
运行 start-hbase.sh
停止 stop-hbase.sh
运行jps命令:
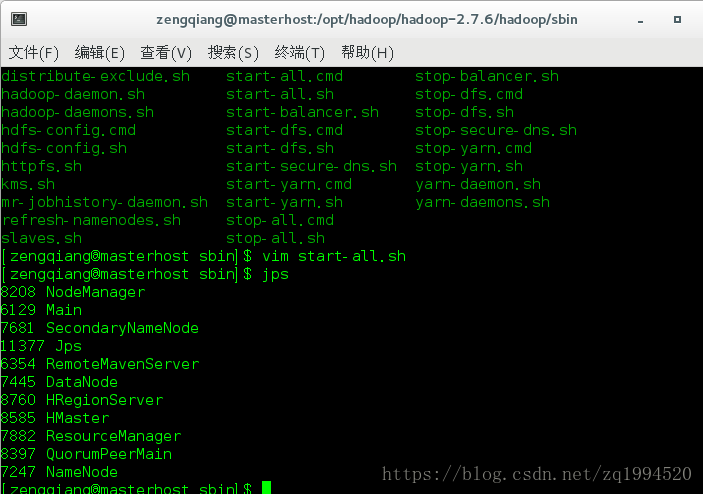
HRegionServer是该服务名
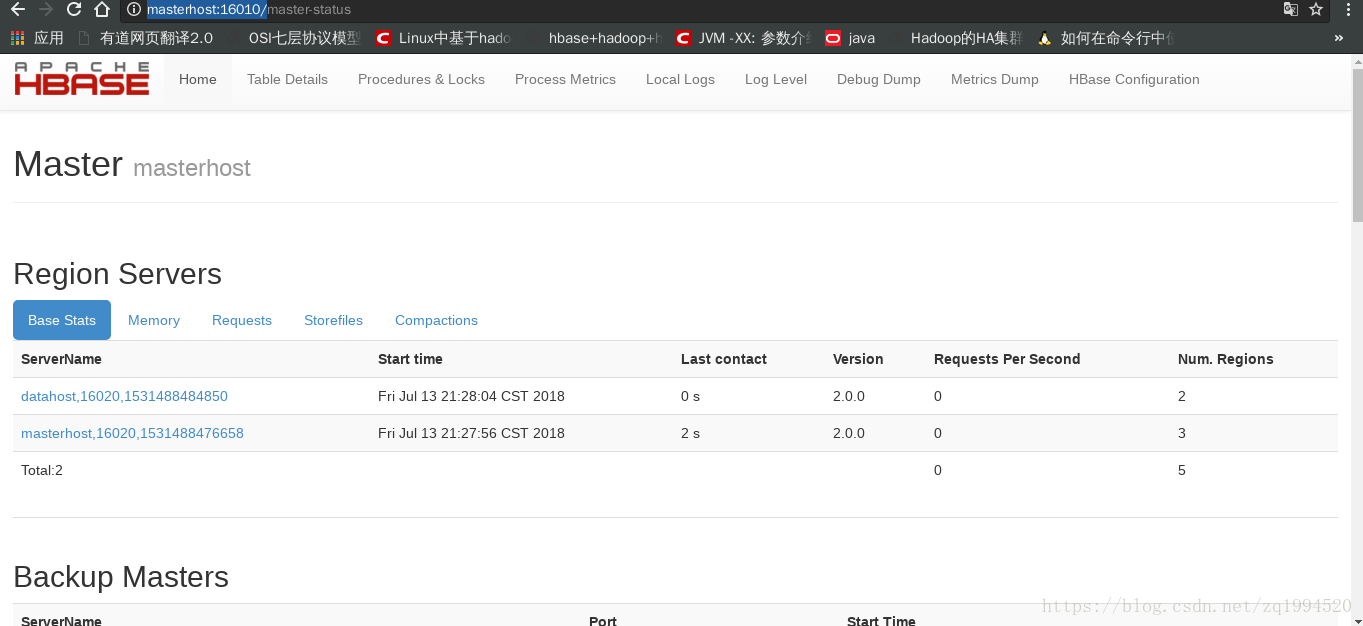
访问地址:http://masterhost:16010/