目前很多使用scrapy框架的程序员将数据保存在MongoDB、MySql数据库,但是很少又将数据保存到SqlServer数据。
但是难免会有企业是使用的sqlserver数据库保存数据,接下来我们就将scrapy爬虫获取的数据保存到sqlserver数据库可能会遇到的一些问题呵方法整理一下。
能看到这篇文章的人,我想scrapy的基本使用已经没什么问题了,我们就只说pipelines这个模块的保存方法。
既然是使用sqlserver数据库,自然需要先安装完成,我使用的是sqlserver2012,微软官网就能直接下载。(假设你已经安装完成)
在实际爬虫项目的环境中,如果是将数据保存到本地的数据库,安装pymssql模块,命令pip install pymssql。

没装的装好再继续,我这边已经安装完成。
接下来,我们在pipelines.py模块中写一个保存数据的类
class MsSqlPipelineX(object):
def __init__(self):
self.conn = pymssql.connect(host='localhost',user='sa',password='******',database='Find')
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
try:
# sql = 'INSERT INTO dbo.find(user_name,user_url) VALUES (%s,%s)'
self.cursor.execute("INSERT INTO dbo.find(user_name,user_url) VALUES (%s,%s)",(item['user_name'],item['user_url']))
self.conn.commit()
except Exception as ex:
print(ex)
return item
你可以提前在数据库中建好表和字段
host指明数据库是本地
user指明当前的用户名
password指明密码
database指明要存入的数据库,
不用指明端口
如果代码出现黄色警报,
self.cursor.execute("INSERT INTO dbo.find(user_name,user_url) VALUES (%s,%s)",(item['user_name'],item['user_url']))
表示当前编译器中没有指明数据库,也可认为没有正确连接到数据库。

以下是解决办法:
点击编译器的Database
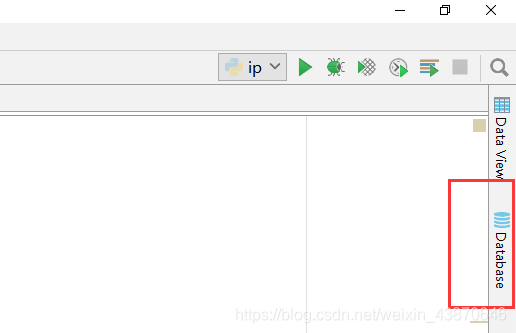
导入数据库
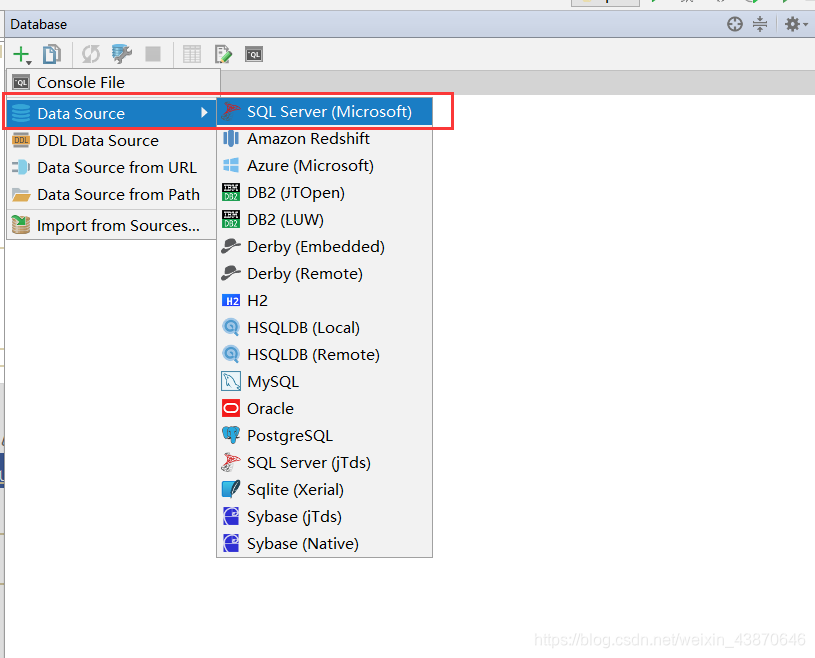
填写红色框中的信息,
Database为sqlserver中建立好的数据库名
取消 use.*?的钩
使用用户名/密码登录数据库
点击ok保存

就是这个样子

报红,没关系,我们现在看看数据是否能保存入数据库。
运行代码,数据正常开始获取。
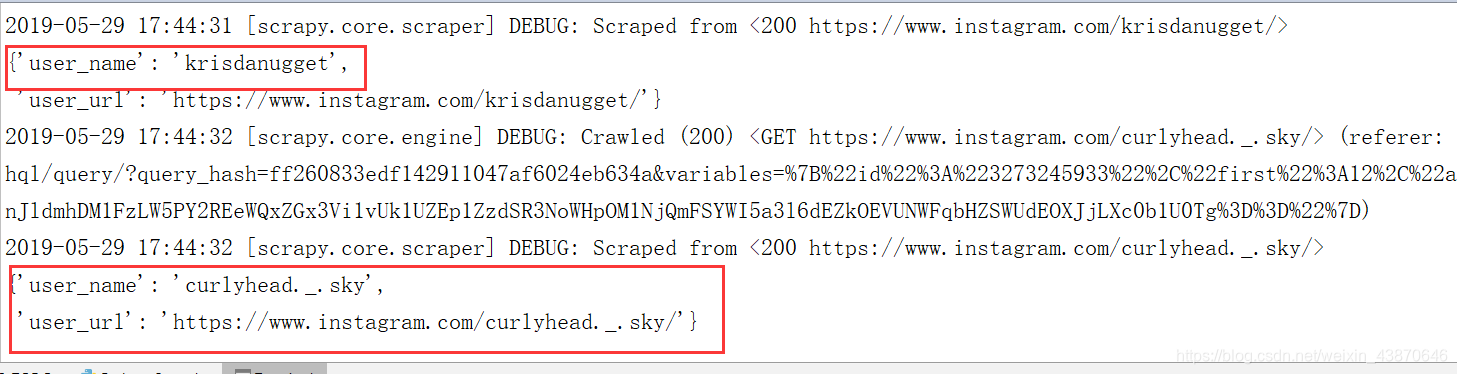
查看数据库的信息

可以看到数据已经存到数据库中,说明成功了。
以上,加油吧
