信息熵(Entropy):解决信息的度量问题
一条信息的信息量与其不确定性有直接的关系,如果对一件事情了解的很多,那么信息少一些,也能知晓事情本身;反之,如果对事情没有一点了解,那么则需要大量信息来对事情进行知晓。因此,信息量就等于不确定性的多少。
香农利用“比特(Bit)”来度量信息量,一个bit是一位二进制数,1字节=8bit。信息量的比特数与所有可能情况的对数函数log有关。
信息熵的定义如下:
由于熵的单位是二进制位(bit),所以是以log2为底,以下都是以log2为底。约定0log0=0
变量的不确定越大,熵也就越大,信息量也就越大。在热力学中,熵变是指体系混乱程度的变化,熵是衡量系统无序的度量。因此在信息论中利用"熵"这个词来表示。
我们知道的信息越多,随机事件的不确定性越小,不仅仅是直接相关信息(X)与事件有直接关系,一些相关信息(Y)也能够帮助我们去了解事件,增加确定性。因此,引入了“条件熵”(Conditional Entropy)。
定义在Y的条件下的条件熵为:
证明:H(X) >= H(X|Y) ----->>>>熵越大不确定性越大,加入Y后不确定性减小。当Y信息是与X毫无关系的信息时,等号成立。(后补)
在上面提到了,Y是与X相关的信息,才会对X的熵产生影响。那么如何衡量,两者的相关性大小?
香农提出利用“互信息(Mutual Information)”来度量X与Y相关性的大小:
互信息定义如下:
可以证明:
也就是说两个事件相关性的度量,就是在了解Y的情况下, 对于消除X不确定性所提供的信息量。
信息量被广泛用于度量一些语言现象的相关性。比如机器翻译领域需要解决单词的二义性问题:Bush(布什or灌木)。在这个里面,可以利用互信息解决了这个问题。找出与布什互信息较大的词语,与灌木互信息较大的词语。然后等 Bush出现后,查看其上下文中哪类次出现频率高,那么基本可以断定这里的Bush为哪个含义。
相对熵(Relative Entropy),也被称为Kullback-Leibler散度,是用来衡量两个取值为正数的函数的相关性。
定义如下:
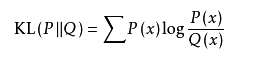
关于相对熵的三条结论:
(1)对于两个完全相同的函数,他们的相对熵等于0,KL(P||Q)>=0。
(2)相对熵越大,两个函数差异越大,反则亦然
(3)对于概率分布或者概率密度函数,如果取值均大于0,相对熵可以度量两个随机分布的差异性。
相对熵是不对称的,即:
为了解决这个问题,提出了一种新的相对熵的计算方法如下:
相对熵有很多应用,衡量连个常用词在不同文本的概率分布中,是否为同义词。贾里尼克从条件熵和相对熵的角度出发,定义了一个新的语言模型复杂度,用来衡量语言模型的好坏。
参考文献:
[1]吴军-数学之美(第二版)第六章
