本周任务:
一、python基础的准备
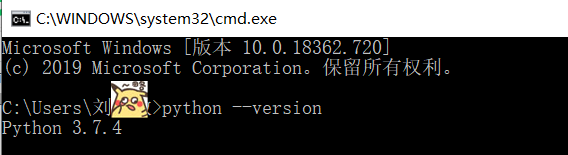
1)安装好Python开发环境, PyCharm 或 Anaconda等都可以,按个人习惯喜好。
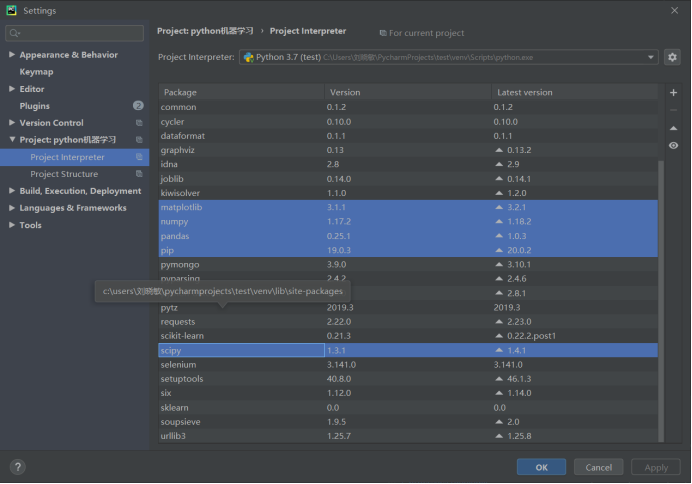
2)基本库的安装,如numpy、pandas、scipy、matplotlib
二、本周视频学习内容:https://www.bilibili.com/video/BV1Tb411H7uC?p=1
1)P4 Python基础
2)P1 机器学习概论
概念:机器学习是AI的一个分支,设计一个计算机系统,根据提供的数据按一定方式学习,随着训练次数增加,可以在性能上不断学习和改进,通过参数优化学习模型。
分类:机器学习包括有监督学习,无监督学习和增强学习(9’38)
有监督学习——通过已有数据对(x,y)判断新数据(x)的y值。
·例子:儿童经过多次训练学到月亮这个概念,之后能够判断某事物是否为月亮。
无监督学习——判断不完全独立的数据之间的关系,p(x)p(y)≠p(xy)。(聚类)
·例子:词库经过训练组合得到新词,根据词语组合的概率得到新词。
作用:1)清洗数据/特征选择;2)确定算法模型/参数优化;3)结果预测 (21’00)
【×】大数据存储/并行计算/机器人
【区别】做某些规则时采用传统算法;运用某些规则则是机器学习。
多元线性回归模型:构建一个根据多个影响因素预测到的值无限接近实际值的模型。
无限迭代使得损失函数(目标函数)最低,模型达到最优。
机器学习的一般流程:数据收集→数据清洗→特征工程(特征选择、调参)→数据建模→预测(37’39)
【注】清洗和特征工程实际工作量较大
机器学习方法:
1)利用各种算法对数据进行分类
Linear SVM / RBF SVM / Decision Tree / Naive Bayes / Linear Discrimination / QDA / AdaBoast / Random Forest等
2)采用不同的可延展的配置文件训练模型
3)适当调整损失函数使预测数据达到最优
4)设计模型的大小适应不同设备
泰勒公式——预测ex的值 / 考察Gini系数的图像(梯度下降法)
Γ函数
凸函数
Soft-max 回归
古典概型——生日悖论 / 装箱问题 → 熵(混乱程度的反映——决策树、随机森林)
3.作业要求:
1)贴上Python环境及pip list截图,了解一下大家的准备情况。暂不具备开发条件的请说明原因及打算。
2)贴上视频学习笔记,要求真实,不要抄袭,可以手写拍照。
3)什么是机器学习,有哪些分类?结合案例,写出你的理解。




二维数组直接采用Unique去重会先将二维数组变成一维数组再进行去重,不符合需求。故方法一:转换为虚数再进行去重。

方法二:将二维数组转化为元组再放入集合中
![]()
堆叠np.stack(),根据axis不同堆叠效果不同。
矩阵乘法![]()
对应元素相乘![]()