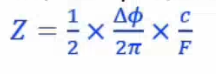【慕课笔记】3D感知技术与实践(一)概述
(一)3D数据处理神经网络:
1.1 基于3D图像的多视角投影:
从3D点云生成特定视角的深度图,使用和2D图像识别相同的卷积神经网络结构实现手势识别;
论文地址(回头再看):《Robust 3D Hand Pose Estimation in Single Depth Images: From Single-View CNN to Multi-View CNNs》

1.2 直接利用任意排序次序的点云:
核心运算是神经网络的全连接层,对应矩阵乘法;
论文地址:《PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation》

(二)从2D图像到3D数据:
2.1 3D数据的优势:
- 低功耗、低运算量;

- 信息量大,环境感知丰富;

- 带有距离和尺寸信息;

- 不受光照条件干扰;

2.2 3D数据面临的难点:
- 噪声和干扰;
- 畸变(桶形畸变和枕形畸变);
- 分辨率第;
- 运动模糊;

(三)3D数据处理的总流程:

(四)3D数据获取——双目匹配3D成像原理:
4.1 双目匹配3D成像的基本概念:
双目立体视觉是基于视差原理,由多幅图像获取物体三维几何信息的方法;
在机器视觉系统中,双目视觉一般由双摄像机从不同角度同时获取周围景物的两幅数字图像,或有由单摄像机在不同时刻从不同角度获取周围景物的两幅数字图像,并基于视差原理即可恢复出物体三维几何信息,重建周围景物的三维形状与位置;
4.2 双目匹配3D成像的数学原理:

从人眼的感觉来理解,左眼看到的物体(如这个叶子)偏右,右眼看到的物体偏左;
并且总体来说,越近的物体在两眼中出现的位置的偏移量就越大;距离越远,偏移量越小;
因此我们可以通过这样的反比关系,计算物体的距离:

这样我们只需要对左右两个相机拍摄到的图片的每一个像素的位置进行匹配,就可以计算出该像素点的深度,从而从2D图片中就可以得到3D数据;

(五)3D数据获取——结构光3D成像原理:
5.1 双目匹配3D成像的缺点:
- 需要对复杂背景下的图像进行匹配;
- 不能识别没有纹理的物体;
5.2 结构光3D成像的数学原理:

5.2.1 点结构光3D成像:
 这里点光源发射出一束光,在物体上反射,最后照射到相机中;
这里点光源发射出一束光,在物体上反射,最后照射到相机中;
假设相机和光源的距离
和两个角
和
已知,则有:
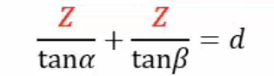
可解得物体上该点的距离
为:
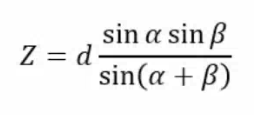
5.2.2 线结构光3D成像:

如果我们将点光源拓展为线光源,那么相机检测到的反射光就是空间中的一条曲线,曲线的弯曲状况就代表了物体表面的高低程度;
列出空间曲线方程为:

可解得物体在坐标
的距离
为:
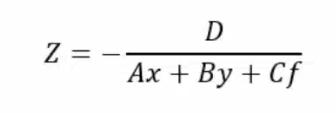
(六)3D数据获取——光编码成像原理:

6.1 光编码成像的基本概念:

这里将结构光成像拓展成面光源,即通过投影仪投影整个结构光的图案编码到物体表面;
这时相机可以通过识别不同部位的纹理,识别物体上某点对应投影仪发射光的角度和相机接受的入射角度,利用这两个角度就可以计算出照射到某个地方的纹理的距离是多少;
6.2 光编码成像的双目立体视觉:

即利用投影的光编码图案,帮助双目摄像头进行匹配;
(七)3D数据获取——TOF 3D成像原理:

7.1 TOF 3D成像的基本概念:
我们经常看到的激光测距仪就是利用这个原理制成的;

其中光源发出一束受高频调制的光(如100M 的光,波长为3m),经过反射到达摄像头会产生一定的相位差,测出每个像素点相位差的大小,就可以计算出物体表面的距离: