0 写在前面
分享最近在BEV感知方面的工作,欢迎自动驾驶同行交流学习,助力自动驾驶早日落地。
1.概述
对于自动驾驶而言,BEV(鸟瞰图)下的目标检测是一项十分重要的任务。尽管这项任务已经吸引了大量的研究投入,但灵活处理自动驾驶车辆上安装的任意相机配置(单个或多个摄像头),仍旧是一个不小的挑战。
为此提出BEVFormer,利用了Transformer强大的特征提取能力以及Timestamp结构的时序特征的查询映射能力,在时间维度和空间维度对两个模态的特征信息进行聚合,增强整体感知系统的检测效果。
论文连接:https://arxiv.org/pdf/2203.17270v1.pdf
代码链接:GitHub - zhiqi-li/BEVFormer
关于BEVFormer
BEVFormer通过预定义的网格状BEV查询,将时间和空间进行交互,从而挖掘空间和时间信息。为了聚合空间信息,我们设计了一个空间交叉注意( spatial cross-attention),每个BEV查询都从摄像机视图的感兴趣区域提取空间特征。对于时间信息,我们提出了一种时间自我注意( temporal self-attentio),以反复融合历史BEV信息。在nuScenes数据集上,NDS评估值指标达到了SOTA : 56.9%,比之前基于激光雷达的SOTA方法性能高9个点。我们进一步表明,BEVFormer显著提高了低能见度条件下目标速度估计和调用的精度。
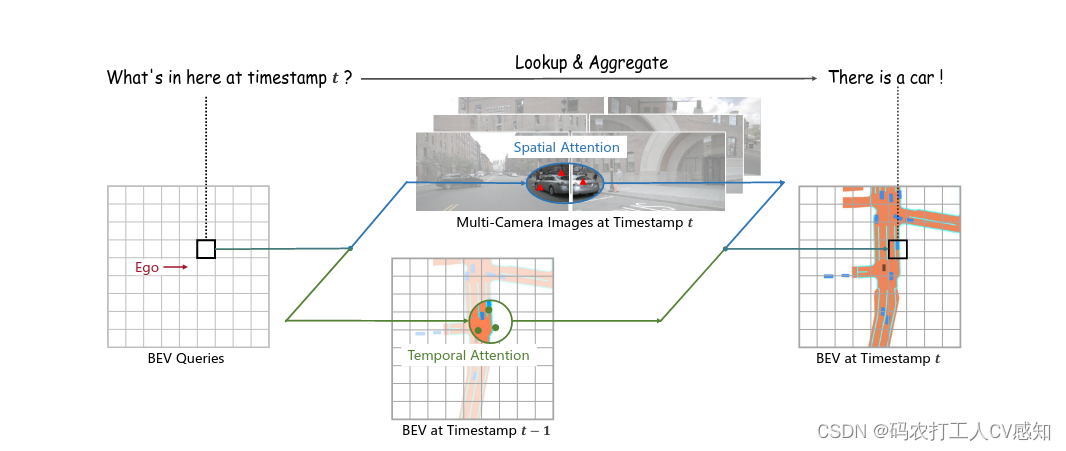
图1
2.结构框架
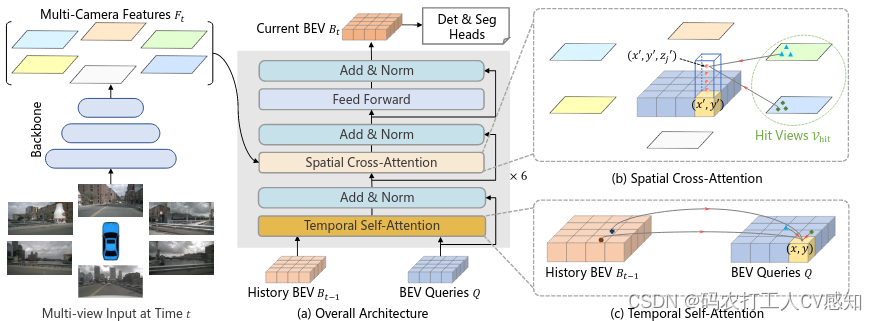
图2
BEVFormer的编码层包含网格状的BEV查询、时间自我注意和空间交叉注意。
在空间交叉注意中,每个BEV查询只与感兴趣区域的图像特征交互。
在时间自注意力中,每个BEV查询都与两个功能交互:当前时间戳的BEV查询和前一个时间戳的BEV功能。
3.配置环境详细参考源码,这里不一一阐述,在这里分享我配置过程中的问题及解决方法
- 报错:No module named 'tools' 分析:绝对路径没有识别到
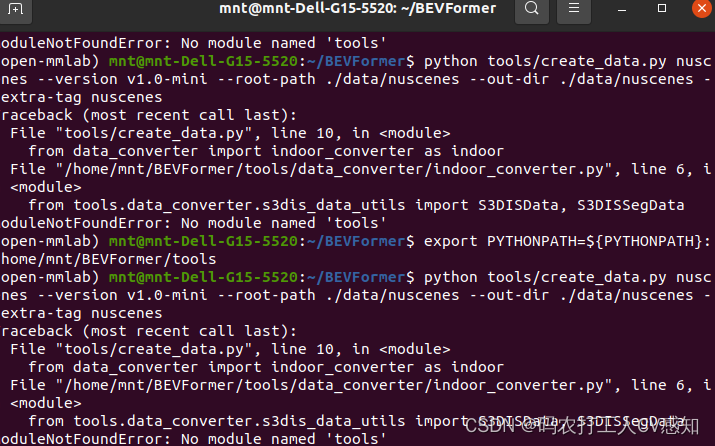
- 解决:export PYTHONPATH=${PYTHONPATH}:/home/mnt/mmdetection3d/BEVFormer/tools
- source ~/.profile
在终端执行:python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0 --canbus ./data
若生成下图所示结果表明数据处理正确
4.实验结果,demo展示
nuScense包含1000个,每个约20s的数据,标注2Hz,每个样本包含6个摄像机具有360度的水平场景。对于目标检测任务有标注了1.4M个3D框,共包含10个类别。5种评价标准:ATE, ASE, AEO, AVE, AAE,另外,nuScense还提出了NDS来计算综合评分。
BEV特征能够被用于3D目标检测和地图语义分割任务上。 常用的2D检测网络,都可以通过很小的修改迁移到3D检测上。实验验证了使用相同的BEV特征同时支持3D目标检测和地图语义分割,实验表明多任务学习能够提升在3D检测上的效果。
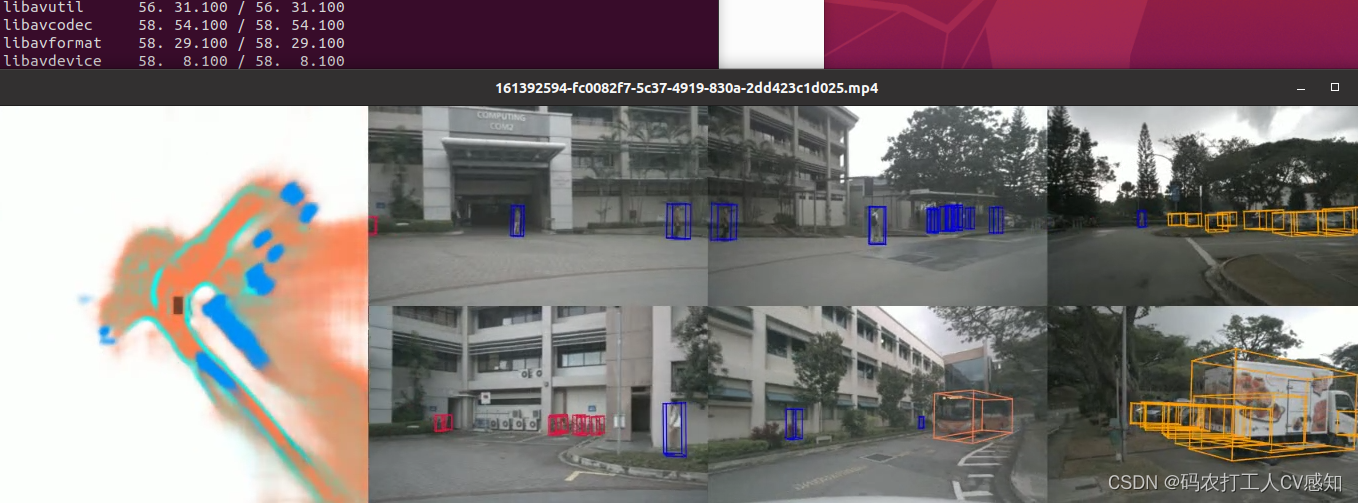



连续帧的视频demo:
 https://www.bilibili.com/video/BV16P411K7rp/
https://www.bilibili.com/video/BV16P411K7rp/写在最后:由于我的设施有限,训练数据有所减少,推荐大家最好在8个GPU上训练
回答:从视觉算法的角度来说,识别物体是否存在更多是语义层面的问题,这一过程依赖于训练数据,必然存在漏检、误检等错误。而通过 LiDAR 等设备从物理层面上识别物体的存在则更为可靠。此外,多尺度、小物体检测等视觉算法中存在的传统问题也会制约系统的性能。
具体流程大家可通过bilibili评论区询问,我会在评论区给大家解答,更多优质资料分享可通过本人CSDN公主号,大家关注后留言即可