资源Bilibili AV17649289
编译原理 哈尔滨工业大学 陈鄞
本次笔记内容:
1-1 什么是编译
1-2 编译系统的结构
1-3 词法分析
1-4 语法分析概述
1-5 语义分析概述
1-6 中间代码生成和编译器后端
文章目录
什么是编译
高级语言-汇编语言-机器语言
计算机语言分为:高级语言-汇编语言-机器语言。
其中:
- 机器语言(Machine Language):机器语言二进制,与人类表达习惯差距大;
- 汇编语言(Assembly Language):引入助记符概念,让机器语言更加直观。但是汇编语言依赖特定机器,且编写效率较低;
- 高级语言(High Level Language):更加简洁,类似数学定义。
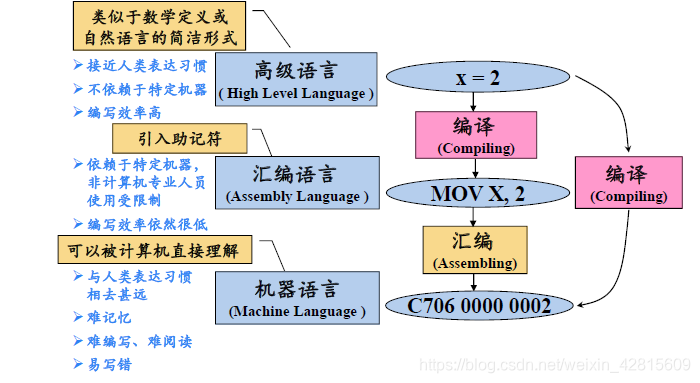
如上图,编译是一个“翻译为机器语言的过程”。
编译过程

如上图,解释:
- 源程序可能被分为不同的模块放在不同文件中,预处理器(Preprocessor)就是将这些源程序聚合起来,并且转换宏为原始语句;
- 可重定位(Relocatable),就是汇编器(Assembler)生成的机器代码在内存中位置不是固定的;
- 起始位置+相对地址=绝对地址;
- 加载器(Loader),就是修改可重定位地址,将修改后的指令和数据放到内存中适当的位置。
- 大型程序经常被分成多个部分进行编译,因此,机器代码要与其他可重定位的目标程序or库文件进行链接。这个问题由连接器(Linker)解决。
- 同时,链接器要解决外部内存地址(一个文件引用另一个文件(外部)的代码或数据)问题。
编译系统的结构
用英语翻译类比编译器结构
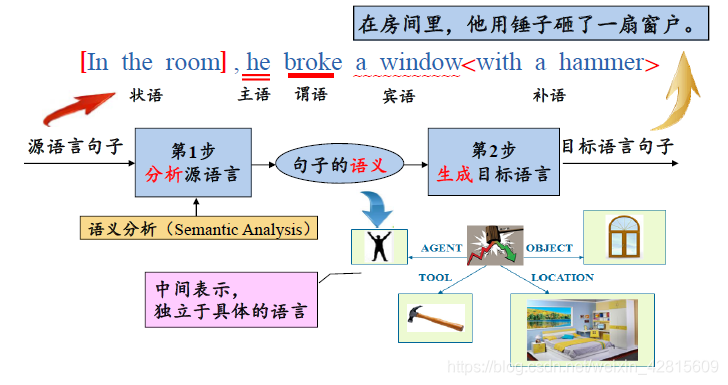
如上图,编译(高级语言至汇编/机器语言)这一过程可以类比人工翻译英汉。
句子描述了“打”这个动作,四个结点描述了四个实体(AGENT、OBJECT、TOOL、LOCATION)。
此四结点图是一种中间表示,独立于具体的原因(有了这个图,不管是英语、日语、法语,都可以进行表示)。

如上图:
- 首先进行词法分析(Lexical Analysis),得到词性;
- 再进行语法分析(Syntax Analysis),识别各类短语得到句子结构;
- 再进行语义分析(Semantic Analysis),根据句子的结构分析各个短语在句子中充当什么成分,并且分析动词同名词的关系。
编译器的结构

如上图,编译器逻辑组织方式分为三部分:
- 分析部分/前端(front end),与源语言相关;中间表示形式,独立于语言;
- 中间表示形式;
- 综合部分/后端(back end):与目标语言相关。
实现中,各部分常常连在一起。在语法分析时,结合句子规格,直接进行语义分析,这一技术叫语法制导翻译(Syntax Directed Translation)。
词法分析/扫描(Scanning)
- 从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型。
- 将识别出的单词转换成统一的机内表示——词法单元(token)形式
- token:< 种别码,属性值>

如上图,标识符、常量是开放的集合,因此对于标识符,都分配一个“码”,用属性值区分其不同值;而对于常量,每一个型一种“码”,用属性值区分不同值。

如上图,将while(){}输入,词法分析将输入的语句分为11个token。
那么,词法分析器将输入序列转换为token序列的具体过程是怎样的?第三章介绍。
语法分析(Parsing)
- 语法分析器(parser)从词法分析器输出的token序列中识别出各类短语,并构造语法分析树(parse tree);
- 语法分析树描述了句子的语法结构。

如上图,英语句子中的词性被识别,从而得到句子结构。
例子:赋值语句的分析树
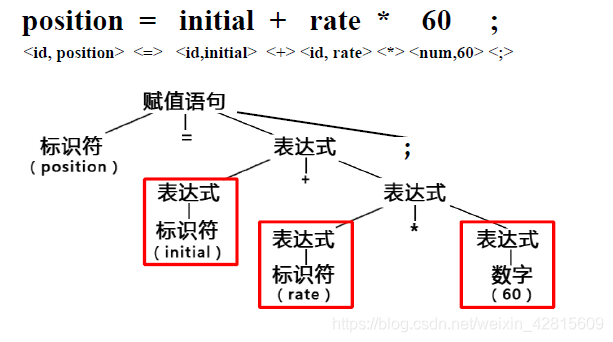
如上图,可以看出,一个标识符或者一个常数本身可以构成一个表达式,表达式组合,可以构成更大的表达式。
例子:变量声明语句的分析树

如上图,文法是一系列规则构成的。一个声明语句D是由一个类型T与一个标识符序列IDS、一个分号构成的。这里的T可以是int或real等;IDS可以是一个id,而一个IDS与id可以构成更大的IDS。
那么,语法分析器如何构造语法分析树的?第四章具体介绍。
语义分析
收集标识符的属性信息
语义分析的主要任务是收集标识符的属性信息:
- 种属(Kind),是简单变量还是复合变量等;
- 类型(Type);
- 存储位置、长度;
- 值;
- 作用域;
- 参数和返回值信息(包括参数个数、参数类型、参数传递方式、返回值类型等)。

如上图,存储位置、长度的存储包含相对地址等信息,与内存相关。

如上图,语义分析收集的属性信息放在符号表(Symbol Table)中。
每一个标识符都对应着符号表中的一条记录;符号表通常配备字符串表,NAME中就被分为两部分,第一部分是这个标识符的名称在字符串表中的起始位置,第二部分是长度。
语义检查
语义分析还要进行语义检查,包括:
- 变量或过程未经声明就使用
- 变量或过程名重复声明
- 运算分量类型不匹配
- 操作符与操作数之间的类型不匹配
-
- 数组下标不是整数
-
- 对非数组变量使用数组访问操作符
-
- 对非过程名使用过程调用操作符
-
- 过程调用的参数类型或数目不匹配
-
- 函数返回类型有误
中间代码生成
常见的中间表示形式有:
- 三地址码(Three-address Code),由类似于汇编语言的指令序列组成,每个指令最多有三个操作数(operand);
- 语法结构树/语法树(Syntax Tree),具体在后面结束。

常用的三地址指令如上图。
将三地址指令表示为数据结构有以下三种方法:
- 四元式(Quadruples),比如(op,y,z,x);
- 三元式(Triples);
- 间接三元式(Indirect triples)。

将前面的语句转换为四元式数据结构,如上图。
如上图,三地址指令与前面提到的“中间表示”有类似之处,唯一确定了运算完成顺序。
中间代码例子如下:

如上图,编译器将分析树生成中间代码。具体实现方式后续课程展开。
编译器后端
目标代码生成
- 目标代码生成以源程序的中间表示形式作为输入,并把它映射到目标语言;
- 目标代码生成的一个重要任务是为程序中使用的变量合理分配寄存器。
代码优化
- 为改进代码所进行的等价程序变换,使其运行得更快一些、占用空间更少一些,或者二者兼顾。
- 代码优化包括机器无关优化与机器相关代码优化。前者在中间代码层面,后者在目标代码层面。
