目录
本博客参考于
https://www.icourse163.org/learn/HIT-1002123007?tid=1450215473#/learn/content?type=detail&id=1214538561&sm=1
词法分析
正则表达式
正则表达式(Regular Expression,RE ) 是一种用来描述正则语言的
更紧凑的表示方法
例如
语言L={a}{a,b}({ε}*∪({.,_}{a,b}{a,b}***))
转换为正则表达式是
r = a(a|b)( ε |* (*.| _)(a|b)(a|b) )
正则表达式可以由较小的正则表达式按照特定规则递归地构建。每个正则表达式 r定义(表示)一个语言,记为L(r )。这个语言也是根据r 的子表达式所表示的语言递归定义的
正则表达式的定义
➢ ε是一个RE,L(ε) = {ε}
➢ 如果 a∈∑,则a是一个RE,L(a) = {a}
➢ 假设 r和 s都是 RE,表示的语言分别是 L(r)和L(s),则
➢ r|s 是一个RE,L( r|s ) = L(r)∪L(s)
➢ rs 是一个RE,L( rs ) = L(r) L(s)
➢ r* 是一个RE,L(r)= (L(r))
➢ (r) 是一个RE,L( (r) ) = L(r)
运算的优先级: *,连接, | (由高到低)
例
➢令 ∑ = {a, b},则
➢L(a|b) = L(a)∪L(b) ={a}∪{b} = {a, b}
➢ L((a|b)(a|b)) = L(a|b) L(a|b)={a, b}{a, b}= { aa, ab, ba, bb }
➢L(a) = (L(a))= {a}= { ε, a, aa, aaa*, . . . }**
➢L((a|b)) = (L(a|b)) = {a, b}= { ε, a**, b, aa, ab, ba, bb, aaa*, . . .}**
➢ L(a|ab) = { a, b, ab, aab, aaab*, . . .}
例子
C语言无符号整数的RE(正则表达式)
➢ 十进制整数的*RE*
➢(1|...|9)(0|...|9)*|0
➢ 八进制整数的RE
➢0(0|1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)*
➢ 十六进制整数的RE
➢0x(0|1|...|9|a|...| f |A|…|F)(0|...|9|a|...| f |A|…|F )*
正则语言
➢ 可以用RE定义的语言叫做
正则语言(regular language)或正则集合(regular set)
RE的代数定律
| 定律 | 描述 |
|---|---|
| r*|****s*** = *s*|*r* | |是可以交换的 |
| r*|( s*|t* )=( r*|s* )|t* | |是可结合的 |
| r*( s t*** )=( r s* )t* | 连接是可结合的 |
| r*( s*****|*****t*** )= r s*|****r*** t* ; ( s*|t* )r* = *s r*|t* r* | 连接对|是可分配的 |
| *εr* = *rε* = *r* | *ε* 是连接的单位元 |
| r * =( r|ε ) | 闭包中一定包含 *ε* |
| r*** = r* | * 具有幂等性 |
正则文法和正则表达式等价
➢ 对任何正则文法 G,存在定义同一语言的正则表达式 r
➢ 对任何正则表达式 r,存在生成同一语言的正则文法 G
正则定义
➢ 正则定义是具有如下形式的定义序列:
d1→r1
d2→r2
…
dn→rn
给一些RE命名,并在之后的RE中像使用字母表中的符号一样使用这些名字
其中:
➢ 每个di都是一个新符号,它们都不在字母表** Σ中,
而且各不相同
➢ 每个ri是字母表** Σ∪{d1 ,d2 , … ,di-1}上的正则表达式
例一
➢ digit → 0|1|2|…|9
➢ letter**_ → A|B|…|Z|a|b|…|z|_**
➢ id → letter(letter|digit)*
例二
(整型或浮点型)无符号数的正则定义
➢ digit → 0|1|2|…|9
➢ digits → digit digit*
➢ optionalFraction → .digits|ε
➢ optionalExponent → ( E(+|-|ε)digits )|ε
➢ number → digits optionalFraction optionalExponent
digit是数字
optionalFaction 可选择的小数部分
optionExponent 可选择的指数部分
number就是数字
2 2.15 2.15E+3 2.15E-3 2.15E3 2E-3
有穷自动机
➢ 有穷自动机 ( Finite Automata,FA )**由两位神经物理学家MeCuloch和Pitts于1948
年首先提出,是对一类处理系统建立的数学模型**
➢ 这类系统具有一系列离散的输入输出信息和有穷数目的 内部状态(状态:概括了对过去输入
信息处理的状况)
➢ 系统只需要根据当前所处的状态和当前面临的输入信息 就可以决定系统的后继行为。每当系统
处理了当前的输 入后,系统的内部状态也将发生改变
FA的典型例子
➢ 电梯控制装置
➢输入:顾客的乘梯需求(所要到达的层号)
➢状态:电梯所处的层数+运动方向
➢电梯控制装置并不需要记住先前全部的服务要 求,只需要知道电梯当前所处的状态以及还没 有满足的所有服务请求
FA模型
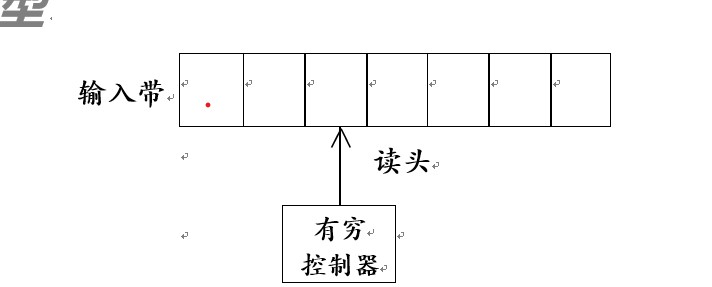
➢ 输入带(input tape):用来存放输入符号串
➢ 读头(head ):从左向右逐个读取输入符号,不能修改(只读)、
不能往返移动
➢ 有穷控制器( finite control ):具有有穷个状态数,根据当前的
状态和当前输入符号控制转入下一状态
FA的表示
➢ 转换图 (Transition Graph)
➢ 结点:FA的状态
➢ 初始状态(开始状态):只有一个,由start箭头指向
➢ 终止状态(接收状态):可以有多个,用双圈表示
带标记的有向边:如果对于输入a,存在一个从状态p到状 态q的转换,就在p、q之间画一条有向边,并标记上
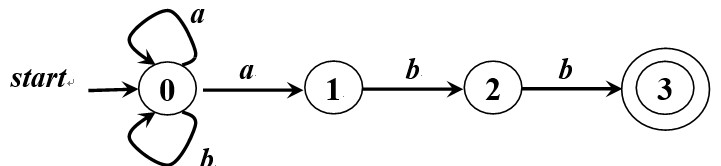
FA定义(接受)的语言
➢ 给定输入串x,如果存在一个对应于串x的从初始状态**
到某个终止状态的转换序列,则称串x被该FA接收
➢ 由一个有穷自动机M接收的所有串构成的集合称为是
该FA定义(或接收)的语言,记为L(M )
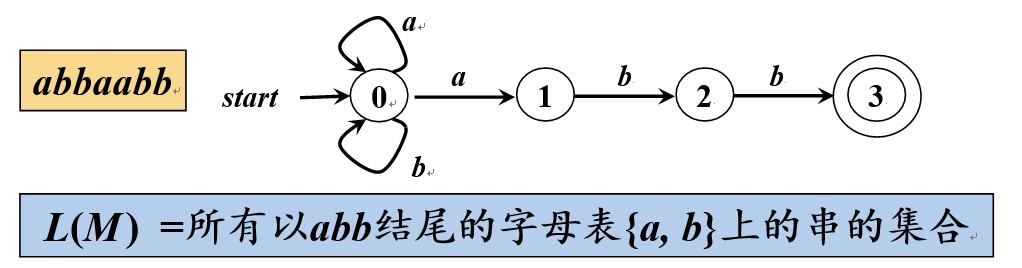
最长子串匹配原则
➢ 当输入串的多个前缀与一个或多个模式匹配时,
总是选择最长的前缀进行匹配
➢ 在到达某个终态之后,只要输入带上还有符号,
DFA就继续前进,以便寻找尽可能长的匹配
有穷自动机的分类
FA的分类
➢确定的FA (Deterministic finite automata, DFA)
➢非确定的FA (Nondeterministic finite automata, NFA)
确定的有穷自动机 ( DFA)
M = ( S,Σ ,*δ,s0,**F* )
➢S:有穷状态集
➢Σ:输入字母表,即输入符号集合。假设ε不是 Σ中的元素
➢δ:将S×Σ映射到S的转换函数。"s∈S, a∈Σ, δ(s,a)表示从状态s出发,沿着标记为a的边所能到达的状态。
➢s0:开始状态 (或初始状态),s0∈ S
➢F:接收状态(或终止状态)集合,F⊆ S
非确定的有穷自动机
➢S:有穷状态集
M = ( S,Σ ,δ,s0,F)
➢Σ:输入符号集合,即输入字母表。假设ε 不是Σ中的元素
➢δ:将S×Σ映射到2S的转换函数。"s∈S, a∈Σ, δ(s,a)表示从状态s出发,沿着标记为a的边所能到达的状态集合
➢s0:开始状态 (或初始状态),s0∈S
➢F:接收状态(或终止状态)集合,F⊆ S
DFA与NFA的等价性
➢ 对任何非确定的有穷自动机N ,存在定义同一语言
的确定的有穷自动机D
➢ 对任何确定的有穷自动机D ,存在定义同一语言的
非确定的有穷自动机N
➢ DFA和NFA可以识别相同的语言
带有“ε -边”的NFA
M = ( S,Σ ,δ,s0,F )
➢ S:有穷状态集
➢ Σ:输入符号集合,即输入字母表。假设ε不是Σ中的元素
➢ δ:将S×(Σ∪{ε})映射到2S的转换函数。"s∈S, a∈Σ∪{ε}, δ(s,a)
表示从状态s出发,沿着标记为a的边所能到达的状态集合
➢ s0:开始状态 (**或初始状态),*s**0*∈** S
➢ F:接收状态(或终止状态)集合,F⊆ S
从正则表达式到有穷自动机
RE-->NFA--->DFA
一般我们先把一个正则表达式转换为NFA然后在转换为DFA
根据RE构造NFA
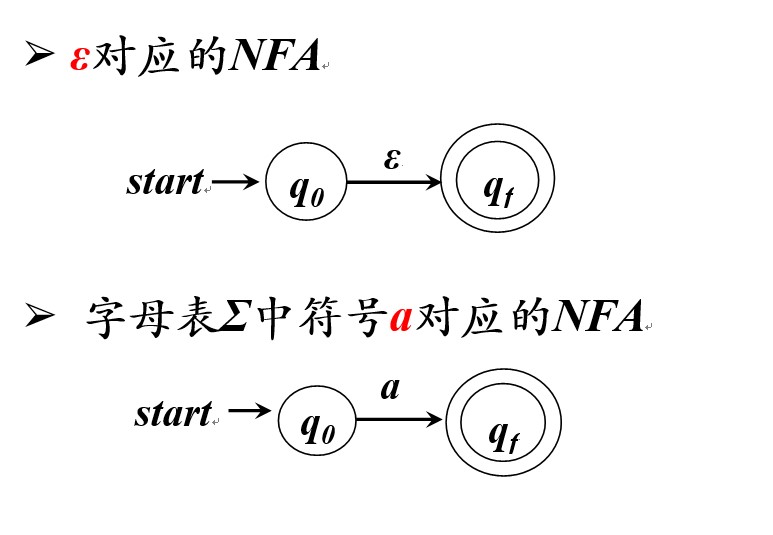
例子 r =( a | b ) * abb 对应的N FA
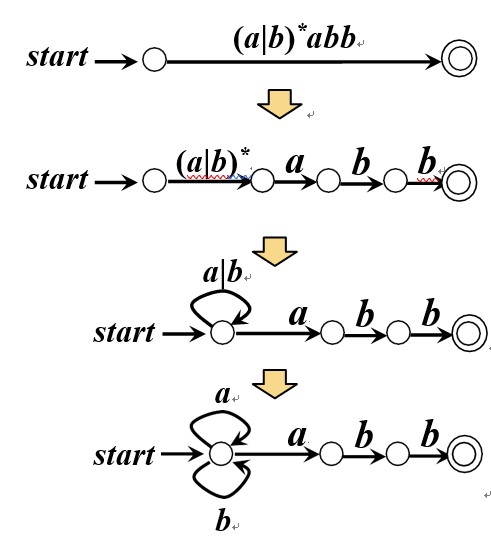
从N FA 到D FA 的转换
从NFA到DFA的转换
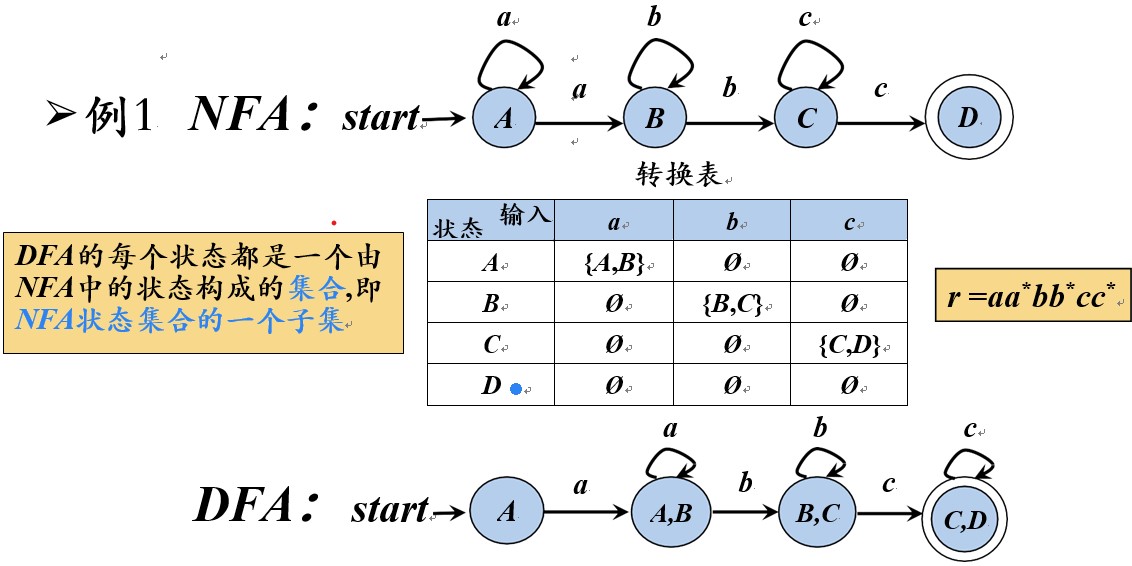
从带有 ε-边的 NFA到 DFA的
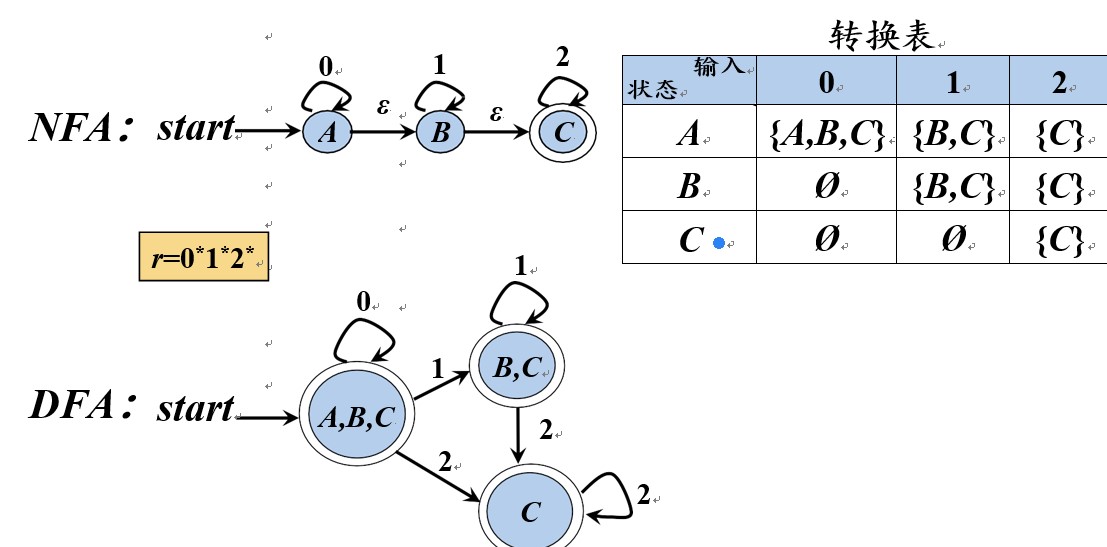
识别单词的D FA
识别无符号数的 DFA

词法分析阶段的错误处理
➢ 词法分析阶段可检测错误的类型
➢单词拼写错误
➢ 例:int i = 0x3G; float j =1.05e;
➢非法字符
➢ 例:~ @
➢ 词法错误检测
➢ 如果当前状态与当前输入符号在转换表对应项中的 信息为空,而当前状态又不是终止状态,则调用错误处理程序
错误处理
➢ 查找已扫描字符串中最后一个对应于某终态的字符
➢如果找到了,将该字符与其前面的字符识别成一个单词。 然后将输入指针退回到该字符,扫描器重新回到初始状态,继续识别下一个单词
➢如果没找到,则确定出错,采用错误恢复策略
错误回复策略
➢ 最简单的错误恢复策略:“恐慌模式 (panic mode)”恢复
➢从剩余的输入中不断删除字符,直到词法分析器能够在剩余输入的开头发现一个正确的字符为止