NFA的确定化
1. DFA、NFA的概念
有穷状态自动机根据确定性可以分为“确定有穷状态自动机”(DFA - Deterministic finite automaton)和“非确定有穷自动机”(NFA - Non-deterministic finite automaton)
- DFA,确定性有穷状态自动机:在输入一个状态时,只得到一个固定的状态
- NFA:“非确定有穷自动机”(NFA - Non-deterministic finite automaton),当输入一个字符或者条件得到一个状态机的集合
2. 为什么要将NFA确定化
DFA的确定性表现在转换函数f:SX2- >S是-一个单值函数,也就是说对任何状态k∈S,和输入符号a∈2,f(k,a)唯一 地确定了 下一个状态。
3. NFA与DFA的区别
DFA对于文本串里的每一个字符只需扫描一次,比较快,但特性较少;匹配速度与,确定
NFA要翻来覆去吃字符、吐字符,速度慢,但是特性丰富;匹配结果,不确定
区别:
- DFA比较快,但不提供Backtrack(回溯)功能,NFA比较慢,但提供了Backtrack功能。
- NFA是基于表达式的(Regex-Directed),而DFA是基于文本的(Text-Directed)。
- DFA引擎在任意时刻必定处于某个确定的状态,而NFA引擎可能处于一组状态之中的任何一个,所以,NFA引擎必须记录所有的可能路径(trace multiple possible routes through the NFA),NFA之所以能够提供Backtrack的功能,原因就在这里。
4. 什么是子集映射法
将NFA的一个状态子集在DFA中用一个状态表示出来。
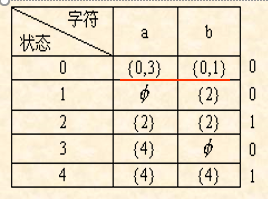
从NFA的矩阵表示中可以看出,表项通常是一一个状态的集合,而在DFA的矩阵表示中,表项是一个状态。
NFA到相应的DFA的构造的基本想法是让DFA的每个状态代表NFA的一个状态集合。
即在转换后的DFA中,使用它的状态去记录在NFA中读入一个输入符号后可能到达的所有状态。
换句话说,在得到的DFA中若输入符号串aa2-a后,到达某个状态,那么该状态表示对应的NFA的状态集的一个子集,这个子集是NFA在输入符号串a1a2–a后可以到达的那些状态组成的集合。
5. 三个重要运算
- 状态集E -闭包
- 状态集a弧转换
- 状态集a弧转换的必报Ia
6. NFA转换为DFA的具体步骤
- 构造的DFA的状态转换矩阵有几列,每列的含义
- 矩阵的第一行,第一列元素是什么?其余各行列如何填?
- 转换后DFA的初态,终态分别是什么?
- 算法是否收敛?为什么?
参考链接
DFA和NFA的区别
https://blog.csdn.net/cpucooler2011/article/details/50347303
DFA极简化和NFA确定化
https://blog.csdn.net/qwezhaohaihong/article/details/80705961