如上一篇博客所写MNIST是ML界的’hello world’,为了将自己的图像转化为类似MNIST数据文件类型的格式,先对它的文件进行了解析.先给出我的程序所提取的训练样本的前十张图像及对应的label,截图如下:
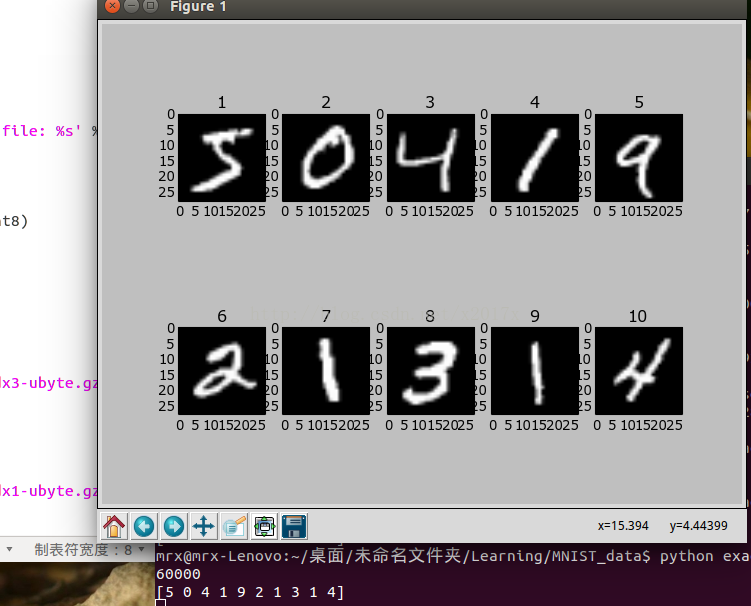
该数据格式是bytestream,无论是训练样本还是测试样本,其图像数据文件均在开头有一个2051的标志,之后便是图像的个数/行值/列值,紧接着按行读取所有的图像,且图像数据间无间隔;label数据文件均在开头有一个2049的标志,然后是图像的个数,以及每个图像的标志(如0,1)依次列出,以bytestream形式排列的文件在进行压缩,便是我们下载到的数据文件.
以下为文章开始给出的结果的源码:
#coding=utf-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import matplotlib.pyplot as plt
import gzip
import os
import Image
import tensorflow.python.platform
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
def extract_images(filename,nth):
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError(
'Invalid magic number %d in MNIST image file: %s' %
(magic, filename))
num_images = _read32(bytestream)
#print(num_images)
rows = _read32(bytestream)
cols = _read32(bytestream)
#print(rows)#28
#print(cols)#28
for i in range(nth-1):
bytestream.read(rows * cols)
buf = bytestream.read(rows * cols )
data = numpy.frombuffer(buf, dtype=numpy.uint8)#按行读取,图片间无间隔
data = numpy.reshape(data, (rows, cols))
return data
def extract_labels(filename, one_hot=False):
with gzip.open(filename) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError(
'Invalid magic number %d in MNIST label file: %s' %
(magic, filename))
num_items = _read32(bytestream)
print(num_items)
buf = bytestream.read(10)#num_items
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return dense_to_one_hot(labels)
return labels
if __name__=='__main__':
plt.figure(1)
for nth in range(1,11):
data = extract_images('train-images-idx3-ubyte.gz',nth)
new_im = Image.fromarray(data)
plt.subplot(2,5,nth)
plt.imshow(new_im, cmap ='gray')
plt.title(nth)
train_labels = extract_labels('train-labels-idx1-ubyte.gz', one_hot=False)
print(train_labels)
plt.show()