在用tensorflow跑实验的时候,我原本数据是用sqlite3存数据,然后再从数据库中选择相应的数据出来,但是这样太耗时了,于是便想要用tfrecord来存数据。于是通过mnist数据来试验一下。
先加载:
import tensorflow as tf
import numpy as np
import os
加载mnist数据库
首先先加载mnsit数据库,因为我已经下载好mnist数据库的压缩文件在"/home/jianyan/data/mnist"路径下了,关于tensorflow下载mnist数据库,可以参考这篇blog
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/home/jianyan/data/mnist", one_hot=True)
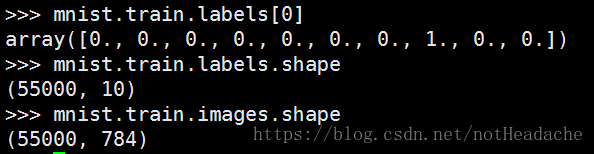
训练集包括55000个28×28像素的图像。这些784(28X28)像素值以单个维度向量的形式被平坦化。所有这样的55000个像素向量(每个图像一个)的集合被存储为numpy阵列的形式(55000,784),并被称为mnist.train.images。
这些55000个训练图像中的每一个与表示该图像属于的类的标签相关联。一共有10个这样的类(0,1,2 … 9)。标签以一种热编码形式的表示。因此标签被存储为numpy形状阵列的形式(55000,10)被称为mnist.train.labels。
存tfrecord
tfrecords_filename = "mnist.tfrecords"
if os.path.exists(tfrecords_filename):
os.remove(tfrecords_filename)
writer = tf.python_io.TFRecordWriter('./'+tfrecords_filename)
for i in range(1):
sample = mnist.train.images[i]
label = mnist.train.labels[i]
sample = sample.tostring()
label = label.tostring()
example = tf.train.Example(features=tf.train.Features(
feature={
'label': tf.train.Feature(bytes_list = tf.train.BytesList(value=[label])),
'sample':tf.train.Feature(bytes_list = tf.train.BytesList(value=[sample]))
}))
writer.write(example.SerializeToString())
writer.close()
读tfrecord
读tfrecord里面有多少条数据
tfrecords_filename = 'mnist.tfrecords'
count = 0
for r in tf.python_io.tf_record_iterator(tfrecords_filename):
count += 1
读tfrecord
filename_queue = tf.train.string_input_producer([tfrecords_filename],num_epochs=None) #读入流中
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.string),
'sample' : tf.FixedLenFeature([], tf.string),
})
img= tf.decode_raw(features['sample'],tf.float32)
img= tf.reshape(disk, [28,28])
label = tf.decode_raw(features['label'],tf.float64)
label = tf.reshape(label, [10])
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
sample, l = sess.run([img, label]) # 每次读一条数据
因为上面的代码只是读一次数据,那我们如果想一次读出batch_size的数据或者读出全部数据那怎么办呢?可以用下面的函数来实现:
def decode_from_tfrecords(filename_queue, is_batch, batch_size):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'label': tf.FixedLenFeature([], tf.string),
'sample' : tf.FixedLenFeature([], tf.string),
})
img= tf.decode_raw(features['sample'],tf.float32)
img= tf.reshape(disk, [28,28])
label = tf.decode_raw(features['label'],tf.float64)
label = tf.reshape(label, [10])
if is_batch:
min_after_dequeue = 10
capacity = min_after_dequeue+3*batch_size
img, label = tf.train.shuffle_batch([img, label],
batch_size=batch_size,
num_threads=3,
capacity=capacity,
min_after_dequeue=min_after_dequeue)
return img, label
通过 decode_from_tfrecords 函数,可以设置一次读多少数据:
# 每次随机读取读 batch_size=128 条数据送进去训练
filename_queue = tf.train.string_input_producer([tfrecords_filename],num_epochs=None) #读入流中
train_image, train_label = decode_from_tfrecords(filename_queue, True, 128)
# 一次性读完全部的数据
'''
tfrecords_filename = 'mnist.tfrecords'
count = 0
for r in tf.python_io.tf_record_iterator(tfrecords_filename):
count += 1
'''
filename_queue = tf.train.string_input_producer([tfrecords_filename],num_epochs=None) #读入流中
test_image_all, test_label_all = decode_from_tfrecords(filename_queue, True, count)
再用 sess.run 取数据即可。
注意:
原先数据是什么格式的,在读数据的时候也要设置成什么格式的,如:
img= tf.decode_raw(features['sample'],tf.float32) # 原先的数据是 float32
参考链接:
https://blog.csdn.net/happyhorizion/article/details/77894055
https://yq.aliyun.com/articles/202939